计算机组成原理
计算机系统概述
计算机组成原理总考纲
考纲内容
(一)计算机系统层次结构
计算机系统的基本组成;计算机硬件的基本组成;计算机软件的分类;计算机的工作过程
(二)计算机性能指标
吞吐量、响应时间、CPU时钟周期、主频、CPI、CPU执行时间
MIPS、MFLOPS、GFLOPS、TFLOPS、PFLOPS、EFLOPS、ZFLOPS
学习本章时,请读者思考以下问题:
1)计算机由哪几部分组成?以哪部分为中心?
2)主频高的CPU 一定比主频低的CPU快吗?为什么?
3)翻译程序、汇编程序、编译程序、解释程序有什么差别?各自的特性是什么?
4)不同级别的语言编写的程序有什么区别?哪种语言编写的程序能被硬件直接执行?请读者在学习本章的过程中寻找答案,本章末尾会给出参考答案。
| 缩写 | 全称 | 中译 |
|---|---|---|
| CPU | Central Processing Unit | 中央处理机(器) |
| IR | Instruction Register | 指令寄存器,存放当前正在执行的指令的寄存器; |
| CU | Control Unit | 控制单元(部件),控制器中产生微操作命令序列的部件,为控制器的核心部件; |
| ALU | Arithmetic Logic Unit | 算术逻辑运算单元,运算器中完成算术逻辑运算的逻辑部件; |
| ACC | Accumulator | 累加器,运算器中运算前存放操作数、运算后存放运算结果的寄存器; |
| MAR | Memory Address Register | 存储器地址寄存器,内存中用来存放欲访问存储单元地址的寄存器; |
| MQ | Multiplier-Quotient Register | 乘商寄存器,乘法运算时存放乘数、除法时存放商的寄存器。 |
| X | 此字母没有专指的缩写含义,可以用作任一部件名,在此表示$\color{green}{\text{操作数寄存器}}$,即运算器中工作寄存器之一,用来存放操作数; | |
| MDR | Memory Data Register | 存储器数据缓冲寄存器,主存中用来存放从某单元读出、或写入某存储单元数据的寄存器; |
| CPI | Clock cycle Per Instruction | 表示每条计算机指令执行所需的时钟周期 |
| I/O | Input/Output equipment | 输入/输出设备,为输入设备和输出设备的总称,用于计算机内部和外界信息的转换与传送; |
| PC | Program Counter | 程序计数器,存放当前欲执行指令的地址,并可自动计数形成下一条指令地址的计数器; |
| FLOPS | floating-point operations per second | 每秒所执行的浮点运算次数 |
| IX | IndexRegister | 变址寄存器(也许是为了和IR区分) |
| BR | Base Address Registers | 基址寄存器 |
| PSW | Program Status Word | 程序状态寄存器(程序状态字) |
| GPR | General Purpose Register | 通用寄存器组 |
*计算机发展历程
计算机硬件的发展
计算机的四代变化
从1946年世界上第一台电子数字计算机(Electronic Numerical Integrator And Computer,ENIAC)问世以来,计算机的发展已经经历了四代。
1)第一代计算机(1946-1957年)——电子管时代。特点:逻辑元件采用电子管;使用机器语言进行编程;主存用延迟线或磁鼓存储信息,容量极小;体积庞大,成本高;运算速度较低,一般只有几千次到几万次每秒。
2)第二代计算机(1958—1964年)—-晶体管时代。特点:逻辑元件采用晶体管;运算速
度提高到几万次到几十万次每秒;主存使用磁心存储器;软件开始使用高级语言,如FORTRAN,有了操作系统的雏形。
3)第三代计算机(1965-1971年)——中小规模集成电路时代。特点:逻辑元件采用中小
规模集成电路;半导体存储器开始取代磁心存储器;高级语言发展迅速,操作系统也进一步发展,开始有了分时操作系统。
4)第四代计算机(1972年至今)——超大规模集成电路时代。特点:逻辑元件采用大规模
集成电路和超大规模集成电路,产生了微处理器;诸如并行、流水线、高速缓存和虚拟存储器等概念用在了这代计算机中。
计算机元件的更新换代
1)摩尔定律。当价格不变时,集成电路上可容纳的晶体管数目,约每隔18个月便会增加一倍,性能也将提升一倍。也就是说,我们现在和 18个月后花同样的钱买到的CPU,后者的性能是前者的两倍。这一定律揭示了信息技术进步的速度。
2)半导体存储器的发展。1970 年,仙童半导体公司生产出第一个较大容量的半导体存储器,至今,半导体存储器经历了11 代:单芯片1KB、4KB、16KB、64KB、256KB、1MB、4MB、16MB、64MB、256MB和现在的1GB。
3)微处理器的发展。自1971年Intel公司开发出第一个微处理器Intel 4004至今,微处理器经历了Intel 8008(8位)、Intel 8080 (8位)、Intel 8086 ( 16位)、Intel 8088 ( 16位)、Intel 80286 ( 16位)、Intel 80386 (32位)、Intel 80486 (32位)、Pentium (32位)、Pentium pro (64位)、Pentium II (64位)、Pentium III (64位)、Pentium 4 (64位)等。这里的32位、64位指的是机器字长,是指计算机进行一次整数运算所能处理的二进制数据的位数。
计算机软件的发展
计算机软件技术的蓬勃发展,也为计算机系统的发展做出了很大的贡献。
计算机语言的发展经历了$\color{green}{\text{面向机器}}$的机器语言和汇编语言、$\color{green}{\text{面向问题}}$的高级语言。其中高级语言的发展真正促进了软件的发展,它经历了从科学计算和工程计算的FORTRAN、结构化程序设计的PASCAL 到面向对象的C++和适应网络环境的Java。
与此同时,直接影响计算机系统性能提升的各种系统软件也有了长足的发展,特别是操作系统,如Windows、UNIX、Linux 等。
计算机的分类与发展方向
通用计算机又分为巨型机、大型机、中型机、小型机、微型机和单片机6类,它们的体积、功耗、性能、数据存储量、指令系统的复杂程度和价格依次递减。
此外,计算机按指令和数据流还可分为:
1)单指令流和单数据流系统(SISD),即传统冯·诺依曼体系结构。
2)单指令流和多数据流系统(SIMD),包括阵列处理器和向量处理器系统。3)多指令流和单数据流系统(MISD),这种计算机实际上不存在。
4)多指令流和多数据流系统(MIMD),包括多处理器和多计算机系统。
计算机的发展趋势正向着“两极”分化:一极是微型计算机向更微型化、网络化、高性能、多用途方向发展;另一极是巨型机向更巨型化、超高速、并行处理、智能化方向发展。
计算机系统层次结构
计算机系统的组成
硬件系统和软件系统共同构成了一个完整的计算机系统。硬件是指有形的物理设备,是计算机系统中实际物理装置的总称。软件是指在硬件上运行的程序和相关的数据及文档。
计算机系统性能的好坏,很大程度上是由软件的效率和作用来表征的,而软件性能的发挥又离不开硬件的支持。对某一功能来说,其既可以用软件实现,又可以用硬件实现,则称为软硬件在逻辑上是等效的。在设计计算机系统时,要进行软/硬件的功能分配。通常来说,一个功能若使用较为频繁且用硬件实现的成本较为理想,则使用硬件解决可以提高效率。而用软件实现可以提高灵活性,但效率往往不如硬件实现高。
计算机硬件的基本组成
早期的冯·诺依曼机
冯·诺依曼在研究EDVAC机时提出了“存储程序”的概念,“存储程序”的思想奠定了现代计算机的基本结构,以此概念为基础的各类计算机通称为冯·诺依曼机,其特点如下:
1)计算机硬件系统由运算器、存储器、控制器、输入设备和输出设备5大部件组成。
2)指令和数据以同等地位存储在存储器中,并可按地址寻访。
3)指令和数据均用二进制代码表示。
4)指令由操作码和地址码组成,操作码指出操作的类型,地址码指出操作数的地址。
5)指令在存储器内按顺序存放。通常,指令是顺序执行的,在特定条件下可根据运算结果或根据设定的条件改变执行顺序。
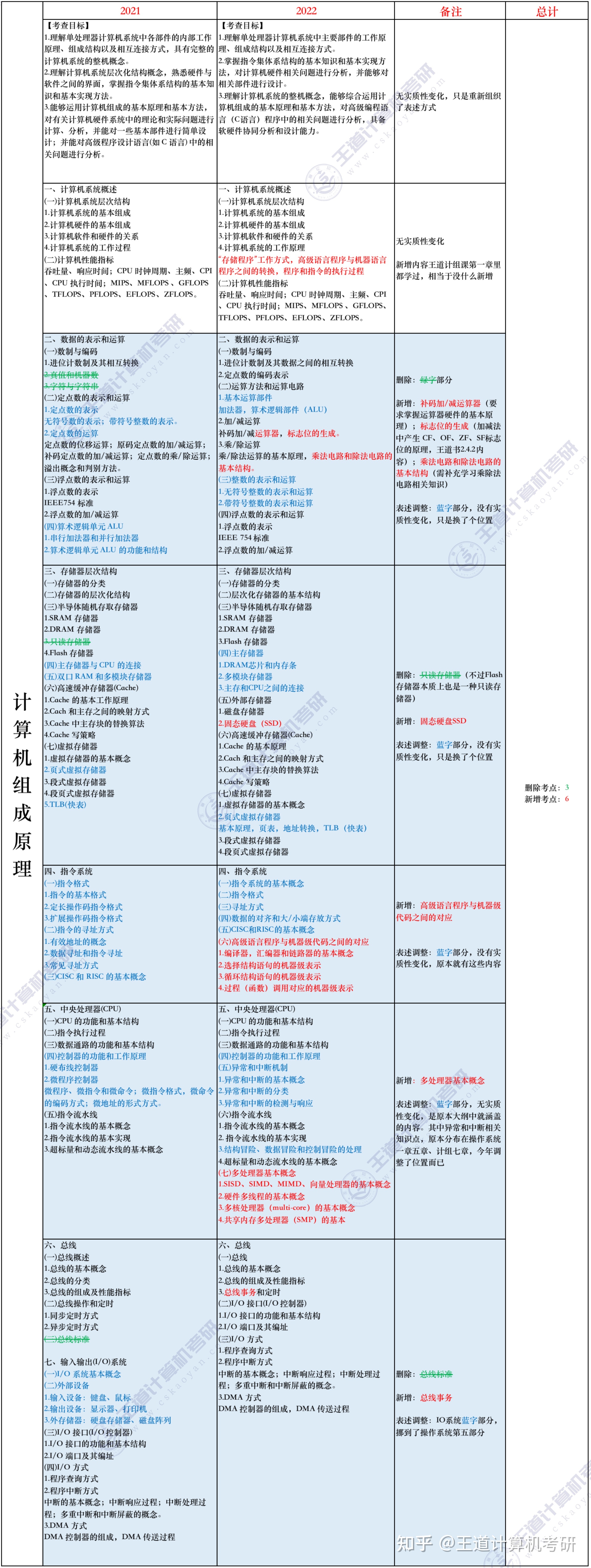
6)早期的冯·诺依曼机以运算器为中心,输入/输出设备通过运算器与存储器传送数据。典型的冯·诺依曼计算机结构如图1.1所示。
$\color{red}{\text{注意}}$:“$\color{red}{\text{存储程序}}$”的概念是指将指令以代码的形式事先输入计算机的主存储器,然后按其在存储器中的首地址执行程序的第一条指令,以后就按该程序的规定顺序执行其他指令,直至程序执行结束。
计算机按照此原理应该具有5大功能:数据传送功能(总线)、数据存储功能(存储器)、数据处理功能(运算器)、操作控制功能(控制器)、操作判断功能(PC)。
现代计算机的组织结构
在微处理器问世之前,运算器和控制器分离,而且存储器的容量很小,因此设计成以运算器为中心的结构,其他部件都通过运算器完成信息的传递,如图1.1所示。
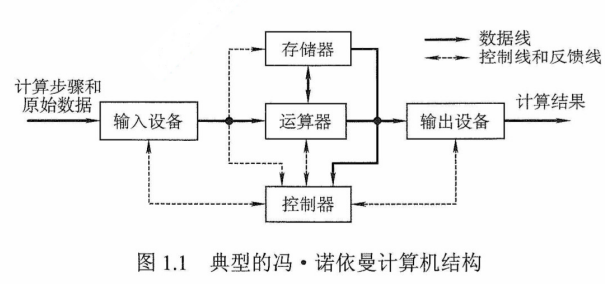
而随着微电子技术的进步,同时计算机需要处理、加工的信息量也与日俱增,大量IO设备的速度和CPU的速度差距悬殊,因此以运算器为中心的结构不能够满足计算机发展的要求。现代计算机已发展为以存储器为中心,使IO操作尽可能地绕过CPU,直接在IO设备和存储器之间完成,以提高系统的整体运行效率,其结构如图1.2所示。
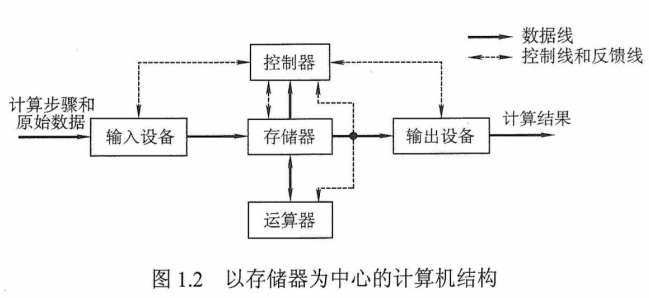
目前绝大多数现代计算机仍遵循冯·诺依曼的存储程序的设计思想。
计算机的功能部件
传统冯·诺依曼计算机和现代计算机的结构虽然有所不同,但功能部件是一致的,它们的功能部件包括如下几种。
(1)输入设备
输入设备的主要功能是将程序和数据以机器所能识别和接受的信息形式输入计算机。最常用也最基本的输入设备是键盘,此外还有鼠标、扫描仪、摄像机等。
(2)输出设备
输出设备的任务是将计算机处理的结果以人们所能接受的形式或其他系统所要求的信息形式输出。最常用、最基本的输出设备是显示器、打印机。计算机的输入/输出设备(简称IO 设备)是计算机与外界联系的桥梁,是计算机中不可缺少的重要组成部分。
(3)存储器
存储器是计算机的存储部件,用来存放程序和数据。
存储器分为主存储器(简称主存,也称内存储器)和辅助存储器(简称辅存,也称外存储器)。CPU 能够$\color{red}{\text{直接访问}}$的存储器是主存储器。辅助存储器用于帮助主存储器记忆更多的信息,$\color{red}{\text{辅助存储器}}$中的信息必须调入主存后,才能为CPU所访问。
主存储器的工作方式是按存储单元的地址进行存取,这种存取方式称为按地址存取方式($\color{green}{\text{相联存储器}}$是$\color{green}{\text{按内容}}$访问的)。
存储体的最基本组成如图1.3所示。存储体存放二进制信息,地址寄存器(MAR)存放访存地址,经过地址译码后找到所选的存储单元。数据寄存器(MDR)用于暂存要从存储器中读或写的信息,时序控制逻辑用于产生存储器操作所需的各种时序信号。
主存储器由许多存储单元组成,每个存储单元包含若干存储元件,每个存储元件存储一位二进制代码“0”或“1”。因此存储单元可存储一串二进制代码,称这串代码为存储字,称这串代码的位数为存储字长,存储字长可以是1B (8bit)或是字节的偶数倍。
$\color{green}{\text{MAR}}$用于寻址,其$\color{green}{\text{位数}}$对应着$\color{red}{\text{存储单元的个数}}$,如 MAR为10位,则有$2^{10}$= 1024个存储单元,记为1K。MAR的长度与PC的长度相等。
$\color{green}{\text{MDR}}$的$\color{green}{\text{位数}}$和$\color{red}{\text{存储字长}}$相等,一般为字节的二次幂的整数倍。
注意:MAR 与 MDR虽然是存储器的一部分,但在现代CPU中却是$\color{red}{\text{存在于}}$CPU中的;另外,后文提到的高速缓存(Cache)也存在于CPU 中。
(4)运算器
运算器是计算机的执行部件,用于进行算术运算和逻辑运算。算术运算是按算术运算规则进行的运算,如加、减、乘、除;逻辑运算包括与、或、非、异或、比较、移位等运算。
运算器的核心是算术逻辑单元(Arithmetic and Logical Unit,ALU)。运算器包含若干通用寄存器,用于暂存操作数和中间结果,如累加器(ACC)、乘商寄存器(MQ)、操作数寄存器(X)、变址寄存器(IX)、基址寄存器(BR)等,其中前3个寄存器是必须具备的。
运算器内还有程序状态寄存器(PSW),也称标志寄存器,用于存放ALU运算得到的一些标志信息或处理机的状态信息,如结果是否溢出、有无产生进位或借位、结果是否为负等。
(5)控制器
控制器是计算机的指挥中心,由其“指挥”各部件自动协调地进行工作。控制器由$\color{green}{\text{程序计数器(PC)}}$、$\color{green}{\text{指令寄存器(IR)}}$和$\color{green}{\text{控制单元(CU)}}$组成。
$\color{green}{\text{PC}}$用来存放当前$\color{green}{\text{欲执行指令}}$的$\color{green}{\text{地址}}$,可以自动加1以形成下一条指令的地址,它与主存的$\color{green}{\text{MAR}}$之间有一条直接通路。
$\color{green}{\text{IR}}$用来存放$\color{green}{\text{当前的指令}}$,其内容来自主存的 $\color{green}{\text{MDR}}$。指令中的操作码OP(IR)送至CU,用以分析指令并发出各种微操作命令序列;而地址码Ad(IR)送往MAR,用以取操作数。
一般将运算器和控制器集成到同一个芯片上,称为中央处理器(CPU)。CPU和主存储器共同构成主机,而除主机外的其他硬件装置(外存、I/O设备等)统称为外部设备,简称外设。
图1.4所示为冯·诺依曼结构的模型机。CPU包含ALU、通用寄存器组GPRs、标志寄存器、控制器、指令寄存器IR、程序计数器PC、存储器地址寄存器MAR和存储器数据寄存器MDR。图中从控制器送出的虚线就是控制信号,可以控制如何修改PC 以得到下一条指令的地址,可以控制ALU执行什么运算,可以控制主存是进行读操作还是写操作(读/写控制信号)。
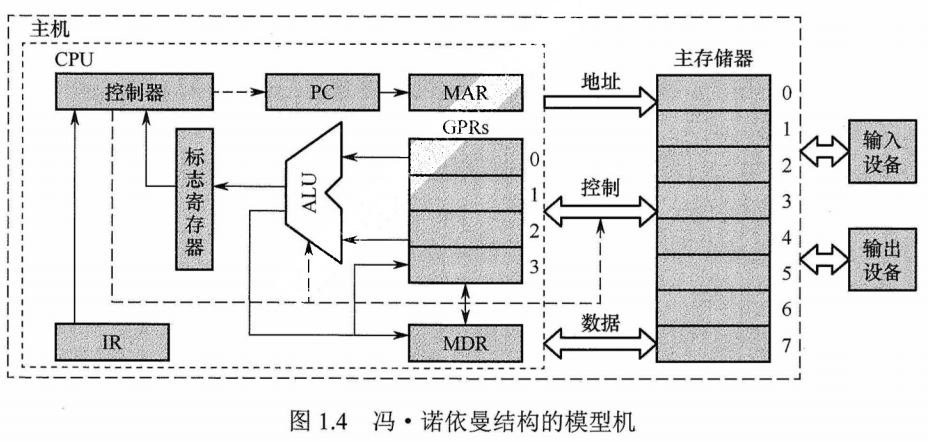
CPU和主存之间通过一组总线相连,总线中有地址、控制和数据3组信号线。MAR中的地址信息会直接送到地址线上,用于指向读/写操作的主存存储单元;控制线中有读/写信号线,指出数据是从CPU 写入主存还是从主存读出到CPU,根据是读操作还是写操作来控制将MDR中的数据是直接送到数据线上还是将数据线上的数据接收到MDR中。
计算机软件的分类
系统软件和应用软件
软件按其功能分类,可分为系统软件和应用软件。
系统软件是一组保证计算机系统高效、正确运行的基础软件,通常作为$\color{green}{\text{系统资源}}$提供给用户使用。系统软件主要有操作系统($\color{green}{\text{OS}}$)、数据库管理系统($\color{green}{\text{DBMS}}$)、语言处理程序、分布式软件系统、网络软件系统、标准库程序、服务性程序等。
应用软件是指用户为解决某个应用领域中的各类问题而编制的程序,如各种科学计算类程序、工程设计类程序、数据统计与处理程序等。
注意:$\color{green}{\text{数据库管理系统}}$(DBMS)和$\color{green}{\text{数据库系统}}$(DBS)是有区别的。DBMS是位于用户和操作系统之间的一层数据管理软件,是系统软件;而 DBS是指计算机系统中引入数据库后的系统,一般由数据库、数据库管理系统、数据库管理员(DBA)和应用系统构成。
dbs是dbms的超集 参考文献
三个级别的语言
1)机器语言。又称二进制代码语言,需要编程人员记忆每条指令的二进制编码。机器语言是计算机唯一可以直接识别和执行的语言。
2)汇编语言。汇编语言用英文单词或其缩写代替二进制的指令代码,更容易为人们记忆和理解。使用汇编语言编辑的程序,必须经过一个称为汇编程序的系统软件的翻译,将其转换为计算机的机器语言后,才能在计算机的硬件系统上执行。
3)高级语言。高级语言(如C、C++、Java等)是为方便程序设计人员写出解决问题的处理方案和解题过程的程序。通常高级语言需要经过编译程序编译成汇编语言程序,然后经过汇编操作得到机器语言程序,或直接由高级语言程序翻译成机器语言程序。
计算机的工作过程
计算机的工作过程分为以下三个步骤:
1)把程序和数据装入主存储器。
2)将源程序转换成可执行文件。
3)从可执行文件的首地址开始逐条执行指令。
从源程序到可执行文件
在计算机中编写的C语言程序,都必须被转换为一系列的低级机器指令,这些指令按照一种称为可执行目标文件的格式打好包,并以二进制磁盘文件的形式存放起来。
以UNIX系统中的GCC编译器程序为例,读取源程序文件 hello.c,并把它翻译成一个可执行目标文件hello,整个翻译过程可分为4个阶段完成,如图1.5所示。
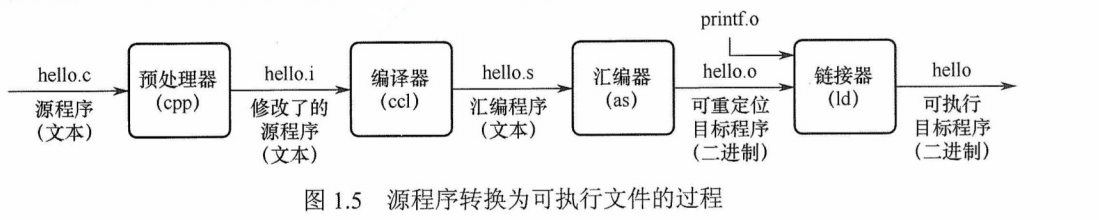
1)预处理阶段:预处理器(cpp)对源程序中以字符#开头的命令进行处理,例如将#include命令后面的.h文件内容插入程序文件。输出结果是一个以.i为扩展名的源文件hello.i.
2)编译阶段:编译器( ccl)对预处理后的源程序进行编译,生成一个汇编语言源程序hello.s。汇编语言源程序中的每条语句都以一种文本格式描述了一条低级机器语言指令
3)汇编阶段:汇编器(as)将hello.s翻译成机器语言指令,把这些指令打包成一个称为可重定位目标文件的hello.o,它是一种二进制文件,因此在文本编辑器中打开它时会显示乱码。
4)链接阶段:链接器(ld)将多个可重定位目标文件和标准库函数合并为一个可执行目标文件,或简称可执行文件。本例中,链接器将hello.o和标准库函数printf 所在的可重定位目标模块printf.o合并,生成可执行文件 hello。最终生成的可执行文件被保存在磁盘上。
指令执行过程的描述
程序中第一条指令的地址置于PC中,根据PC取出第一条指令,经过译码、执行步骤控制计算机各功能部件协同运行,完成这条指令的功能,并计算下一条指令的地址。用新得到的指令地址继续读出第二条指令并执行,直到程序结束为止。
指令的执行过程在第5章中详细描述。下面以取数指令(即将指令地址码指示的存储单元中的操作数取出后送至运算器的ACC中)为例进行说明,其信息流程如下:
1)取指令:PC→MAR→M→MDR→IR
根据PC取指令到IR。将PC的内容送MAR,MAR中的内容直接送地址线,同时控制器将读信号送读/写信号线,主存根据地址线上的地址和读信号,从指定存储单元读出指令送到数据线上,MDR从数据线接收指令信息,并传送到IR中。
2)分析指令:OP(IR)→CU
指令译码并送出控制信号。控制器根据R中指令的操作码,生成相应的控制信号送到不同的执行部件。在本例中,R中是取数指令,因此读控制信号被送到总线的控制线上。
3)执行指令:Ad(IR)→MAR→M→MDR→ACC
取数操作。将IR中指令的地址码送 MAR,MAR中的内容送地址线,同时控制器将读信号送读/写信号线,从主存指定存储单元读出操作数,并通过数据线送至MDR,再传送到ACC中。
此外,每取完一条指令,还须为取下一条指令做准备,形成下一条指令的地址,即(PC)+1→PC。
$\color{red}{\text{注意}}$:(PC)指程序计数器PC中存放的内容。PC→MAR应理解为(PC)→MAR,即程序计数器中的值经过数据通路送到MAR,也即$\color{red}{\text{表示数据通路时括号可省略}}$(因为只是表示数据流经的途径,而不强调数据本身的流动)。但$\color{red}{\text{运算时括号}}$不能省略,即(PC)+1→PC不能写为PC+1→PC。当题目中(PC)→MAR的括号未省略时,考生最好也不要省略。
计算机系统的多级层次结构
现代计算机是一个硬件与软件组成的综合体。由于面对的应用范围越来越广,因此必须有复杂的系统软件和硬件的支持。由于软/硬件的设计者和使用者从不同的角度、用不同的语言来对待同一个计算机系统,因此他们看到的计算机系统的属性对计算机系统提出的要求也就各不相同。
计算机系统的多级层次结构的作用,就是针对上述情况,根据从各种角度所看到的机器之间的有机联系,来分清彼此之间的界面,明确各自的功能,以便构成合理、高效的计算机系统。
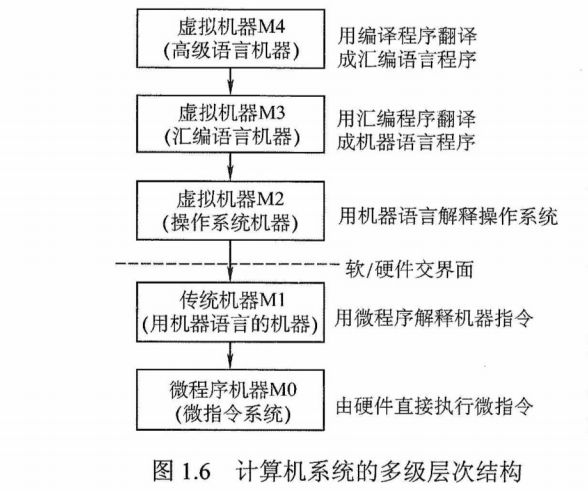
关于计算机系统层次结构的分层方式,目前尚无统一的标准,这里采用如图1.6所示的层次结构。
第1级是微程序机器层,这是一个实在的硬件层,它由机器硬件直接执行微指令。
第2级是传统机器语言层,它也是一个实际的机器层,由微程序解释机器指令系统。
第3级是操作系统层,它由操作系统程序实现。操作系统程序是由机器指令和广义指令组成的,这些广义指令是为了扩展机器功能而设置的,是由操作系统定义和解释的软件指令,所以这一层也称混合层。
第4级是汇编语言层,它为用户提供一种符号化的语言,借此可编写汇编语言源程序。这一层由汇编程序支持和执行。
在高级语言层之上,还可以有应用程序层,它由解决实际问题和应用问题的处理程序组成,如文字处理软件、数据库软件、多媒体处理软件和办公自动化软件等。
通常把没有配备软件的纯硬件系统称为“裸机”。第3层~第5层称为虚拟机,简单来说就是软件实现的机器。虚拟机只对该层的观察者存在,这里的分层和计算机网络的分层类似,对于某层的观察者来说,只能通过该层次的语言来了解和使用计算机,而不必关心下层是如何工作的。
层次之间的关系紧密,$\color{green}{\text{下层是上层的基础}}$,$\color{green}{\text{上层是下层的扩展}}$。随着超大规模集成电路技术的不断发展,部分软件功能将由硬件来实现,因而软/硬件交界面的划分也不是绝对的。
本门课程主要讨论传统机器M1和微程序机器MO的组成原理及设计思想。
计算机的性能指标
计算机的主要性能指标
机器字长
机器字长是指计算机进行一次整数运算(即定点整数运算)所能处理的二进制数据的位数,通常与CPU 的寄存器位数、加法器有关。因此,机器字长一般等于内部寄存器的大小,字长越长,数的表示范围越大,计算精度越高。计算机字长通常选定为字节(8位)的整数倍。
$\color{red}{\text{注意}}$:机器字长、指令字长和存储字长的关系(见本章常见问题和易混淆知识点4)。
数据通路带宽
数据通路带宽是指数据总线一次所能并行传送信息的位数。这里所说的数据通路宽度是指$\color{red}{\text{外部数据总线}}$的宽度,它与CPU$\color{green}{\text{内部的数据总线宽度}}$(内部寄存器的大小)有可能不同。
注意:各个子系统通过数据总线连接形成的数据传送路径称为$\color{green}{\text{数据通路}}$。
主存容量
主存容量是指主存储器所能存储信息的最大容量,通常以字节来衡量,也可用字数×字长(如512K×16位)来表示存储容量。其中,MAR的位数反映存储单元的个数,MAR的位数反映可寻址范围的最大值(而$\color{red}{\text{不一定是实际存储器的存储容量}}$)。
例如,MAR为16位,表示$2^{16}= 65536$,即此存储体内有65536个存储单元(可称为64K内存,1K=1024),若MDR为32位,表示存储容量为64K×32位。
运算速度
吞吐量和响应时间
- 吞吐量。指系统在单位时间内处理请求的数量。它取决于信息能多快地输入内存,CPU 能多快地取指令,数据能多快地从内存取出或存入,以及所得结果能多快地从内存送给一台外部设备。几乎每步都关系到主存,因此系统吞吐量主要取决于主存的存取周期。
- 响应时间。指从用户向计算机发送一个请求,到系统对该请求做出响应并获得所需结果的等待时间。通常包括CPU时间(运行一个程序所花费的时间)与等待时间(用于磁盘访问、存储器访问、IO操作、操作系统开销等的时间)。
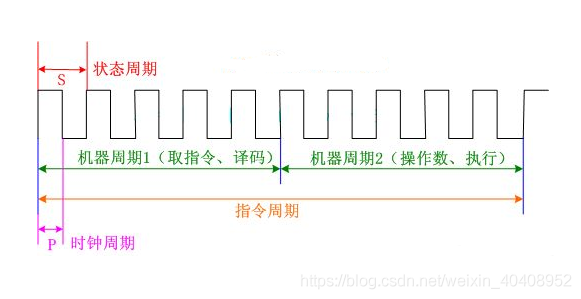
主频和CPU时钟周期
- CPU时钟周期。通常为节拍脉冲或T周期,即主频的倒数,它是CPU中最小的时间单位,执行指令的每个动作至少需要1个时钟周期。
- 主频(CPU时钟频率)。机器内部$\color{green}{\text{主时钟的频率}}$,是衡量机器速度的重要参数。对于同一个型号的计算机,其主频越高,完成指令的一个执行步骤所用的时间越短,执行指令的速度越快。例如,常用CPU的主频有1.8GHz、2.4GHz、2.8GHz等。
注意:CPU时钟周期=1/主频,主频通常以Hz(赫兹)为单位,1Hz表示每秒1次。
CPI (Clock cycle Per Instruction),即执行一条指令所需的时钟周期数。
不同指令的时钟周期数可能不同,因此对于一个程序或一台机器来说,其CPI 指该程序或该机器指令集中的所有指令执行所需的平均时钟周期数,此时CPI是一个平均值。
CPU执行时间,指运行一个程序所花费的时间
CPU执行时间= CPU时钟周期数/主频=(指令条数×CPI)/主频
上式表明,CPU 的性能(CPU执行时间)取决于三个要素:①主频(时钟频率);②每条指令执行所用的时钟周期数(CPI);③指令条数。
主频、CPI和指令条数是相互制约的。例如,更改指令集可以减少程序所含指令的条数,但同时可能引起CPU结构的调整,从而可能会增加时钟周期的宽度(降低主频)。
MIPS (Million Instructions Per Second),即每秒执行多少百万条指令
MIPS=指令条数(执行时间×$10^6$)=主频/(CPI×$10^6$)。
MIPS 对不同机器进行性能比较是有缺陷的,因为不同机器的指令集不同,指令的功能也就不同,比如在机器M1 上某条指令的功能也许在机器M2上要用多条指令来完成;不同机器的CPI和时钟周期也不同,因而同一条指合在不同机器上所用的时间也不同。
MFLOPS、GFLOPS、TFLOPS、PFLOPS、EFLOPS和 ZFLOPS.
MFLOPS (Mega Floating-point Operations Per Second),即每秒执行多少百万次浮点运算。MFLOPS=浮点操作次数/(执行时间×$10^6$)。
GFLOPS (Giga Floating-point Operations Per Second),即每秒执行多少十亿次浮点运算。GFLOPS= 浮点操作次数/(执行时间×$10^9$)。
TFLOPS (Tera Floating-point Operations Per Second),即每秒执行多少万亿次浮点运算。TFLOPS=浮点操作次数(执行时间×$10^{12}$)。
此外,还有PFLOPS=浮点操作次数(执行时间×$10^{15}$);EFLOPS = 浮点操作次数(执行时间×$10^{18}$);ZFLOPS=浮点操作次数(执行时间×$10^{21}$)。
注意:在描述$\color{green}{\text{存储容量}}$、文件大小等时,K、M、G、T通常用$\color{green}{\text{2的幂次}}$表示,如 1Kb =210b;在$\color{green}{\text{描述速率}}$、频率等时,k、M、G、T通常用$\color{green}{\text{10的幂次}}$表示,如 1kb/s = 10b/s。通常前者用大写的K,后者用小写的k,但其他前缀均为大写,表示的含义取决于所用的场景。
基准程序
基准程序(Benchmarks)是专门用来进行性能评价的一组程序,能够很好地反映机器在运行实际负载时的性能,可以通过在不同机器上运行相同的基准程序来比较在不同机器上的运行时间,从而评测其性能。对于不同的应用场合,应该选择不同的基准程序。
使用基准程序进行计算机性能评测也存在一些缺陷,因为基准程序的性能可能与某一小段的短代码密切相关,而硬件系统设计人员或编译器开发者可能会针对这些代码片段进行特殊的优化,使得执行这段代码的速度非常快,以至于得不到准确的性能评测结果。
几个专业术语
系列机
具有基本相同的体系结构,使用相同基本指令系统的多个不同型号的计算机组成的一个产品系列。
兼容
指计算机软件或硬件的通用性,即使用或运行在某个型号的计算机系统中的硬件/软件也能应用于另一个型号的计算机系统时,称这两台计算机在硬件或软件上存在兼容性。
软件可移植性
指把使用在某个系列计算机中的软件直接或进行很少的修改就能运行在另一个系列计算机中的可能性。
固件
将程序固定在ROM中组成的部件称为固件。固件是一种具有软件特性的硬件,固件的性能指标介于硬件与软件之间,吸收了软/硬件各自的优点,其执行速度快于软件,灵活性优于硬件,是软/硬件结合的产物。例如,目前操作系统已实现了部分固化(把软件永恒地存储于只读存储器中)。
本章小结
计算机由哪几部分组成?以哪部分为中心?
计算机由运算器、控制器、存储器、输入设备及输出设备五大部分构成,现代计算机通常把运算器和控制器集成在一个芯片上,合称为中央处理器。
而在微处理器面世之前,运算器和控制器分离,而且存储器的容量很小,因此设计成以运算器为中心的结构,其他部件都通过运算器完成信息的传递。
随着微电子技术的进步,同时计算机需要处理、加上的信总重世与口供增,人重o以代社速度和CPU 的速度差距悬殊,因此以运算器为中心的结构个能满足计算机反展的妥水。现1灯算机已经发展为以存储器为中心,使IO操作尽可能地绕过CPU,直接在IO 设备和存储器之间
完成,以提高系统的整体运行效率。
主频高的CPU一定比主频低的CPU快吗?为什么?
衡量CPU运算速度的指标有很多,不能以单独的某个指标来判断CPU的好坏。CPU的主频,即CPU内核工作的时钟频率。CPU 的主频表示CPU内数字脉冲信号振荡的速度,主频和实际的运算速度存在一定的关系,但目前还没有一个确定的公式能够定量两者的数值关系,因为CPU 的运算速度还要看CPU的流水线的各方面的性能指标(架构、缓存、指令集、CPU的位数、Cache 大小等)。由于主频并不直接代表运算速度,因此在一定情况下很可能会出现主频较高的CPU实际运算速度较低的现象。
翻译程序、汇编程序、编译程序、解释程序有什么差别?各自的特性是什么?
见常见问题和易混淆知识点2。
不同级别的语言编写的程序有什么区别?哪种语言编写的程序能被硬件直接执行?
机器语言和汇编语言与机器指令对应,而高级语言不与指令直接对应,具有较好的可移植性。其中机器语言可以被硬件直接执行。
常见问题和易混淆知识点
同一个功能既可以由软件实现又可以由硬件实现吗?
软件和硬件是两种完全不同的形态,硬件是实体,是物质基础;软件是一种信息,看不见、摸不到。但在逻辑功能上,软件和硬件是等效的。因此,在计算机系统中,许多功能既可以由硬件直接实现,又可以在硬件的配合下由软件实现。
例如,乘法运算既可用专门的乘法器(主要由加法器和移位器组成)实现,也可用乘法子程序(主要由加法指令和移位指令等组成)来实现。
翻译程序、汇编程序、编译程序、解释程序的区别和联系是什么?
翻译程序是指把高级语言源程序翻译成机器语言程序(目标代码)的软件。
翻译程序有两种:一种是编译程序,它将高级语言源程序一次全部翻译成目标程序,每次执行程序时,只需执行目标程序,因此只要源程序不变,就无须重新翻译,请注意同一种高级语言在不同体系结构下,编译成目标程序是不一样的,目标程序与体系结构相关,但仍不是计算机硬件能够直接执行的程序。另一种是解释程序,它将源程序的一条语句翻译成对应的机器目标代码,并立即执行,然后翻译下一条源程序语句并执行,直至所有源程序语句全部被翻译并执行完。所以解释程序的执行过程是翻译一句执行一句,并且不会生成目标程序。
汇编程序也是一种语言翻译程序,它把汇编语言源程序翻译为机器语言程序。汇编语言是一种面向机器的低级语言,是机器语言的符号表示,与机器语言一一对应。
编译程序与汇编程序的区别:若源语言是诸如C、C++、Java等“高级语言”,而目标语言是诸如汇编语言或机器语言之类的“低级语言”,则这样的一个翻译程序称为编译程序。若源语言是汇编语言,而目标语言是机器语言,则这样的一个翻译程序称为汇编程序。
什么是透明性?透明是指什么都能看见吗?
在计算机领域中,站在某类用户的角度,若感觉不到某个事物或属性的存在,即“看”不到某个事物或属性,则称为“对该用户而言,某个事物或属性是透明的”。这与日常生活中的“透明”概念(公开、看得见)正好相反。
例如,对于高级语言程序员来说,浮点数格式、乘法指令等这些指令的格式、数据如何在运算器中运算等都是透明的;而对于机器语言或汇编语言程序员来说,指令的格式、机器结构、数据格式等则不是透明的。
在CPU中,IR、MAR和 MDR对各类程序员都是透明的。
机器字长、指令字长、存储字长的区别和联系是什么?
机器字长:计算机能直接处理的二进制数据的位数,机器字长一般等于内部寄存器的大小,它决定了计算机的运算精度。
指令字长:一个指令字中包含的二进制代码的位数。
存储字长:一个存储单元存储的二进制代码的长度。它们都必须是字节的整数倍。
指令字长一般取存储字长的整数倍,若指令字长等于存储字长的2倍,则需要⒉次访存来取出一条指令,因此取指周期为机器周期的2倍;若指令字长等于存储字长,则取指周期等于机器周期。
早期的计算机存储字长一般和机器的指令字长与数据字长相等,因此访问一次主存便可取出一条指令或一个数据。随着计算机的发展,指令字长可变,数据字长也可变,但它们必须都是字节的整数倍。
请注意64位操作系统是指特别为64位架构的计算机而设计的操作系统,它能够利用64位处理器的优势。但64位机器既可以使用64位操作系统,又可以使用32位操作系统。而32位处理器是无法使用64位操作系统的。
计算机体系结构和计算机组成的区别和联系是什么?
计算机体系结构是指机器语言或汇编语言程序员所看得到的传统机器的属性,包括指令集、数据类型、存储器寻址技术等,大都属于抽象的属性。
计算机组成是指如何实现计算机体系结构所体现的属性,它包含对许多对程序员来说透明的硬件细节。例如,指令系统属于结构的问题,但指令的实现即如何取指令、分析指令、取操作数、如何运算等都属于组成的问题。因此,当两台机器指令系统相同时,只能认为它们具有相同的结构,至于这两台机器如何实现其指令,完全可以不同,即可以认为它们的组成方式是不同的。例如,一台机器是否具备乘法指令是一个结构的问题,但实现乘法指令采用什么方式则是一个组成的问题。
许多计算机厂商提供一系列体系结构相同的计算机,而它们的组成却有相当大的差别,即使是同一系列的不同型号机器,其性能和价格差异也很大。例如,IBM System/370结构就包了多种价位和性能的机型。
基准程序执行得越快说明机器的性能越好吗?
一般情况下,基准测试程序能够反映机器性能的好坏。但是,由于基准程序中的语句存在频度的差异,因此运行结果并不能完全说明问题。
字长总结
| 字长 | 解析 |
|---|---|
| 机器字长 | 是指数据运算的基本单位长度,是 $\color{green}{\text{计算机的位数}}$ ,与 $\color{green}{\text{数据总线}}$ 的位数一致 |
| 存储字长 | 一个存储单元中的二进制代码的位数, |
| 指令字长 | |
| 数据字长 | 数据总线一次能并行传送信息的位数,它可以不等于MDR的位数 |
| 操作系统的位数 | 操作系统可寻址的位数 |
周期总结
| 周期 | 解析 |
|---|---|
| 时钟周期 | 是最基本的时间单位,是计算机操作的最小单位时间 |
| 指令周期 | 取出并执行一条指令的时间称为指令周期 |
| 机器周期 | CPU 周期又称机器周期,它由多个时钟周期组成,是具有语义的一系列时钟周期 |
| CPU周期 | 同机器周期 |
| 中断周期 | 两次中断的间隔 |
| 存储周期 | 存取周期是指存储器进行两次独立的存储器操作(连续两次读或写操作)所需的最小间隔时间 |
图:周期总结
MISC
把频率理解为多少下(次)
数据的表示和运算
(一)数制与编码
进位计数制及其相互转换;真值和机器数;字符与字符串
(二)定点数的表示和运算
定点数的表示:无符号数的表示;有符号数的表示
定点数的运算:定点数的移位运算;原码定点数的加减运算;补码定点数的加减运算;定点数的乘/除运算;溢出概念和判别方法
(三)浮点数的表示和运算
浮点数的表示:IEEE 754标准;浮点数的加减运算
(四)算术逻辑单元(ALU)
串行加法器和并行加法器;ALU的功能和结构
本章内容较为繁杂,由于计算机中数的表示和运算方法与人们日常生活中的表示和不同,因此理解也较为困难。纵观近几年的真题,不难发现unsigned、short、int、long、float、double等在C语言中的表示、运算、溢出判断、隐式类型转换、强制类型转换、IEEE 754浮点数的表示,以及浮点数的运算,都是考研考查的重点,需要牢固掌握。
在学习本章时,请读者思考以下问题:
1)在计算机中,为什么要采用二进制来表示数据?
2)计算机在字长足够的情况下能够精确地表示每个数吗?若不能,请举例说明。3)字长相同的情况下,浮点数和定点数的表示范围与精度有什么区别?
4)用移码表示浮点数的阶码有什么好处?
请读者在本章的学习过程中寻找答案,本章末尾会给出参考答案。
比较不清晰的知识点:小数的表示(IEEE 754和浮点数),和加减乘除(原补)
数制与编码
进位计数制及其相互转换
在计算机系统内部,所有的信息都是用二进制进行编码的,这样做的原因有以下几点。
1)二进制只有两种状态,使用有两个稳定状态的物理器件就可以表示二进制数的每一位制造成本比较低,例如用高低电平或电荷的正负极性都可以很方便地表示0和1。
2)二进制位1和О正好与逻辑值“真”和“假”对应,为计算机实现逻辑运算和程序中的逻辑判断提供了便利条件。
3)二进制的编码和运算规则都很简单,通过逻辑门电路能方便地实现算术运算。
进位计数法
进位计数法是一种计数的方法。常用的进位计数法有十进制、二进制、八进制、十六进制等。十进制数是日常生活中最常使用的,而计算机中通常使用二进制数、八进制数和十六进制数。
在进位计数法中,每个数位所用到的不同数码的个数称为$\color{green}{\text{基数}}$。十进制的基数为10 (0~9),每个数位计满10就向高位进位,即“逢十进一”。
十进制数101,其个位的1显然与百位的1所表示的数值是不同的。每个数码所表示的数值等于该数码本身乘以一个与它所在数位有关的常数,这个常数称为$\color{green}{\text{位权}}$。一个进位数的数值大小就是它的各位数码按权相加。
一个$r$进制数($K_n K_{n-1}\cdots K_0 K_{-1}\cdots K_{-m}$)的数值可表示为
$K_nr^n + K_{n-1}r^{n-1} + \cdots + K_0r^0+\cdots + K_{-m}r^{-m} = \displaystyle \sum_{i=n}^{-m}K_ir^i$
式中,$r$是基数;$r^i$是第$i$位的位权(整数位最低位规定为第$0$位);$K$的取值可以是$0, 1, \cdots ,r-1$共r个数码中的任意一个。
二进制
计算机中用得最多的是基数为2的计数制,即二进制。二进制只有0和1两种数字符号,计数“逢二进一”。它的任意数位的权为2,i为所在位数。
八进制
八进制作为二进制的一种书写形式,其基数为8,有0~7共8个不同的数字符号,计数“逢八进一”。因为r = 8 = $2^3$,所以只要把二进制中的3位数码编为一组就是一位八进制数码,两者之间的转换极为方便。
十六进制。
十六进制也是二进制的一种常用书写形式,其基数为16,“逢十六进一”。每个数位可取0~9、A、B、C、D、E、F中的任意一个,其中A、B、C、D、E、F分别表示10~15。因为r = 16=$2^4$,因此4位二进制数码与1位十六进制数码相对应。
不同进制数之间的相互转换
二进制数转换为八进制数和十六进制数
对于一个二进制混合数(既包含整数部分,又包含小数部分),在转换时应以小数点为界。其整数部分,从小数点开始往左数,将一串二进制数分为3位(八进制)一组或4位(十六进制)一组,在数的最左边可根据需要加“0”补齐;对于小数部分,从小数户开炬仕石效,也付一串二进制数分为3位一组或4位一组,在数的最右边也可根据需要加“0”补齐。最终使总的位数为3或4的整数倍,然后分别用对应的八进制数或十六进制数取代。

所以,对应的八进制数为$(1702.32)_8$= $(1111000010.01101)_2$。
同样,由八进制数或十六进制数转换成二进制数,只需将每位改为3位或4位二进制数即可(必要时去掉整数最高位或小数最低位的0)。八进制数和十六进制数之间的转换也能方便地实现,十六进数制转换为八进制数(或八进制数转换为十六进制数)时,先将十六进制(八进制)数转换为二进制数,然后由二进制数转换为八进制(十六进制)数较为方便。
任意进制数转换为十进制数
将任意进制数的各位数码与它们的权值相乘,再把乘积相加,就得到了一个十进制数。这种方法称为按权展开相加法。
例如,$(11011.1)_2= 1×2^4+1×2^3+0×2^2+1×2^1+1×2^0+1×2^{-1}=27.5。$
十进制数转换为任意进制数
一个十进制数转换为任意进制数,常采用基数乘除法。这种转换方法对十进制数的整数部分和小数部分将分别进行处理,对整数部分用除基取余法,对小数部分用乘基取整法,最后将整数部分与小数部分的转换结果拼接起来。
除基取余法(整数部分的转换):整数部分除基取余,最先取得的余数为数的最低位最后取得的余数为数的最高位(即除基取余,先余为低,后余为高),商为0时结束。
整数部分:

小数部分:
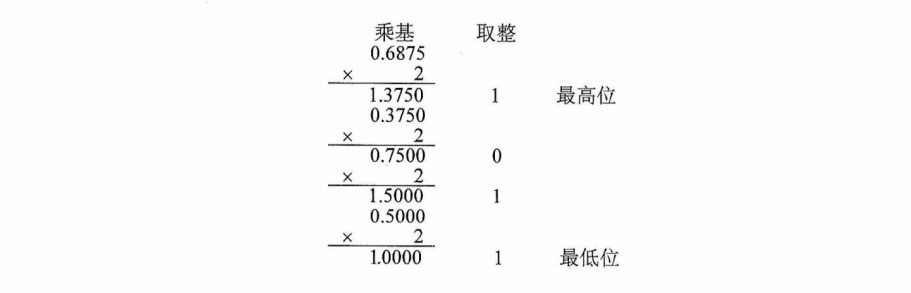
因此小数部分0.6875 =$(0.1011)_2$,所以123.6875=$(1111011.1011)_2$。
注意:在计算机中,小数和整数不一样,整数可以连续表示,但小数是离散的,所以并不是每个十进制小数都可以准确地用二进制表示。例如0.3,无论经过多少次乘二取整转换都无法得到精确的结果。但任意一个二进制小数都可以用十进制小数表示,希望读者引起重视。
注意:关于十进制数转换为任意进制数为何采用除基取余法和乘基取整法,以及所取之数放置位置的原理,请结合r进制数的数值表示公式思考,而不应死记硬背。
真值和机器数
在日常生活中,通常用正号、负号来分别表示正数(正号可省略)和负数,如+15、-8等。这种带“+”或“-”符号的数称为$\color{green}{\text{真值}}$。真值是机器数所代表的实际值。
在计算机中,通常采用数的符号和数值一起编码的方法来表示数据。常用的有原码、补码和反码表示法。这几种表示法都将数据的符号数字化,通常用“0”表示“正”,用“1”表示“负”。如0,101(这里的逗号“,”实际上并不存在,仅为区分符号位与数值位)表示+5。这种把符号“数字化”的数称为机器数。
*BCD码
二进制编码的十进制数(Binary-Coded Decimal,BCD)通常采用4位二进制数来表示一位十进制数中的0~9这10个数码。这种编码方法使二进制数和十进制数之间的转换得以快速进行。但4位二进制数可以组合出16种代码,因此必有6种状态为冗余状态。
8421码(最常用)
8421码(最常用)。它是一种有权码,设其各位的数值为b;,b,b, bo,则权值从高到低依次为8,4,2,1,它表示的十进制数为D= $8b_3,+ 4b_2+2b_1+ 1b_0$。如8→1000;9→1001。
若两个8421码相加之和小于等于$(1001)2$。即$(9){10}$,则不需要修正;若相加之和大于等于(1010),即(10)10,则要加6修正(从1010到1111这6个为无效码,当运算结果落于这个区间时,需要将运算结果加上 6),并向高位进位,进位可以在首次相加或修正时产生。
余3码。
这是一种无权码,是在8421码的基础上加$(0011)_2$形成的,因每个数都多余“3”,因此称为余3码。如8→1011;9→1100。
2421码。
这也是一种有权码,权值由高到低分别为2,4,2,1,特点是大于等于5的4位二进制数中最高位为1,小于5的最高位为0。如5→1011而非0101。
字符与字符串
由于计算机内部只能识别和处理二进制代码,所以字符都必须按照一定的规则用一组二进制编码来表示。
字符编码ASCII码
目前,国际上普遍采用的一种字符系统是7位二进制编码的 ASCII 码(每个字节的最高位保持为0,可用于传输时的奇偶校验位),它可表示10个十进制数码、52个英文大写字母和小写字母(A~Z,a~z)及一定数量的专用符号(如$、%、+、=等),共128个字符。
在 ASCII 码中,编码值0~31为控制字符,用于通信控制或设备的功能控制;编码值127是DEL码;编码值32是空格SP;编码值32~126共95个字符称为可印刷字符。
$\color{green}{\text{提示}}$:0
~9的 ASCII码值为48(011 0000 )~57 (011 1001 ),即去掉高3位,只保留低4位,正好是二进制形式的0~9。[65,90]=[A,Z],[97,122]=[a,z]
汉字的表示和编码
在1981年实施的国家标准GB 2312—1980 中,每个编码用两字节表示,收录了一级汉字3755个、二级汉字3008个、各种符号682个,共计7445个。
目前最新的汉字编码是2000年公布的国家标准GB 18030,它收录了27484个汉字。编码标准采用1B、2B和4B。
汉字的编码包括汉字的输入编码、汉字内码、汉字字形码三种,它们是计算机中用于输入、内部处理和输出三种用途的编码。区位码是国家标准局于1980年颁布、1981年实施的标准,它用两字节表示一个汉字,每字节用七位码,并将汉字和图形符号排列在一个94行94 列的二维代码表中。区位码是4位十进制数,前2位是区码,后2位是位码,所以称为区位码。
国标码将十进制的区位码转换为十六进制数后,再在每字节上加上 20H。国标码两字节的最高位都是0,ASCII 码的最高位也是0。为了方便计算机区分中文字符和英文字符,将国标码两字节的最高位都改为“1”,这就是汉字内码。
区位码和国标码都是输入码,它们和汉字内码的关系(十六进制)如下:
国标码=$\text{(区位码)}_{16}$+2020H
汉字内码=$\text{(国标码)}_{16}$+ 8080H
这一段话讲了和没讲是一样的
*校验码
校验码是指能够发现或能够自动纠正错误的数据编码,也称检错纠错编码。校验码的原理是通过增加一些冗余码,来检验或纠错编码。
通常某种编码都由许多码字构成,任意两个合法码字之间最少变化的二进制位数,称为数据校验码的$\color{green}{\text{码距}}$。对于码距不小于2的数据校验码,开始具有检错的能力。码距越大,检错、纠错的能力就越强,而且检错能力总是大于等于纠错能力。下面介绍3种常用的校验码(建议结合《计算机网络考研复习指导》第3章的“差错控制”章节进行综合复习)。
如1100和1101之间的码距为1,因为只有最低位翻转了。而1001和0010之间的码距则为3,因为只有1位没有变化。
奇偶校验
没什么好说的,只需注意奇偶数,中的奇偶指的是“1”的个数
码距为2,$\color{red}{\text{Q}}$:那么问题来了,其他校验方式的码距是多少
汉明码
按照书上的例子辅以参考文献记忆
把握一点:汉明码具有纠错一位的能力,检错两位
n为有效信息的位数,k为校验位的位数,n和k需要满足的关系:$n+k \leq 2^k-1$
汉明码的例子

CRC循环冗余校验
按照书上的例子辅以参考文献记忆
需要把握的点
模2除法相当于做异或运算
余数的位数一定要是比除数位数只能少一位,哪怕前面位是0,甚至是全为0(附带好整除时)也都不能省略
CRC循环冗余校验的例子

定点数的表示与运算
定点数的表示
无符号数和有符号数的表示
在计算机中参与运算的机器数有两大类:无符号数和有符号数。
1)无符号数。指整个机器字长的全部二进制位均为数值位,没有符号位,相当于数的绝对值。若机器字长为8位,则数的表示范围为0~$2^8-1$,即0~255。
2)有符号数。在机器中,数的“正”“负”号是无法识别的,有符号数用“O”表示“正”号,用“1”表示“负”号,从而将符号也数值化,并通常约定二进制数的最高位为符号位,即将符号位放在有效数字的前面,组成有符号数。
有符号数的机器表示有原码、补码、反码和移码。为了能正确区别真值和各种机器数,约定用X表示真值,用$\lbrack X \rbrack_{\text{原}}$表示原码,$\lbrack X \rbrack_{补}$表示补码,$\lbrack X \rbrack_{反}$表示反码,$\lbrack X \rbrack_{移}$表示移码。
机器数的定点表示
根据小数点的位置是否固定,在计算机中有两种数据格式:定点表示和浮点表示。本节仅介绍定点表示,浮点表示见2.3节。
定点表示即约定机器数中的小数点位置是固定不变的,小数点不再使用“.”表示,而是约定它的位置。理论上,小数点位置固定在哪一位都可以,但在计算机中通常采用两种简单的约定:将小数点的位置固定在数据的最高位之前,或固定在最低位之后。一般常称前者为定点小数,后者为定点整数。
定点小数
定点小数是$\color{green}{\text{纯小数}}$,约定小数点位置在符号位之后、有效数值部分最高位之前。若数据$X$的形式为$X=x_0.x_1x_2$(其中$x_0$为符号位,$x_1\backsim x_n$,是数值的有效部分,也称尾数,$x_1$为最高有效位),则在计算机中的表示形式如图2.4所示(设机器字长$n+1$位)。
当$x_0$=0,$x_1$~$x_n$均为1时,X为其所能表示的最大正数,真值等于$1-2^{-n}$。
当$x_0$=1,$x_1$~$x_n$,均为1时,X为其(原码)所能表示的最小负数,真值等于-$(1-2^{-n})$。
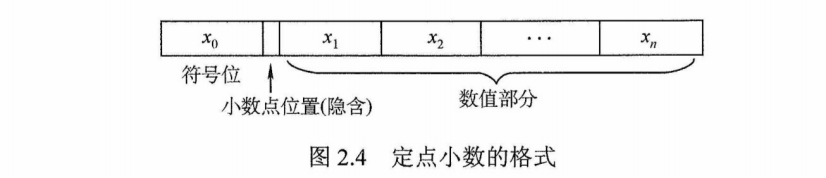
定点整数
定点整数是纯整数,约定小数点位置在有效数值部分最低位之后。若数据$X$的形式为$X=x_0x_1x_2 \cdots x_n$(其中$x_0$为符号位,$x_1 \backsim x_n$是尾数,$x_n$为最低有效位),则在计算机中的表示形式如图2.5所示(设机器字长n+1位)。
当$x_0=0, x_1 \backsim x_n$均为1是,$X$为其所能表示的最大正数,真值等于$2^n-1$。
当$x_0=1, x_1 \backsim x_n$均为1时,$X$为其(原码)所能表示的最小负数,真值等于$-(2^n-1)$
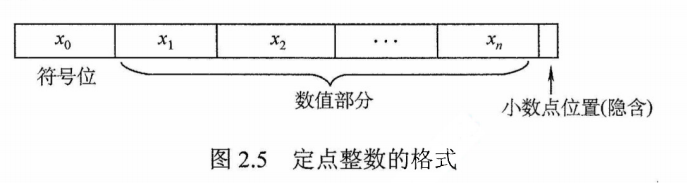
原码、补码、反码、移码
原码表示法
原码是一种比较简单、直观的机器数表示法,用机器数的最高位表示该数的符号,其余的各位表示数的绝对值。原码的定义如下。
- 纯小数的原码定义
$$
\lbrack x \rbrack_\text{原} = \begin{cases}
x, & 1 > x \geq 0 \cr
1-x=1+\lvert x \rvert , & 0 \geq x > -1
\end{cases}
\quad (\lbrack x \rbrack_\text{原}\text{是原码机器数,} x\text{是真值})
$$
例如,若$x_1=+0.1101,x2=-0.1101$字长为8位,则其原码表示为:$\lbrack x_1 \rbrack_\text{原}$ = $\color{green}{\text{0}}$.1101000,$\lbrack x_2 \rbrack_\text{原}$ = $\color{green}{\text{1}}$.1101000,其中最高位为符号位,则其原码表示为:$\lbrack x_1 \rbrack_\text{原}$ = $\color{green}{\text{0}}$.1101000,$\lbrack x_2 \rbrack_\text{原}$ = $\color{green}{\text{1}}$.1101000
更一般地,对于正小数$x=+0.x_1x_2\cdots x_n$,有$x_\text{原}=0.x_1x_2\cdots x_n$;对于负小数$x=-0.x_1x_2\cdots x_n$,有$x_\text{原}=1.x_1x_2\cdots x_n$
若字长为$n+1$,则原码小数的表示范围为$-(1-2^{-n}) \leq x \leq 1-2^{-n}$(关于原点对称)
- 纯整数的原码定义
$$
\lbrack x \rbrack_\text{原} = \begin{cases}
0,x, & 2^n > x \geq 0 \cr
2^n-x=2^n+\lvert x \rvert , & 0 \geq x > -2^n
\end{cases}
\quad (x^+\text{是真值},n\text{是整数位数})
$$
例如,若$x_1=+1110,x2=-1110$字长为8位,则其原码表示为:$\lbrack x_1 \rbrack_\text{原}$ = $\color{green}{\text{0}}$,0001110,$\lbrack x_2 \rbrack_\text{原}$ =$2^7 + 1110$ =$\color{green}{\text{1}}$,0001110,其中最高位为符号位
若字长为$n+1$,则原码小数的表示范围为$-(2^{n} -1) \leq x \leq 2^{n} -1$(关于原点对称)
真值零的原码表示有正零和负零两种形式,即$\lbrack +0 \rbrack_\text{原}=\color{green}{\text{0}}0000$和$\lbrack -0 \rbrack_\text{原}=\color{green}{\text{1}}0000$。
补码表示法
原码表示法的加减法操作比较复杂,对于两个不同符号数的加法(或同符号数的减法),先要比较两个数的绝对值大小,然后用绝对值大的数减去绝对值小的数,最后还要给结果选择合适的符号。而补码表示法中的加减法则统一采用加法操作实现。
- 纯小数的补码定义
$$
\lbrack x \rbrack_\text{补} = \begin{cases}
x, & 1 > x \geq 0 \cr
2+x=2-\lvert x \rvert , & 0 \geq x \geq -1
\end{cases}
\quad (mod \quad 2^{n+1 })
$$
例如,若$x_1=+0.1001,x2=-0.0110$字长为8位,则其补码表示为:$\lbrack x_1 \rbrack_\text{补}$ = $\color{green}{\text{0}}$.1001000,$\lbrack x_2 \rbrack_\text{补}$ = 2- 0.0110= $\color{green}{\text{1}}$.1010000,其中最高位为符号位
更一般地,对于正小数$x=+0.x_1x_2\cdots x_n$,有$x_\text{补}=0.x_1x_2\cdots x_n$;对于负小数$x=-0.x_1x_2\cdots x_n$,有$x_\text{补}=10.00\cdots0 - 0.x_1x_2\cdots x_n$(mod 2)
这里的mod2是什么意思?
若字长为$n+1$,则补码小数的表示范围为$-1 \leq x \leq 1-2^{-n}$(比原码多表示-1)
- 纯整数的补码定义
$$
\lbrack x \rbrack_\text{补} = \begin{cases}
0,x, & 2^n > x \geq 0 \cr
2^{n+1}+x=2^{n+1}-\lvert x \rvert , & 0 \geq x \geq -2^{n}
\end{cases}
\quad (mod \quad 2^{n+1 })
$$
例如,若$x_1=+1010,x2=-1101$字长为8位,则其补码表示为:$\lbrack x_1 \rbrack_\text{补}$ = $\color{green}{\text{0}}$,0001010,$\lbrack x_2 \rbrack_\text{补}$ =$2^8 - 0,0001101$ =$\color{green}{\text{1}}$,1110011。
若字长为$n+1$,则补码小数的表示范围为$-2^{n} \leq x \leq 2^{n} -1$(比原码多表示$-2^n$)
真值零的补码表示是唯一的。即$\lbrack +0 \rbrack_\text{补} = \lbrack -0 \rbrack_\text{补}=0.0000$,由定义$\lbrack +0 \rbrack_\text{补} = 10.0000 - 1.0000 = 1.0000$,可见对于小数,补码比原码多表示一个“-1”.类似地,对于整数,补码比原码多表示一个“$-2^n$”
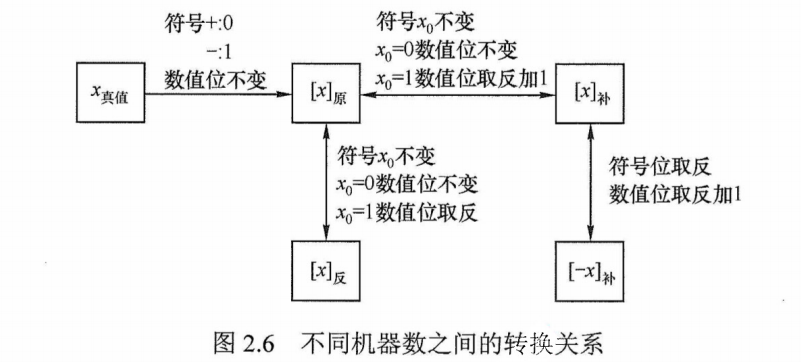
- 由原码求补码、由补码求原码
对于正数,补码与原码的表示相同,$\lbrack x \rbrack_\text{补} = \lbrack x \rbrack_\text{原}$。
对于负数,原码符号位不变,数值部分按位取反,末位加1(即所谓“取反加1”),此规则同样适用于由$\lbrack x \rbrack_\text{补}$求$\lbrack x \rbrack_\text{原}$
- 补码的算术移位
将$\lbrack x \rbrack_\text{补}$的符号位与数值位一起右移一位并保持原符号位的值不变,可实现除法功能(除以2)。
变形补码,又称模4补码,双符号位的补码小数,其定义为
$$
\lbrack x \rbrack_\text{补} = \begin{cases}
x, & 1 > x \geq 0 \cr
4+x=4-\lvert x \rvert , & 0 > x \geq -1
\end{cases}
\quad (mod \quad 4)
$$
模4补码双符号位00表示正,11表示负,用在完成算术运算的ALU部件中。
反码表示法
反码通常用来作为由原码求补码或由补码求原码的中间过渡。
- 纯小数的补码定义
$$
\lbrack x \rbrack_\text{反} = \begin{cases}
x, & 1 > x \geq 0 \cr
2-2^{-n} + x , & 0 \geq x \geq -1
\end{cases}
\quad (mod \quad 2 - 2^{n})
$$
例如,若$x_1=+0.0110,x2=-0.0110$字长为8位,则其反码表示为:$\lbrack x_1 \rbrack_\text{反}$ = $\color{green}{\text{0}}$.0110000,$\lbrack x_2 \rbrack_\text{反}$ = 1.1111111- 0.0110000= $\color{green}{\text{1}}$.100111。
若字长为$n+1$,则反码小数的表示范围为$-(1-2^{-n}) \leq x \leq 1-2^{-n}$(关于原点对称)。
真值零的反码表示不唯一,负数的反码符号位为“1”,数值部分求反,$\lbrack +0 \rbrack_\text{反}$ = 0.0000;$\lbrack -0 \rbrack_\text{反}$ = 1.1111。
- 纯整数的反码定义
$$
\lbrack x \rbrack_\text{反} = \begin{cases}
0,x, & 2^n > x \geq 0 \cr
(2^{n+1} - 1)+x, & 0 \geq x > -2^{n}
\end{cases}
\quad (mod \quad 2^{n+1 } -1)
$$
例如,若$x_1=+1011,x2=-1011$字长为8位,则其反码表示为:$\lbrack x_1 \rbrack_\text{反}$ = $\color{green}{\text{0}}$,0001011,$\lbrack x_2 \rbrack_\text{反}$ =$1,1111111 - 0,0001011$ =$\color{green}{\text{1}}$,1110100。
若字长为$n+1$,则反码小数的表示范围为$-(2^{n} - 1) \leq x \leq 2^{n} -1$(关于原点对称))
真值、原码、补码、反码及$\lbrack -x \rbrack_\text{反}$的转换规律,如图2.6所示。
移码表示法
移码常用来表示浮点数的$\color{green}{\text{阶码}}$。它只能表示$\color{green}{\text{整数}}$。
移码就是在真值$X$上加上一个常数(偏置值),通常这个常数取$2^n$,相当于$X$在数轴上向正方向偏移了若干单位,这就是“移码”一词的由来。移码定义为
$$
\lbrack x \rbrack_\text{移} = 2^n + x \quad(2^n > x \geq - 2^n,\text{其中机器字长为}n+1)
$$
例如,若整数$x_1 = +10101,x_2=-10101$,字长为8位,则其移码表示为:$\lbrack x_1 \rbrack_\text{移}=2^7 + 10101 = 1,0010101$;$\lbrack x_1 \rbrack_\text{移}=2^7+ (-10101)=0,1101011$
$\color{green}{\text{移码具有以下特点}}$:
- 移码中零的表示唯一,$\lbrack +0 \rbrack_\text{移} = 2^n + 0 = \lbrack -0 \rbrack_\text{移} = 2^n-0=100\cdots0$($n$个“0”)
- 一个真值的$\color{green}{\text{移码}}$和$\color{green}{\text{补码}}$仅差一个符号位,$\lbrack +0 \rbrack_\text{补}$的符号位取反即得$\lbrack +0 \rbrack_\text{移}$(“1”表示正,“0”表示负,这与其他机器数的符号位取值正好相反),反之亦然
- 移码全为0时,对应真值的最小值为$-2^n$;移码全为1时,对应真值的最大值$2^n01$。
- 移码保持了数据原有的大小顺序,移码大真值就大,移码小真值就小
定点数的运算
定点数的移位运算
移位运算根据操作对象的不同分为算术移位和逻辑移位。有符号数的移位称为算术移位,逻辑移位的操作对象是逻辑代码,可视为无符号数。
算术移位
算术移位的对象是有符号数,在移位过程中$\color{green}{\text{符号位}}$ $\color{green}{\text{保持不变}}$ 。
对于正数,由于$\lbrack x \rbrack_\text{原}$ = $\lbrack x \rbrack_\text{补}$ = $\lbrack x \rbrack_\text{反}$ = 真值,因此移位后出现的空位均以0添之。对于负数,由与原码,补码,反码的表示形式不同,因此当机器数移位时,对其空位的添补规则也不同
不论是正数还是负数,移位后其符号位均不变,且移位后都相当于对真值补0,根据补码、反码的特性,所以在负数时填补代码有区别。
对于原码,左移一位若不产生溢出,相当于乘以2(与十进制的左移一位相当于乘以10类似),右移一位,若不考虑因移出而舍去的末位尾数,相当于除以2。
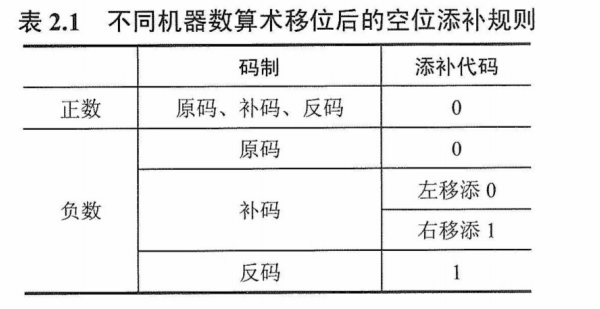
由表2.1可以得出如下结论。
正数的原码、补码与反码都相同,因此移位后出现的空位均以0 添之。对于负数,由于原码、补码和反码的表示形式不同,因此当机器数移位时,对其空位的添补规则也不同。
- 负数的原码数值部分与真值相同,因此在移位时只要使符号位不变,其空位均添0。
- 负数的反码各位除符号位外与负数的原码正好相反,因此移位后所添的代码应与原码相反,即全部添1。
- 分析由原码得到补码的过程发现,当对其由低位向高位找到第一个“1”时,在此“1”左边的各位均与对应的反码相同,而在此“1”右边的各位(包括此“1”在内)均与对应的原码相同。因此负数的补码左移时,因空位出现在低位,则添补的代码与原码相同,即添0;右移时因空位出现在高位,则添补的代码应与反码相同,即添1。
逻辑移位
逻辑移位将操作数视为无符号数,移位规则:逻辑左移时,高位移丢,低位添0;逻辑右移时,低位移丢,高位添0。
逻辑移位不管是左移还是右移,都添0。
循环移位分为带进位标志位CF的循环移位(大循环)和不带进位标志位的循环移位(小循环),过程如图2.7所示。
循环移位的主要特点是,移出的数位又被移入数据中,而是否带进位则要看是否将进位标志位加入循环位移。例如,带进位位的循环左移〔见图2.7(d)]就是数据位连同进位标志位一起左移,数据的最高位移入进位标志位CF,而进位位则依次移入数据的最低位。
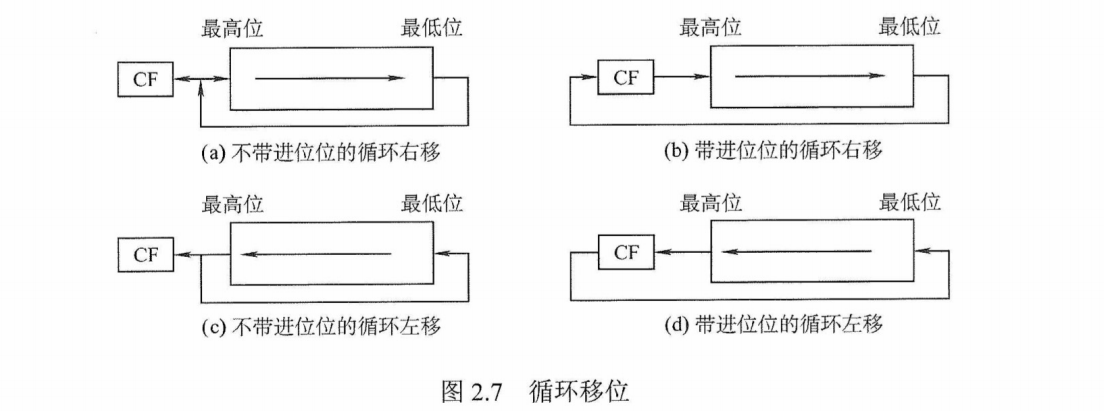
循环移位操作特别适合将数据的低字节数据和高字节数据互换。
原码定点数的加减法运算
设$\lbrack X \rbrack_\text{原}= x_s.x_1x_2\cdots x_n$和$\lbrack Y \rbrack_\text{原}= y_s.y_1y_2\cdots y_n$,进行加减运算的规则如下。
$\color{green}{\text{加法规则}}$:先判符号位,若相同,则绝对值相加,结果符号位不变;若不同,则做减法,绝对值大的数减去绝对值小的数,结果符号位与绝对值大的数相同。
$\color{green}{\text{减法规则}}$:两个原码表示的数相减,首先将减数符号取反,然后将被减数与符号取反后的减数按原码加法进行运算。
运算时注意机器字长,当左边位出现溢出时,将溢出位丢掉。
补码定点数加减法运算
补码加减运算规则简单,易于实现,因此计算机系统中普遍采用补码加减运算。补码运算的特点如下(设机器字长为$n+1$)。
1)参与运算的两个操作数均用补码表示。2)按二进制运算规则运算,逢二进一。
3)符号位与数值位按同样规则一起参与运算,符号位运算产生的进位要丢掉,结果的符号
位由运算得出。
4)补码加减运算依据下面的公式进行。当参加运算的数是定点小数时,模M= 2;当参加
运算的数是定点整数时,模$M=2^n+ 1$。
$$
\begin{cases}
\lbrack A+B \rbrack_\text{补} = \lbrack A \rbrack_\text{补} + \lbrack B \rbrack_\text{补}, &(mod M) \cr
\lbrack A-B \rbrack_\text{补} = \lbrack A \rbrack_\text{补} + \lbrack - B \rbrack_\text{补}, &(mod M), &
\end{cases}
$$
mod M运算是为了将溢出位丢掉。
也就是说,若做加法,则两数的补码直接相加;若做减法,则将被减数与减数的机器负数相加。
补码运算的结果亦为补码
设机器字长为8位(含1位符号位),A= 15,B=24,求$\lbrack A+B \rbrack_\text{补}$和$\lbrack A-B \rbrack_\text{补}$。
解:
A=+15=+0001111,B=+24=+0011000;得$\lbrack A \rbrack_\text{补}$= 00001111,$\lbrack B \rbrack_\text{补}$=00011000。
求得$\lbrack -B \rbrack_\text{补}$ = 11101000。所以
$\lbrack A+B \rbrack_\text{补}$=00001111+ 00011000 = 00100111,其符号位为0,对应真值为+39。
$\lbrack A-B \rbrack_\text{补}$=$\lbrack A \rbrack_\text{补} + \lbrack - B \rbrack_\text{补}$=00001111 + 11101000= 11110111,其符号位为1,对应真值为-9。
符号扩展
在计算机算术运算中,有时必须把采用给定位数表示的数转换成具有不同位数的某种表示形式。例如,某个程序需要将一个8位数与另外一个32位数相加,要想得到正确的结果,在将8位数与32位数相加之前,必须将8位数转换成32位数形式,这称为“符号扩展”。
正数的符号扩展非常简单,即原有形式的符号位移动到新形式的符号位上,新表示形式的所有附加位都用0进行填充。
负数的符号扩展方法则根据机器数的不同而不同。原码表示负数的符号扩展方法与正数相同,只不过此时符号位为1。补码表示负数的符号扩展方法:原有形式的符号位移动到新形式的符号位上,新表示形式的所有附加位都用1(对于整数)或0(对于小数)进行填充。反码表示负数的符号扩展方法:原有形式的符号位移动到新形式的符号位上,新表示形式的所有附加位都用1进行填充。
正数相当于位数往左边扩展,负数相当于位数往右边扩展
溢出概念和判别方法
溢出是指运算结果超过了数的表示范围。通常,称大于机器所能表示的最大正数为上溢,称小于机器所能表示的最小负数为下溢。定点小数的表示范围为$\lvert x \rvert <1$,如图2.8所示。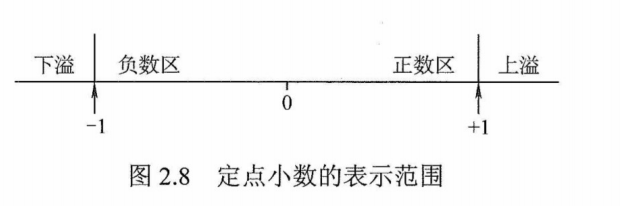
仅当两个符号相同的数相加或两个符号相异的数相减才可能产生溢出,如两个正数相加,而结果的符号位却为1(结果为负);一个负数减去一个正数,结果的符号位却为0(结果为正)。定点数加减运算出现溢出时,运算结果是错误的。
补码定点数加减运算溢出判断的方法有3种。
(1)采用一位符号位
由于减法运算在机器中是用加法器实现的,因此无论是加法还是减法,只要参加操作的两个数符号相同,结果又与原操作数符号不同,则表示结果溢出。
设A的符号为$A_s$,B的符号为$B_s$,运算结果的符号为$S_s$,则溢出逻辑表达式为
$$
V = A_sB_s\bar{S_s} + \bar{A_s}\bar{B_s}S_s
$$
若$V=0$,表示无溢出;若$V=1$,表示有溢出
(2)采用双符号位
双符号位法也称模4补码。运算结果的两个符号位$S_{s1}S_{s2}$相同,表示未溢出;运算结果的两个符号位$S_{s1}S_{s2}$不同,表示溢出,此时最高位符号位代表真正的符号。
符号位$S_{s1}S_{s2}$的各种情况如下:
- $S_{s1}S_{s2}=00$:表示结果为正数,无溢出。
- $S_{s1}S_{s2}=01$:表示结果正溢出。
- $S_{s1}S_{s2}=10$:表示结果负溢出。
- $S_{s1}S_{s2}=11$:表示结果为负数,无溢出。
Q:运算数的符号位在双符号位中表示是怎么样的?
A:正数00,负数11
溢出逻辑判断表达式为$V=S_{s1}\oplus S_{s2}$,若$V=0$,表示无溢出;若$V=1$表示有溢出。
(3)采用一位符号位根据数据位的进位情况判断溢出
若符号位的进位$C_s$与最高数位的进位$C_1$相同,则说明没有溢出,否则表示发生溢出。溢出逻辑判断表达式为V=$C_s\oplus C_1$,若V=0,表示无溢出;V=1,表示有溢出。
这是在干什么??
定点数的乘法运算
在计算机中,乘法运算由累加和右移操作实现。根据机器数的不同,可分为原码一位乘法和补码一位乘法。原码一位乘法的规则比补码一位乘法简单。
原码一位乘法
原码一位乘法的特点是符号位与数值位是分开求的,乘积符号由两个数的符号位“异或”形成,而乘积的数值部分则是两个数的绝对值相乘之积。
设$\lbrack X \rbrack_\text{原}= x_s.x_1x_2\cdots x_n$和$\lbrack Y \rbrack_\text{原}= y_s.y_1y_2\cdots y_n$,则运算规则如下:
- ${\textstyle\unicode{x2460}}$ 被乘数和乘数均取绝对值参加运算,符号位为$x_s \oplus y_s$
- ${\textstyle\unicode{x2461}}$ 部分积的长度同被乘数,取$n +1$位,以便存放乘法过程中绝对值大于等于1的值初值为0。
- ${\textstyle\unicode{x2462}}$ 从乘数的最低位$y_n$,开始判断:若$y_n = 1$,则部分积加上被乘数$\lvert x \rvert$,然后右移一位;若$y_n$= 0,则部分积加上0,然后右移一位。
- ${\textstyle\unicode{x2463}}$ 重复步骤${\textstyle\unicode{x2462}}$,判断$n$次
由于乘积的数值部分是两数绝对值相乘的结果,因此原码一位乘法运算过程中的右移操作均为逻辑右移。
注意:考虑到运算时可能出现绝对值大于1的情况(但此刻并非溢出),所以部分积和被乘数取$\color{green}{\text{双符号位}}$。
$\color{red}{\text{例}}$:设机器字长为5位(含1位符号位,n=4),x = —0.1101,y= 0.1011,采用原码一位乘法求x · y。

补码一位乘法(Booth 算法)
这是一种有符号数的乘法,采用相加和相减操作计算补码数据的乘积。
设$\lbrack X \rbrack_\text{补}= x_s.x_1x_2\cdots x_n$和$\lbrack Y \rbrack_\text{补}= y_s.y_1y_2\cdots y_n$,则运算规则如下:
- ${\textstyle\unicode{x2460}}$ 符号位参与运算,运算的数均以补码表示。
- ${\textstyle\unicode{x2461}}$ 被乘数一般取双符号位参与运算,部分积取双符号位,初值为0,乘数可取单符号位。
- ${\textstyle\unicode{x2462}}$ 乘数末位增设附加位.$y_{n+1}$,且初值为0。
- ${\textstyle\unicode{x2463}}$ 根据$(y_n,y_{n+1})$的取值来确定操作,见表2.2。
- ${\textstyle\unicode{x2464}}$ 移位按补码右移规则进行。
- ${\textstyle\unicode{x2465}}$ 按照上述算法进行$n+1$步操作,但第$n+1$步不再移位(共进行$n+1$次累加和$n$次右移),仅根据$y_n$,与$y_{n+1}$的比较结果做相应的运算。
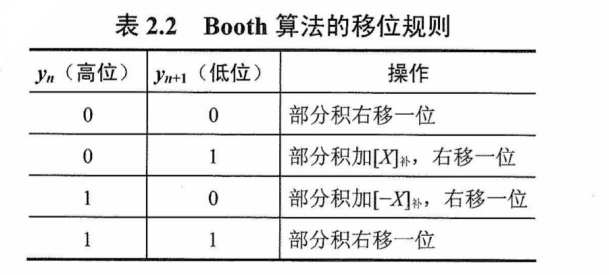
【例2.8】设机器字长为5位(含1位符号位,n = 4),x =—0.1101,y = 0.1011,采用Booth算法求x· y。

定点数的除法运算
在计算机中,除法运算可转换成“累加一左移”(逻辑左移),根据机器数的不同,可分为原码除法和补码除法。
如果恢复余数法,先减去这个除数,在判断够不够减,不够减需要恢复之前的余数,所以叫恢复余数法
不恢复余数法,会比恢复余数法效率高,(少了恢复余数的步骤
详见天勤视频
怎么判断一个运算是补码的运算还是原码的运算,只要看符号位参不参与运算,符号位参与运算那么就是补码运算;
符号位不参与运算那么就是原码运算,此时结果的符号位由运算数单独运算得到
(1)原码除法运算(不恢复余数法)
原码除法主要采用原码不恢复余数法,也称原码加减交替除法。特点是商符和商值是分开进行的,商符由两个操作数的符号位“异或”形成。求商值的规则如下。
设被除数$\lbrack X \rbrack_\text{原}= x_s.x_1x_2\cdots x_n$和$\lbrack Y \rbrack_\text{原}= y_s.y_1y_2\cdots y_n$,则
- ${\textstyle\unicode{x2460}}$ 商的符号:$Q_s = x_s \oplus y_s$
- ${\textstyle\unicode{x2461}}$ 商的数值:$\lvert Q \rvert = \lvert X \rvert / \lvert Y \rvert$
求$\lvert Q \rvert$的不恢复余数法运算规则如下。
- ${\textstyle\unicode{x2460}}$ 符号位不参与运算。
- ${\textstyle\unicode{x2461}}$ 先用被除数减去除数$\lvert X \rvert - \lvert Y \rvert = \lvert X \rvert + (- \lvert Y \rvert) = \lvert X \rvert + \lbrack -Y \rbrack_\text{补}$,当余数为正时,商上1,余数和商左移一位,再减去除数;当余数为负时,商上0,余数和商左移一位,再加上除数。
- ${\textstyle\unicode{x2462}}$ 当第$n+1$步余数为负时,需加上$\lvert Y \rvert$得到第n+1步正确的余数(余数和被除数同号)

数据都用补码表示,符号位参与运算;
初始时观察被除数与除数符号,同号做减法,异号做加法;
若余数与除数同号,则商1后余数左移一位减去除数,若余数与除数异号,则商0后余数左移一位加上除数;
重复上一步操作,直到得到n位商(n为数据位位数);
一般在末尾补上一个1。
摘自天勤
(2) 补码除法运算(加减交替法)
补码一位除法的特点是,符号位与数值位一起参加运算,商符自然形成。除法第一步根据被除数和除数的符号决定是做加法还是减法;上商的原则根据余数和除数的符号位共同决定,同号上商“1”,异号上商“0”;最后一步商恒置“1”。
加减交替法的规则如下:
${\textstyle\unicode{x2460}}$ 符号位参加运算,除数与被除数均用补码表示,商和余数也用补码表示。
${\textstyle\unicode{x2461}}$ 若被除数与除数同号,则被除数减去除数;若被除数与除数异号,则被除数加上除数。
${\textstyle\unicode{x2462}}$ 若余数与除数同号,则商上 1,余数左移一位减去除数;若余数与除数异号,则商上0,余数左移一位加上除数。
${\textstyle\unicode{x2463}}$ 重复执行第③步操作n次。
${\textstyle\unicode{x2464}}$ 若对商的精度没有特殊要求,则一般采用“末位恒置1”法。

(3)除法运算总结除法运算总结
C语言中的整数类型及类型转换
统考大纲要求考生具有对高级程序设计语言(如C语言)中相关问题进行分析的能力,而C语言变量之间的类型转换是统考中经常出现的题目,需要读者深入掌握这一内容.
short 16位
char 8 位(一般规定一个字节8位)
有符号数和无符号数的转换
C语言允许在不同的数据类型之间做强制类型转换,而从数学的角度来说,可以想到很多不同的转换规则。就用户使用而言,对于两者都能表示的数,当然希望转换过程中数值本身不发生任何变化,而那些转换过后无法表示的数呢?请先观察如下这段程序:
1 | int main(){ |
有符号数x是一个负数,而无符号数y的表示范围显然不包括x的值。读者可以自己猜想一下这段程序的运行结果,再比较下面给出的运行结果。
在采用补码的机器上,上述代码会输出如下结果:
$$x=—4321,y = 61215$$
最后的结果中,得到的y值似乎与原来的x没有一点关系。不过将这两个数化为二进制表示时,我们就会发现其中的规律,如表2.5所示。
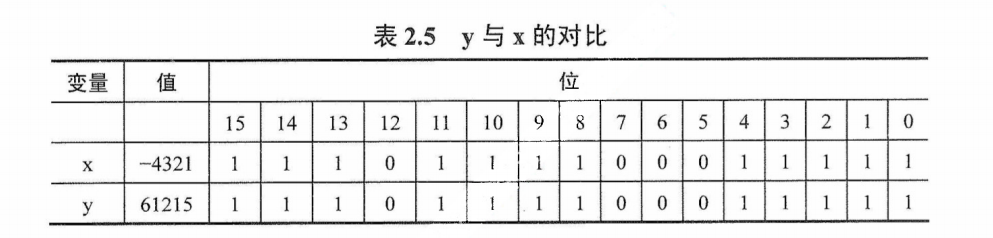
其中x为补码表示,y为无符号的二进制真值。观察可知,将short int强制转换为unsigned short只改变数值,而两个变量对应的每位都是一样的。通过这个例子就可以知道强制类型转换的结果保持位值不变,仅改变了解释这些位的方式。
下面再来看一个unsigned short型转换到short型的例子。考虑如下代码;
1 | int main(){ |
同样在采用补码的机器上,上述代码会输出以下结果:
$$x =65535,y =—1$$
同样可以把这两个数用之前的方法写成二进制,然后证实我们之前得出的结论。
不同字长整数之间的转换
另一种常见的运算是在不同字长的整数之间进行数值转换。先观察如下程序:
1 | int main(){ |
这段程序可以得到如下结果:
x=165537,y =-31071
u=-34991, v= 30545
其中x、y、u、v的十六进制表示分别为0x000286a1、0x86a1、0xff7751、0x7751,观察上述数字很容易得出结论,当大字长变量向小字长变量强制类型转换时,系统把多余的高位字长部分直接截断,低位直接赋值,因此也是一种保持位值的处理方法。
最后来看小字长变量向大字长变量转换的情况。先观察下面这段程序:
1 | int main(){ |
运行结果如下:
x=-4321,y =—4321
u=61215, v= 61215
x、y、u、v的十六进制表示分别是0xef1f、0xfffef1f、0xef1f、0x0000eflf,由本例可知短字长整数到长字长整数的转换,不仅要使相应的位值相等,高位部分还会扩展为原数字的符号位,这与之前的三个举例都不一样,从位值与数值的角度说,前三个举例的转换规则都是保证相应的位值相等,而短字长到长字长的转换,在位值相等的条件下还要补充高位的符号位,可以理解为数值的相等。注意,char类型为8位ASCII码整数,其转换为int时,在高位部分补0即可。
数据的存储和排列
数据的“大端方式”和“小端方式”存储
在存储数据时,数据从低位到高位可以按从左到右排列,也可以按从右到左排列。因此,无法用最左或最右来表征数据的最高位或最低位,通常用最低有效字节(LSB)和最高有效字节(MSB)来分别表示数的低位和高位。例如,在32位计算机中,一个int 型变量i的机器数为0123 4567H,其最高有效字节MSB= 01H,最低有效字节LSB=67H。
现代计算机基本上都采用字节编址,即每个地址编号中存放1字节。不同类型的数据占用的字节数不同,int和 float型数据占4字节,double型数据占8字节等,而程序中对每个数据只给定一个地址。假设变量i的地址为80 00H,字节01H、23H、45H、67H应该各有一个内存地址,那么地址08 00H对应4字节中哪字节的地址呢?这就是字节排列顺序问题。
多字节数据都存放在连续的字节序列中,根据数据中各字节在连续字节序列中的排列顺序不同,可以采用两种排列方式:大端方式(big endian)和小端方式(little endian),如图2.9所示。
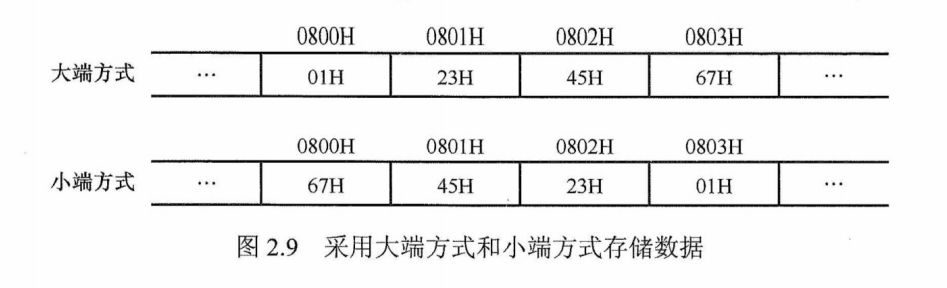
大端方式按从最高有效字节到最低有效字节的顺序存储数据,即最高有效字节存放在前面;小端方式按从最低有效字节到最高有效字节的顺序存储数据,即最低有效字节存放在前面。
在检查底层机器级代码时,需要分清各类型数据字节序列的顺序,例如以下是由反汇编器(汇编的逆过程,即将机器代码转换为汇编代码)生成的一行机器级代码的文本表示:
4004d3:01 05 64 94 04 08 add %eax,0x8049464
其中,“4004d3”是十六进制表示的地址,“01 05 43 0b 20 00”是指令的机器代码,“add %eax,Ox8049464”是指令的汇编形式,该指令的第二个操作数是一个立即数0x8049464,执行该指令时,从指令代码的后4字节中取出该立即数,立即数存放的字节序列为64H、94H、04H、08H,正好与操作数的字节顺序相反,即采用的是小端方式存储,得到08049464H
去掉开头的0,得到值0x8049464,在阅读小端方式存储的机器代码时,要注意字节是按相反顺序显示的。
数据按“边界对齐”方式存储
假设存储字长为32位,可按字节、半字和字寻址。对于机器字长为32位的计算机,数据以边界对齐方式存放,半字地址一定是2的整数倍,字地址一定是4的整数倍,这样无论所取的数据是字节、半字还是字,均可一次放存取出。所存储的数据不满足上述要求时,通过填充空白字节使其符合要求。这样虽然浪费了一些存储空间,但可提高取指令和取数的速度。
数据不按边界对齐方式存储时,可以充分利用存储空间,但半字长或字长的指令可能会存储在两个存储字中,此时需要两次访存,并且对高低字节的位置进行调整、连接之后才能得到所要的指令或数据,从而影响了指令的执行效率。
例如,“字节1、字节2、字节3、半字1、半字2、半字3、字1”的数据按序存放在存储器中,按边界对齐方式和不对齐方式存放时,格式分别如图2.10和图2.11所示。
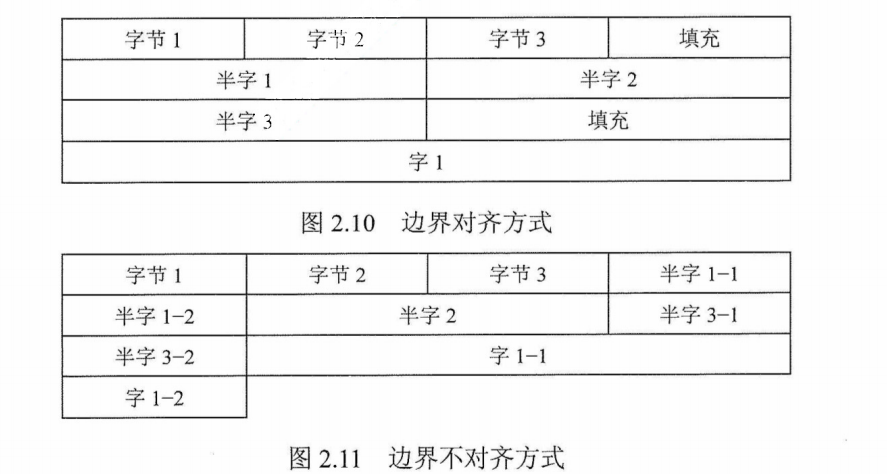
边界对齐方式相对边界不对齐方式是一种空间换时间的思想。RISC如ARM 采用边界对齐方式,而CISC如x86对齐和不对齐都支持。因为对齐方式取指令时间相同,因此能适应指令流水。
浮点数的表示与运算
补码运算的特点是符号位参与运算;原码运算的特点是,符号位先异或计算得出
浮点数的表示
浮点数表示法是指以适当的形式将比例因子表示在数据中,让小数点的位置根据需要而浮动。这样,在位数有限的情况下,既扩大了数的表示范围,又保持了数的有效精度。例如,用定点数表示电子的质量($9×10^{-28}$g)或太阳的质量($2×10^{33}g$)是非常不方便的。
浮点数的表示格式
通常,浮点数表示为
$$
N =r^E\times M
$$
式中,$r$时浮点数阶码的底,(隐含),与尾数的基数相同,通常$r=2$。$E$和$M$都是有符号的定点数,$E$称为阶码,$M$称为位数。可见浮点数由阶码和尾数两部分组成,如图2.12所示
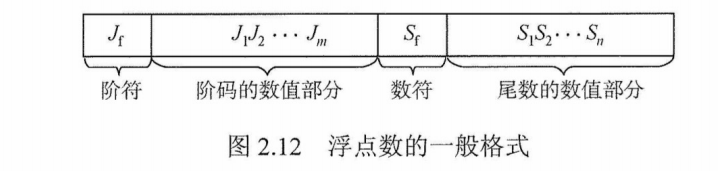
阶码是整数,阶符$J_f$和阶码的位数$m$共同反映浮点数的表示范围及小数点的实际位置;数符$S_f$代表浮点数的符号;尾数的位数$n$反映浮点数的精度。
规格化浮点数
为了提高运算的精度,需要充分地利用尾数的有效数位,通常采取浮点数规格化形式,即规定尾数的最高数位必须是一个有效值。非规格化浮点数需要进行规格化操作才能变成规格化浮点数。所谓规格化操作,是指通过调整一个非规格化浮点数的尾数和阶码的大小,使非零的浮点数在尾数的最高数位上保证是一个有效值。
左规:当浮点数运算的结果为非规格化时要进行规格化处理,将尾数算术左移一位、阶码减1(基数为2时)的方法称为左规,左归可能要进行多次。
右规:当浮点数运算的结果尾数出现溢出(双符号位为01或10)时,将尾数算术右移一位、阶码加1(基数为2时)的方法称为右规。需要右归时,只需进行一次。
规格化浮点数的尾数$M$的绝对值应满足条件$1/r \leq \lvert M \rvert \leq 1$。
1)原码规格化后。
正数为$0.1xx\cdots x$的形式,其最大值表示为$0.11\cdots1$,最小是表示为$0.100\cdots0$。
尾数表示的范围为$1/2 \leq M \leq (1-2^{-n})$。
负数为$1.1xx\cdots x$的形式,其最大值表示为$1.10\cdots0$,最小值表示为$1.11\cdots1$。
尾数的表示范围为$-(1 -2^{-n}) \leq M \leq -1/2$
2)原码规格化后。
正数为$0.1xx\cdots x$的形式,其最大值表示为$0.11\cdots1$,最小是表示为$0.100\cdots0$。
尾数表示的范围为$1/2 \leq M \leq (1-2^{-n})$。
负数为$1.0xx\cdots x$的形式,其最大值表示为$1.01\cdots1$,最小值表示为$1.00\cdots0$。
尾数的表示范围为$-1 \leq M \leq -(1/2 + 2^{-n})$
这里补码规格化尾数的最大负数形式为 $1.01\cdots1$,而不是原码的形式$1.10\cdots0$,因为$1.10\cdots0$不是补码规格化数,所以规格化尾数的最大负数时$-(0.10\cdots0 + 0.0\cdots01) = -0.10\cdots01,$而$(-0.10\cdots01)_\text{补}=1.01\cdots1$。
为什么$\dfrac{1}{2}$不是规格化浮点数:参考文献
当浮点数尾数的基数为2时,原码规格化数的尾数最高位一定是1,补码规格化数的尾数最高位一定与尾数符号位相反。基数不同,浮点数的规格化形式也不同。当基数为4时,原码规格化形式的尾数最高两位不全为0;当基数为8时,原码规格化形式的尾数最高3位不全为0。
*浮点数的表示范围
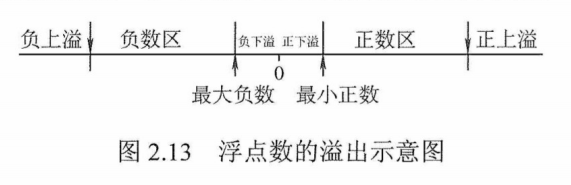
如图2.13所示,运算结果大于最大正数时称为正上溢,小于绝对值最大负数时称为负上溢,正上溢和负上溢统称上溢。数据一旦产生上溢,计算机必须中断运算操作,进行溢出处理。当运算结果在О至最小正数之间时称为正下溢,在0至绝对值最小负数之间时称为负下溢,正下溢和负下溢统称下溢。数据下溢时,浮点数值趋于零,计算机仅将其当作机器零处理。
IEEE 754标准
按照IEEE 754标准,常用的浮点数的格式如图2.14所示。
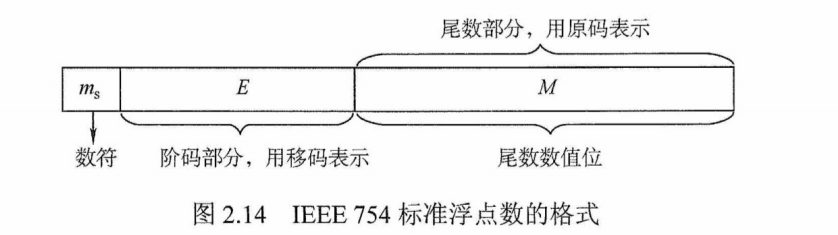
IEEE 754标准规定常用的浮点数格式有短浮点数(单精度、float型)、长浮点数(双精度、double型)、临时浮点数,见表2.6。
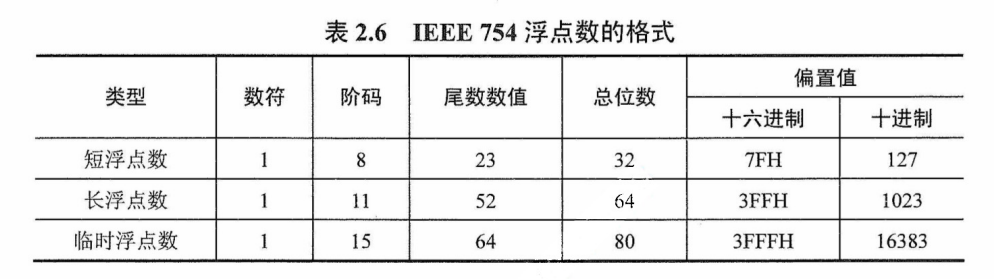
IEEE 754标准的浮点数(除临时浮点数外),是尾数用采取隐藏位策略的原码表示,且阶码用移码表示的浮点数。
以短浮点数为例,最高位为数符位;其后是8位阶码,以2为底,用移码表示,阶码的偏置值为$2^{8-1}= 1$ = 127;其后23位是原码表示的尾数数值位。对于规格化的二进制浮点数,数值的最高位总是“1”,为了能使尾数多表示一位有效位,将这个“1”隐含,因此尾数数值实际上是24位。隐含的“1”是一位整数。在浮点格式中表示的 23位尾数是纯小数。例如,$(12)_{10}$ =$(1100)_2$,将它规格化后结果为$1.1×2^3$,其中整数部分的“1”将不存储在23位尾数内。
- IEEE 754数值位永远是原码表示
- 这里应该是说错了,规格化浮点数的结果不可能是$1.1×2^3$,只能说编者思路不清晰,可以理解为IEEE 754数值永远是1.xxx
短浮点数与长浮点数都采用隐含尾数最高数位的方法,因此可多表示一位尾数。临时浮点数又称扩展精度浮点数,无隐含位。
阶码是以移码形式存储的。对于短浮点数,偏置值为127;对于长浮点数,偏置值为1023。存储浮点数阶码部分之前,偏置值要先加到阶码真值上。上例中,阶码值为3,因此在短浮点数中,移码表示的阶码为127+3=130(82H);在长浮点数中,阶码为1023+3=1026(402H)。
IEEE 754标准中,规格化的短浮点数的真值为
$$
(-1)^s\times 1.M \times 2^{E-127}
$$
规格化长浮点数的真值为
$$
(-1)^s \times 1.M \times 2^{E-1023}
$$
式中,$s =0$表示正数,$s =1$表示负数;短浮点数E的取值为$1\backsim254$(8位表示),$M$为23位,共32位;长浮点数E的取值为1~2046 (11位表示),M为52位,共64位。IEEE 754标准浮点数的范围见表2.7。
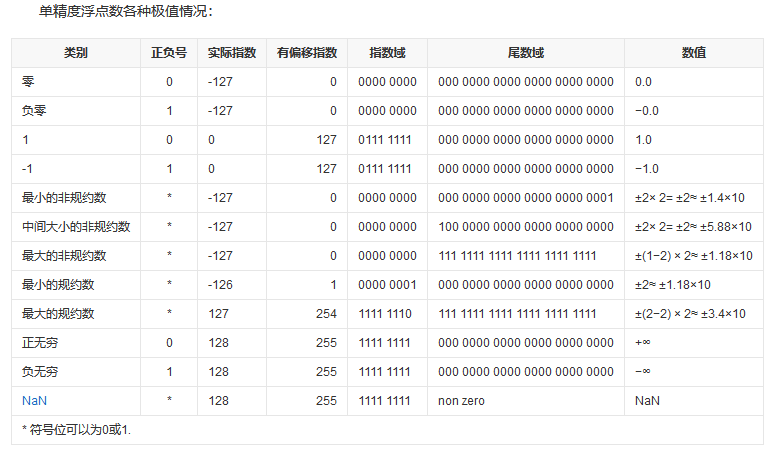
偏置值为127(而非 128〉时,空出8位全1来表示无穷大(若偏置值选128,则不能区分无穷大)。此外,阶码值E的范围为1~254,空出全0表示非规格化数。
由此需要注意,用传统的移码规则计算阶码所得出来的真值,不是正确的阶码真值(正确的做法是当无符号数来计算,然后-127)
注意 IEEE 754 形式分为 $\color{green}{\text{规格化浮点数}}$ 和 $\color{green}{\text{非规格化浮点数}}$
阶码全为0时为非规格化浮点数,对于非规格化数阶码部分是有效的(即-127),但是尾数没有隐含1

IEEE 754单精度浮点数的各种极值情况( 百度百科)
char -> int -> long -> double , 类型转换
定点、浮点表示的区别
(1)数值的表示范围
若定点数和浮点数的字长相同,则浮点表示法所能表示的数值范围将远远大于定点表示法。
(2)精度
所谓精度,是指一个数所含有效数值位的位数。对于字长相同的定点数和浮点数来说,浮点数虽然扩大了数的表示范围,但精度降低了。
(3)数的运算
浮点数包括阶码和尾数两部分,运算时不仅要做尾数的运算,还要做阶码的运算,而且运算结果要求规格化,所以浮点运算比定点运算复杂。
(4)溢出问题
在定点运算中,当运算结果超出数的表示范围时,发生溢出;浮点运算中,运算结果超出尾数表示范围却不一定溢出,只有规格化后阶码超出所能表示的范围时,才发生溢出。
浮点数的加减运算
浮点数运算的特点是阶码运算和尾数运算分开进行。浮点数的加减运算一律采用补码。浮点数加减运算分为以下几步。
Q:如何判断浮点数溢出?
A:阶码溢出
对阶
对阶的目的是使两个操作数的小数点位置对齐,即使得两个数的阶码相等。为此,先求阶差,然后以小阶向大阶看齐的原则,将阶码小的尾数右移一位(基数为2),阶加1,直到两个数的阶码相等为止。尾数右移时,舍弃掉有效位会产生误差,影响精度。
尾数求和
将对阶后的尾数按定点数加(减)运算规则运算。
规格化
以双符号位为例,当尾数大于0时,其补码规格化形式为
$$
\lbrack S \rbrack_\text{补} = 00.1xxx\cdots x
$$
当尾数小于0时,其补码规格化形式为
$$
\lbrack S \rbrack_\text{补} = 11.0xxx\cdots x
$$
可见,当尾数的最高数值位与符号位不同时,即为规格化形式。规格化分为左规与右规两种。
1)左规:当尾数出现$00.0xx\cdots x$或$11.1xx\cdots x$时,需左规,即尾数左移1位,和的阶码减1,直到尾数为$00.1××\cdots ×$或$11.0××\cdots ×$。
2)右规:当尾数求和结果溢出(如尾数为$10.xx \cdots x$或$01.xx\cdots x$)时,需右规,即尾数右移一位,和的阶码加1。
1)对于左规和右规,不应死记。考查尾数的大小,左规一次相当于乘2,右规一次相当于除2;2)$\lbrack -1/2 \rbrack_\text{补}$= 1.1000不是规格化数,需左规一次,$\lbrack -1\rbrack_\text{补}$= 1.0000才是规格化数。
- 讲IEEE 754跟补码有什么关系。?内容编排又出问题了
舍入
在对阶和右规的过程中,可能会将尾数低位丢失,引起误差,影响精度。常见的舍入方法有:“0”舍“1”入法和恒置“1”法。
“0”舍“1”入法:类似于十进制数运算中的“四舍五入”法,即在尾数右移时,被移去的最高数值位为0,则舍去;被移去的最高数值位为1,则在尾数的末位加1。这样做可能会使尾数又溢出,此时需再做一次右规。
恒置“1”法:尾数右移时,不论丢掉的最高数值位是“1”还是“O”,都使右移后的尾数末位恒置“1”。这种方法同样有使尾数变大和变小的两种可能。
溢出判断
与定点数加减法一样,浮点数加减运算最后一步也需判断溢出。
在浮点数规格化中已指出,当尾数之和(差)出现01.×××或10.xxx时,并不表示溢出,只能将此数右规后,再根据阶码来判断浮点数运算结果是否溢出。
浮点数的溢出与否是由阶码的符号决定的。以双符号位补码为例,当阶码的符号位出现“01”时,即阶码大于最大阶码时,表示上溢,进入中断处理;当阶码的符号位出现“10”时,即阶码小于最小阶码时,表示下溢,按机器零处理。实际上原理还是阶码符号位不同表示溢出,且真实符号位和高位符号位一致。
C语言中的浮点数类型及类型转换
C语言中的 float和 double类型分别对应于IEEE 754单精度浮点数和双精度浮点数。longdouble类型对应于扩展双精度浮点数,但long double 的长度和格式随编译器和处理器类型的不同而有所不同。在C程序中等式的赋值和判断中会出现强制类型转换,以char→int→long→double和 float→double最为常见,从前到后范围和精度都从小到大,转换过程没有损失。
1)从int转换为float时,虽然不会发生溢出,但 int可以保留32位,float保留24位,可能有数据舍入,若从int转换为double则不会出现。
2)从int或float转换为double时,因为double的有效位数更多,因此能保留精确值。3)从double转换为float时,因为float 表示范围更小,因此可能发生溢出。此外,由于有效位数变少,因此可能被舍入。
4)从float或double转换为 int 时,因为int没有小数部分,所以数据可能会向0方向被截断(仅保留整数部分),影响精度。另外,由于int的表示范围更小,因此可能发生溢出。在不同数据类型之间转换时,往往隐藏着一些不容易察觉的错误,编程时要非常小心。
算术逻辑单元(ALU)
在计算机中,运算器承担了执行各种算术和逻辑运算的工作,运算器由算术逻辑单元(Arithmetic Logic Unit,ALU)、累加器、状态寄存器和通用寄存器组等组成。ALU的基本功能包括加、减、乘、除四则运算,与、或、非、异或等逻辑运算,以及移位、求补等操作。
计算机运行时,运算器的操作和操作种类由控制器决定。运算器处理的数据来自存储器;处理后的结果数据通常送回存储器,或暂存在运算器中。
串行加法器和并行加法器
ALU的核心部件是加法器,加法器是由全加器再配以其他必要的逻辑电路组成的,根据组成加法器的全加器个数是单个还是多个,加法器有串行和并行之分。
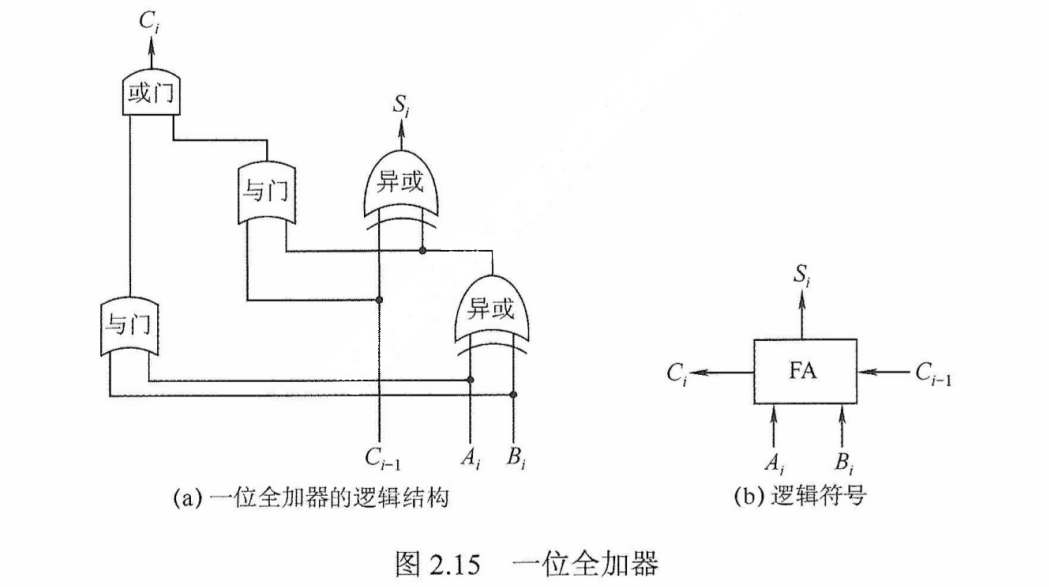
一位全加器
全加器(FA)是最基本的加法单元,有加数$A_i$、加数$B_i$与低位传来的进位$C_{i-1}$共三个输入,有本位和$S_i$与向高位的进位$C_i$共两个输出。
全加器的逻辑表达式如下。
和表达式:$S_i = A_i \oplus B_i \oplus C_{i-1}(A_i, B_i, C_{i-1}\text{中有奇数个}1\text{时},S_i = 1;\text{否则}S_i = 0)$
进位表达式:$C_i=A_iB_i+(A_i \oplus B_i)C_i$
一位全加器对应的逻辑结构如图2.15(a)所示,其逻辑符号如图2.15(b)所示。
串行加法器
在串行加法器中,只有一个全加器,数据逐位串行送入加法器中进行运算。若操作数长n位,则加法就要分n次进行,每次产生一位和,并且串行逐位地送回寄存器。进位触发器用来寄存进位信号,以便参与下一次运算。
串行加法器具有器件少、成本低的优点,但运算速度慢,多用于某些低速的专用运算器。
并行加法器
并行加法器由多个全加器组成,其位数与机器的字长相同,各位数据同时运算。并行加法器可同时对数据的各位相加,但存在一个加法的最长运算时间问题,原因是,虽然操作数的各位是同时提供的,但低位运算所产生的进位会影响高位的运算结果。例如,$11\cdots11$和$00 \cdots01$相加,最低位产生的进位将逐位影响至最高位,因此并行加法器的最长运算时间主要是由进位信号的传递时间决定的,而每个全加器本身的求和延迟只是次要因素。
因此,提高并行加法器速度的关键是尽量加快进位产生和传递的速度。并行加法器的进位产生和传递如下:
并行加法器中的每个全加器都有一个从低位送来的进位输入和一个传送给高位的进位输出。通常将传递进位信号的逻辑线路连接起来构成的进位网络称为进位链。
进位表达式为
$$
C_i = G_i + P_iC_{i-1}(G_i=1\text{或}P_iG_{i-1}=1\text{时},C_i=1)
$$
式中,$G_i$时进位产生函数,$G_i=A_iB_i$;$P_i$时进位传递函数,$P_i= A_i \oplus B_i $。
当$A_i$与$B_i$都是1时,$C_i = 1$,即有进位信号产生,所以将$A_iB_i$称为进位产生函数或本地进位,并以$G_i$表示。$A_i \oplus B_i =1$且$C_{i-1}=1$时,$C_i=1$。这种情况可视为$A_i \oplus B_i = 1$,第$i-1$位的进位信号$C_{i-1}$可以通过本地向高位传送。因此,把$A_i \oplus B_i$称为进位传递函数(进位传递条件),并以$P_i$表示。
并行加法器的进位通常分为串行进位与并行进位。
(1)串行进位
把n个全加器串接起来,就可进行两个n位数的相加,这种加法器称为串行进位的并行加法器,如图2.16所示。串行进位又称行波进位,每级进位直接依赖于前一级的进位,即进位信号是逐级形成的。
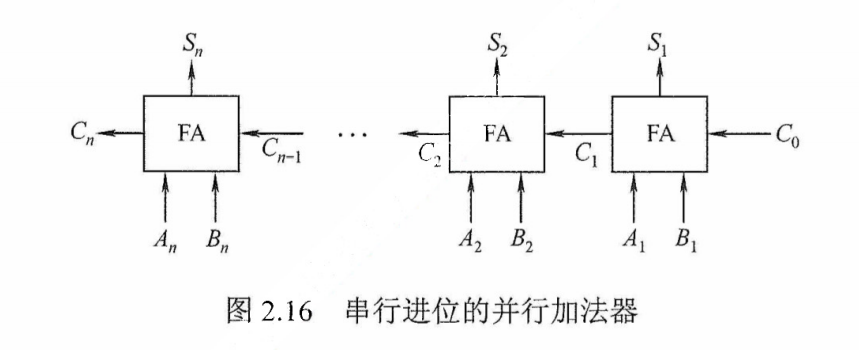

可见,低位运算产生进位所需要的时间将可能影响直至最高位运算的时间。因此,并行加法器的最长运算时间主要是由进位信号的传递时间决定的,位数越多延迟时间就越长,而全加器本身的求和延迟只为次要因素,所以加快进位产生和提高传递的速度是关键。
(2)并行进位
并行进位又称先行进位、同时进位,其特点是各级进位信号同时形成。
采用并行进位的方案可以加快进位产生和提高传递的速度,即将各级低位产生的本级G和P信号依次同时送到高位各全加器的输入,以使它们同时形成进位信号,各进位信号表达式如下,可见它们可以同时形成进位信号:
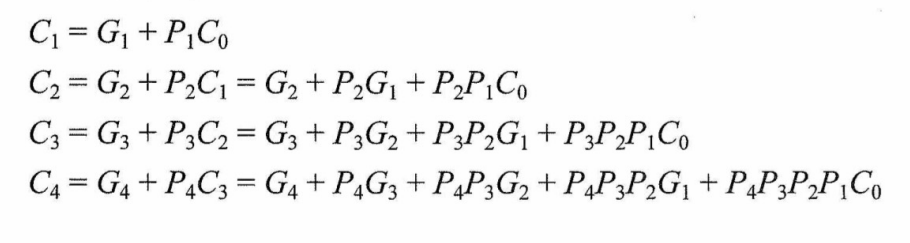
上述各式中所有的进位输出仅由$G_i$、$P_i$,及最低进位输入$C_0$决定,而不依赖于其低位的进位输入$C_{i-1}$,因此各级进位输出可以同时产生。
这种进位方式是快速的,与字长无关。但随着加法器位数的增加,$C_i$的逻辑表达式会变得越来越长,输入变量会越来越多,这会使电路结构变得很复杂,所以完全采用并行进位是不现实的。
分组并行进位方式,实际上通常采用分组并行进位方式。这种方式把n位全加器分为若干小组,小组内的各位之间实行并行快速进位,小组与小组之间可以采用串行进位方式,也可以采用并行快速进位方式,因此有以下两种情况。
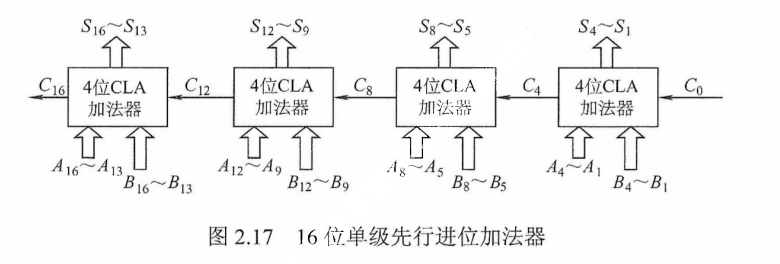
${\textstyle\unicode{x2460}}$ 单级先行进位方式,又称组内并行、组间串行进位方式。以16位加法器为例,可分为4组,每组4位。第一小组组内的进位逻辑函数$C_1$、$C_2$、$C_3$、$C_4$的表达式与前述相同,$C_1$~$C_4$信号是同时产生的,实现上述进位逻辑函数的电路称为4位先行进位电路(CLA)。
利用4位CLA 电路及进位产生/传递电路和求和电路可以构成4位CLA加法器。用4个这样的CLA加法器构成的16位单级先行进位加法器如图2.17所示。
${\textstyle\unicode{x2461}}$ 多级先行进位方式,又称组内并行、组间并行进位方式。下面仍以16位字长的加法器为例,分析两级先行进位加法器的设计方法。第一小组的进位输出$C_4$可以写为

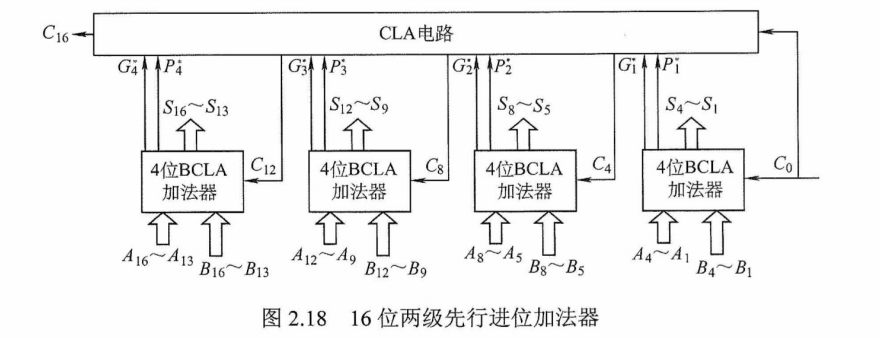
这种电路称为成组先行进位电路(BCLA)。利用这种4位的 BCLA电路及进位产生与传递电路和求和电路可以构成4位BCLA加法器。16位的两级先行进位加法器可由4个BCLA加法器和1个CLA电路构成,如图2.18所示。
这种方法可以扩展到多于两级的先行进位加法器,如用三级先行进位结构设计64位加法器这种加法器的优点是字长对加法时间影响甚小;缺点是造价较高。
算术逻辑单元的功能和结构
带标志加法器
无符号数加法器只能用于两个无符号数相加,不能进行带符号整数的加/减运算。为了能进行带符号整数的加/减运算,还需要在无符号数加法器的基础上增加相应的逻辑门电路,使得加法器不仅能计算和/差,还要能生成相应的标志信息。图2.19是带标志加法器的实现电路。
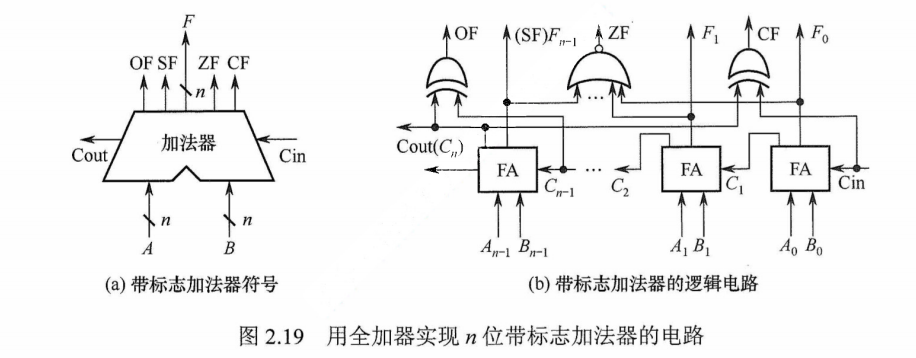
在图2.19 中,溢出标志的逻辑表达式为$OF = C_n \oplus C_{n-1}$符号标志就是和的符号,即 SF=$F_{n-1}$﹔零标志$ZF=1$当且仅当$F=0$;进位/借位标志$CF =C_{out} \oplus C_{in}$,即当$C_{in}$=0时,CF为进位$C_{out}$,当$C_{in}=1$时,CF为进位$C_{out}$取反。
值得注意的是,为了加快加法运算的速度,实际电路一定使用多级先行进位方式,图2.19(b)是为了说明如何从加法运算结果中获得标志信息,因而使用全加器简化了加法器电路。
算术逻辑单元(ALU)
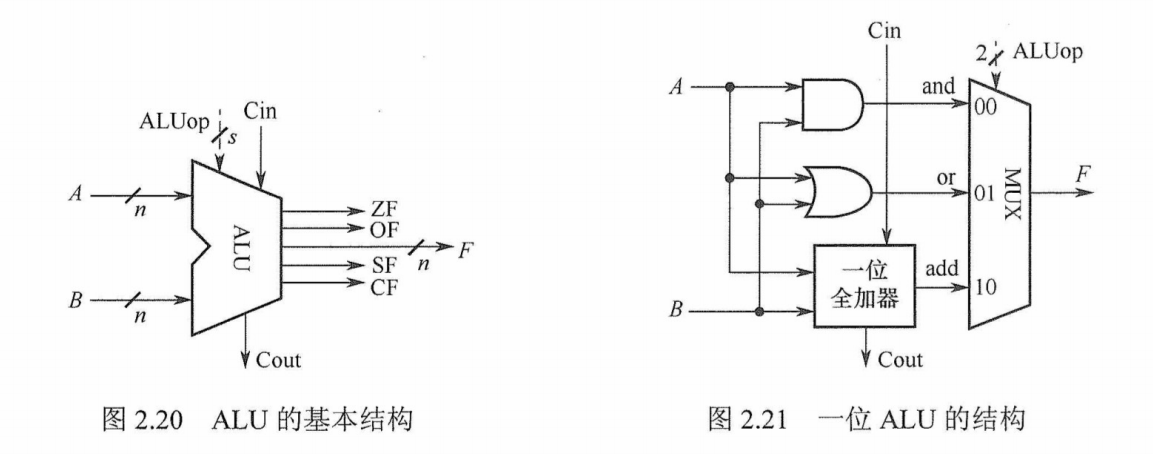
ALU是一种功能较强的组合逻辑电路,它能进行多种算术运算和逻辑运算。由于加、减、乘、除运算最终都能归结为加法运算,因此 ALU的核心是带标志加法器,同时也能执行“与”“或”“非”等逻辑运算。ALU的基本结构如图2.20所示,其中A和B是两个n位操作数输入端,C是进位输入端,ALUop是操作控制端,用来决定ALU所执行的处理功能。例如,ALUop选择Add运算,ALU就执行加法运算,输出的结果就是A加B之和。ALUop 的位数决定了操作的种类。例如,当位数为3时,ALU最多只有8种操作。
图2.21给出了能够完成3种运算“与”、“或”和“加法”的一位ALU结构图。其中,一位加法用一个全加器实现,在ALUop的控制下,由一个多路选择器(MUX)选择输出3种操作结果之一。这里有3种操作,所以ALUop至少要有两位。
同时,ALU也可以实现左移或右移的移位操作。
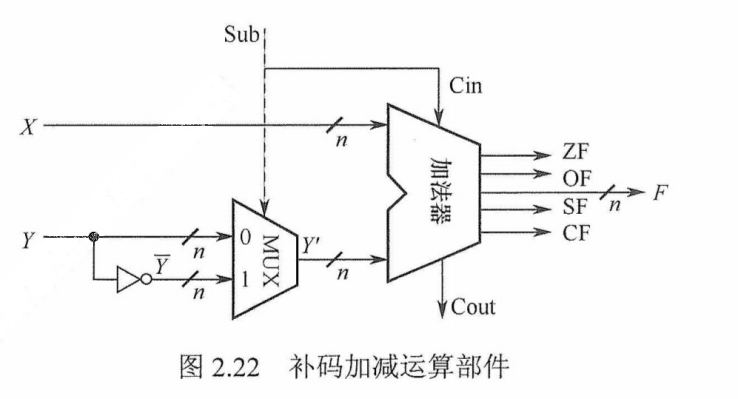
补码加减运算部件
假设一个数的补码表示为Y,则这个数的负数的补码为$\bar{Y}$+1,因此,只要在原加法器的Y输入端加n个反向器以实现各位取反的功能,然后加一个2选1多路选择器,用一个控制端Sub来控制,以选择是将原码$Y$输入加法器还是将$\bar{Y}$输入加法器,并将控制端Sub同时作为低位进位送到加法器,如图2.22所示。该电路可实现补码加减运算。当控制端Sub 为 1时,做减法,实现$X+\bar{Y}+1=\lbrack x \rbrack_\text{补}+\lbrack -y \rbrack_\text{补}$;当控制端Sub为0时,做加法,实现$X+ Y=\lbrack x \rbrack_\text{补}+\lbrack y \rbrack_\text{补}$
图2.22中的加法器是带标志加法器。无符号整数的二进制表示相当于正整数的补码表示,因此,该电路同时也能实现无符号整数的加/减运算。对于带符号整数x和y,图中X和Y分别是x和y的补码表示;对于无符号整数x和y,图中X和Y分别是x和y的二进制表示。
可通过标志信息来区分带符号整数运算结果和无符号整数运算结果。
零标志ZF =1表示结果为0。不管是作为无符号数还是作为带符号整数来运算,ZF都有意义。
进/借位标志CF表示无符号数加/减运算时的进位/借位。加法时,CF= 1表示无符号数加法溢出,因此CF等于进位输出$C_{out}$。减法时,CF =1表示有借位,即不够减故将进位输出$C_{out}$取反来作为借位标志。综合可得CF=Sub$\oplus C_{out}$。对于带符号整数运算,CF没有意义。
溢出标志OF = 1表示带符号整数运算时结果发生溢出。对于无符号整数运算,OF没有意义。
注意:如对电路基础知识不太熟悉,可参阅电路相关教材的基础部分。对此章电路内容亦不必过分深究,目前统考对电路的要求并不高,且本节也不属于重点内容。
本章小结
在计算机中,为什么要采用二进制来表示数据?
从可行性来说,采用二进制,只有0和1两个状态,能够表示0、1两种状态的电子器件很多,如开关的接通和断开、晶体管的导通和截止、磁元件的正负剩磁、电位电平的高与低等,都可表示0、1两个数码。使用二进制,电子器件具有实现的可行性。
从运算的简易性来说,二进制数的运算法则少,运算简单,使计算机运算器的硬件结构大大简化(十进制的乘法九九口诀表有55条公式,而二进制乘法只有4条规则)。
从逻辑上来说,由于二进制0和1正好和逻辑代数的假(false)和真(true)相对应,有逻辑代数的理论基础,用二进制表示二值逻辑很自然。
计算机在字长足够的情况下能够精确地表示每个数吗?若不能,请举例。
计算机采用二进制来表示数据,在字长足够时,可以表示任何一个整数。而二进制表示小数时只能够用1/( $2^n$ )的和的任意组合表示,即使字长很长,也不可能精确表示出所有小数,只能无限逼近。例如0.1就无法用二进制精确地表示。
字长相同的情况下,浮点数和定点数的表示范围与精度有什么区别?
字长相同时,浮点数取字长的一部分作为阶码,所以表示范围比定点数要大,而取一部分作为阶码也就代表着尾数部位的有效位数减少,而定点数字长的全部位都用来表示数值本身,精度要比同字长的浮点数更大。
用移码表示浮点数的阶码有什么好处?
检验移码的特殊值(O和 max)时比较容易。阶码以移码编码时的特殊值如下。0:表示指数为负无穷大,相当于分数分母无穷大,整个数无穷接近0,在尾数也为0时可用来表示0;尾数不为零表示未正规化的数。max:表示指数正无穷大,若尾数为0,则表示浮点数超出表示范围(正负无穷大);尾数不为0,则表示浮点数运算错误。
常见问题和易混淆知识点
如何表示一个数值数据?计算机中的数值数据都是二进制数吗?
在计算机内部,数值数据的表示方法有以下两大类。
①直接用二进制数表示。分为无符号数和有符号数,有符号数又分为定点数表示和浮点数
表示。无符号数用来表示无符号整数(如地址等信息);定点数用来表示整数;浮点数用来表示实数。
${\textstyle\unicode{x2461}}$ 二进制编码的十进制数,一般都采用8421码(也称NBCD码)来表示,用来表示
整数。
所以,计算机中的数值数据虽然都用二进制来编码表示,但不全是二进制数,也有用十进制数表示的。后面一章有关指令类型的内容中,就有对应的二进制加法指令和十进制加法指令。
在高级语言编程中所定义的unsigned/short/int/long/float/double型数据是怎么表示的?什么称为无符号整数的“溢出”?
unsigned 型数据就是无符号整数,不考虑符号位。直接用全部二进制位对数值进行编码得到的就是无符号数,一般都用补码表示。
int型数据就是定点整数,一般用补码表示。int型数据的位数与运行平台和编译器有关,一般是32位或16位。例如,真值是-12的int型整数,在机器内存储的机器数(假定用32位寄存器寄存)是1111 1111 1111 1111 1111 1111 1111 0100。
long 型数据和 short型数据也都是定点整数,只是位数不同,分别是长整型和短整型数,通常用补码表示。
float型数据是用来表示实数的浮点数。现代计算机用IEEE 754标准表示浮点数,其中 32位单精度浮点数就是 float型,64位双精度浮点数就是double型。
需要注意的是,C语言中的int型和unsigned型变量的存储方式没有区别,都按照补码的形式存储,在不溢出范围内的加减法运算也是相同的,只是int型变量的最高位代表符号位,而unsigned型中的最高位表示数值位,两者在C语言中的区别体现在输出时到底是采用%d还是采用%u。
- $\blacktriangleright$(什么叫都是用补码来存储,为什么unsigned 也是用补码来存储)
对于无符号定点整数来说,若寄存器位数不够,则计算机运算过程中一般保留低n位,舍弃高位。这样,会产生以下两种结果。
①保留的低n位数不能正确表示运算结果。在这种情况下,意味着运算的结果超出了计算
机所能表达的范围,有效数值进到了第n+1位,称此时发生了“溢出”现象。
${\textstyle\unicode{x2461}}$ 保留的低n位数能正确表达计算结果,即高位的舍去并不影响其运算结果。
如何判断一个浮点数是否是规格化数?
为了使浮点数能尽量多地表示有效位数,一般要求运算结果用规格化数形式表示。规格化浮点数的尾数小数点后的第一位一定是个非零数。因此,对于原码编码的尾数来说,只要看尾数的第一位是否为1就行;对于补码表示的尾数,只要看符号位和尾数最高位是否相反。需要注意的是,IEEE 754标准的浮点数尾数是用原码编码的。
对于位数相同的定点数和浮点数,可表示的浮点数个数比定点数个数多吗?
不是,可表示的数据个数取决于编码所采用的位数。编码位数一定,编码出来的数据个数就是一定的。n位编码只能表示$2^n$个数,所以对于相同位数的定点数和浮点数来说,可表示的数据个数应该一样多(有时可能由于一个值有两个或多个编码对应,编码个数会有少量差异)。
浮点数如何进行舍入?
舍入方法选择的原则是:①尽量使误差范围对称,使得平均误差为0,即有舍有入,以防误差积累。②方法要简单,以加快速度。
IEEE754有4种舍入方式。
①就近舍入:舍入为最近可表示的数,若结果值正好落在两个可表示数的中间,则一般选
择舍入结果为偶数。
${\textstyle\unicode{x2461}}$ 正向舍入:朝 + $\infty$ 方向舍入,即取右边的那个数。
③负向舍入:朝 -$\infty$ 方向舍入,即取左边的那个数。
④截去:朝0方向舍入,即取绝对值较小的那个数。
现代计算机中是否要考虑原码加减运算?如何实现?
因为现代计算机中浮点数采用IEEE754标准,所以在进行两个浮点数的加减运算时,必须考虑原码的加减运算,因为IEEE 754规定浮点数的尾数都用原码表示。
原码的加减运算可以有以下两种实现方式:
1)转换为补码后,用补码加减法实现,结果再转换为原码。
2)直接用原码进行加减运算,符号和数值部分分开进行(具体过程见原码加减运算部分)。
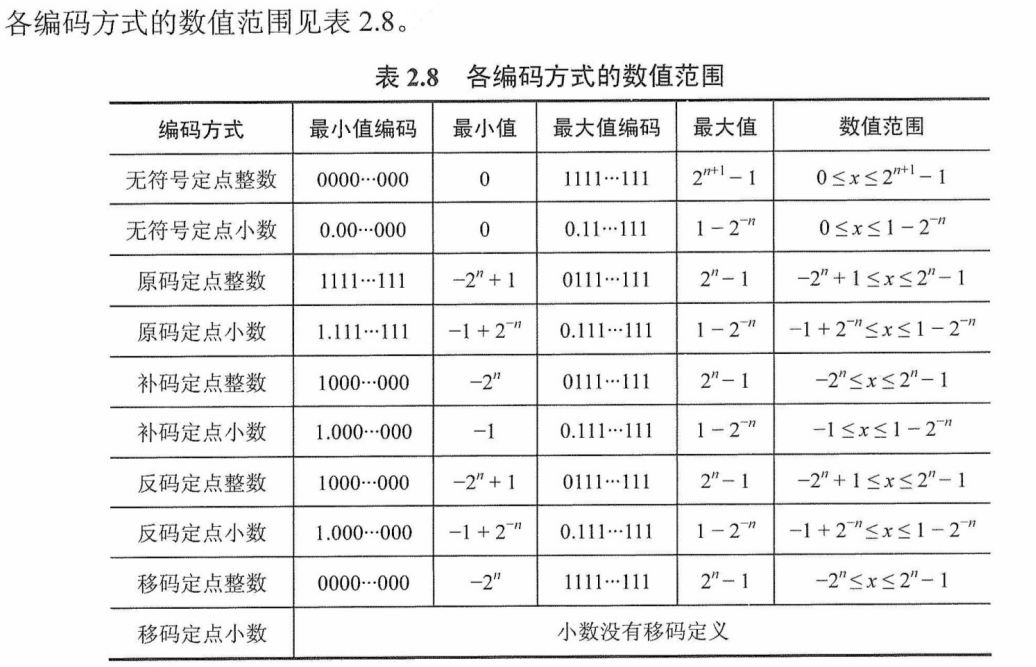
长度为n+1的定点数,按照不同的编码方式,表示的数值范围是多少?
各编码方式的数值范围
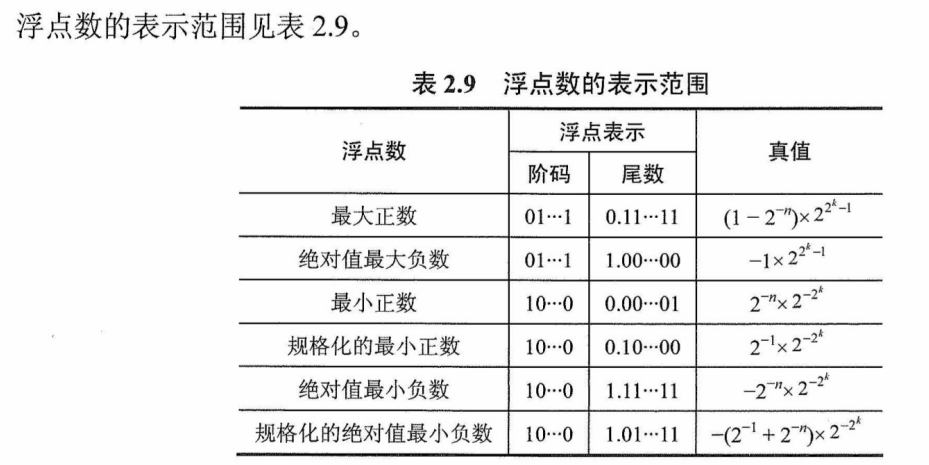
设阶码和尾数均用补码表示,阶码部分共K+1位(含1位阶符),尾数部分共n +1位(含1位数符),则这样的浮点数的表示范围是多少?
表2.9浮点数的表示范围
c语言相关
基本数据类型所占的字节数
| 类型 | 字节数 |
|---|---|
| char | 1 |
| short | 2 |
| int | 4 |
| long | 4 |
| float | 4 |
| double | 8 |
$2^8$ = 256
$2^{16}$ = 65536
$2^{32}$ = 4294967296
$2^{64}$ = 18446744073709551616
溢出那些事
unsigned int 之间做减法产生负数会怎么样
边界对齐
边界对齐:参考文献
补码那些事
使用补码表示时(整数和定点小数都有如下结论),若符号位相同,则数值位越大码值越大。
移位那些事
一定要记住符号位不动,变动的是数值位
符号扩展那些事
需要保证数值不变
关于门电路相关的知识
存储系统
p101
(一)存储器的分类
(二)存储器的层次化结构
(三)半导体随机存取存储器
SRAM、DRAM、只读存储器、Flash存储器(四)主存储器与CPU的连接
(五)双口 RAM和多模块存储器
(六)高速缓冲存储器(Cache)
Cache的基本工作原理
Cache和主存之间的映射方式
Cache 中主存块的替换算法
Cache 写策略
(七)虚拟存储器
虚拟存储器的基本概念;页式虚拟存储器
段式虚拟存储器;段页式虚拟存储器;TLB(快表)
【复习提示】
本章是历年命题重点,特别是有关Cache和虚拟存储器的考点容易出综合题。此外,存储器的分类与特点,存储器的扩展(芯片选择、连接方式、地址范围等),低位交叉存储器,Cache 的相关计算与替换算法,虚拟存储器与快表也容易出选择题。读者应在掌握基本原理和理论的基础上,多结合习题进行反复训练,以加深巩固。另外,读者需掌握存在Cache和TLB的计算机中的地址翻译与Cache 映射问题,也建议结合《操作系统考研复习指导》复习。
本章有两个难点:一是Cache 映射规律、容量计算及替换特性;二是交叉存储器访问时间和访问效率。二者都可与第5章的大题综合,或与第6章总线访问内存时间的计算问题综合。
在学习本章时,请读者思考以下问题:
1)存储器的层次结构主要体现在何处?为何要分这些层次﹖计算机如何管理这些层次?
2)存取周期和存取时间有何区别?
3)在虚拟存储器中,页面是设置得大一些好还是设置得小一些好?请读者在学习本章的过程中寻找答案,本章末尾会给出参考答案。
存储器与CPU的连接(天勤)
- 门电路的小圆圈代表对信号取反
- 74138译码器的小圆圈代表低电平有效
图片详情
$\overline{MREQ}$ 访存控制信号
- 存储单元是一个字
- 存储元是一个位
- $\mho$(cache里面到底放的什么,地址映射由谁来完成的)
存储器概述
存储器的分类
存储器种类繁多,可从不同角度对存储器进行分类。
按在计算机中的作用(层次)分类
1))主存储器。简称主存,又称内存储器(内存),用来存放计算机运行期间所需的大量程序和数据,CPU可以直接随机地对其进行访问,也可以和高速缓冲存储器(Cache)及辅助存储器交换数据。其特点是容量较小、存取速度较快、每位价格较高。
2)辅助存储器。简称辅存,又称外存储器(外存),是主存储器的后援存储器,用来存放当前暂时不用的程序和数据,以及一些需要永久性保存的信息,它不能与CPU直接交换信息。其特点是容量极大、存取速度较慢、单位成本低。
3)高速缓冲存储器。简称Cache,位于主存和CPU之间,用来存放正在执行的程序段和数据,以便CPU能高速地使用它们。Cache的存取速度可与CPU的速度相匹配,但存储容量小、价格高。现代计算机通常将它们制作在CPU 中。
按存储介质分类
按存储介质,存储器可分为磁表面存储器(磁盘、磁带)、磁心存储器半导体存储器(MOS型存储器、双极型存储器)和光存储器(光盘)。
按存取方式分类
1)随机存储器(RAM)。存储器的任何一个存储单元的内容都可以随机存取,而且存取时间与存储单元的物理位置无关。其优点是读写方便、使用灵活,主要用作主存或高速缓冲存储器。RAM又分为静态RAM和动态RAM(第3节会详细介绍)。
2)只读存储器(ROM)。存储器的内容只能随机读出而不能写入。信息一旦写入存储器就固定不变,即使断电,内容也不会丢失。因此,通常用它存放固定不变的程序、常数和汉字字库等。它与随机存储器可共同作为主存的一部分,统一构成主存的地址域。由ROM派生出的存储器也包含可反复重写的类型,ROM和RAM 的存取方式均为随机存取。注意广义上的只读存储器已可通过电擦除等方式进行写入,其“只读”的概念没有保留,但仍保留了断电内容保留、随机读取特性,但其写入速度比读取速度慢得多。
3)串行访问存储器。对存储单元进行读/写操作时,需按其物理位置的先后顺序寻址,包括.顺序存取存储器(如磁带)与直接存取存储器(如磁盘、光盘)。
顺序存取存储器的内容只能按某种顺序存取,存取时间的长短与信息在存储体上的物理位置有关,其特点是存取速度慢。直接存取存储器既不像 RAM 那样随机地访问任何一个存储单元,又不像顺序存取存储器那样完全按顺序存取,而是介于两者之间。存取信息时通常先寻找整个存储器中的某个小区域(如磁盘上的磁道),再在小区域内顺序查找。
按信息的可保存性分类
断电后,存储信息即消失的存储器,称为易失性存储器,如 RAM。断电后信息仍然保持的存储器,称为非易失性存储器,如ROM、磁表面存储器和光存储器。若某个存储单元所存储的信息被读出时,原存储信息被破坏,则称为破坏性读出;若读出时,被读单元原存储信息不被破坏,则称为非破坏性读出。具有破坏性读出性能的存储器,每次读出操作后,必须紧接一个再生的操作,以便恢复被破坏的信息。
存储器的性能指标
存储器有3个主要性能指标,即存储容量、单位成本和存储速度。这3个指标相互制约,设计存储器系统所追求的目标就是大容量、低成本和高速度。
1)存储容量=存储字数×字长(如1M×8位)。单位换算: 1B(Byte,字节)= 8b (bit,位)。存储字数表示存储器的地址空间大小,字长表示一次存取操作的数据量。
2)单位成本:每位价格=总成本/总容量。
3)存储速度:数据传输率=数据的宽度/存储周期。
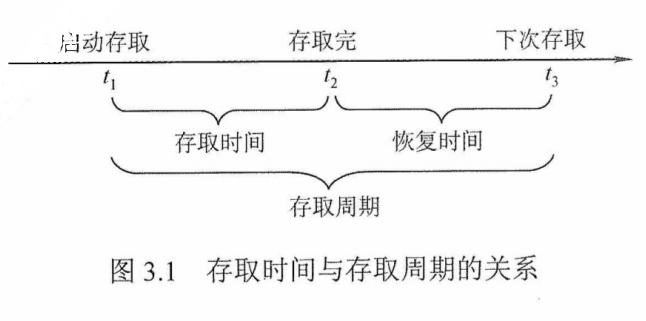
${\textstyle\unicode{x2460}}$ 存取时间($T_a$):存取时间是指从启动一次存储器操作到完成该操作所经历的时间,分为读出时间和写入时间。
${\textstyle\unicode{x2461}}$ 存取周期($T_m$):存取周期又称读写周期或访问周期。它是指存储器进行一次完整的读写操作所需的全部时间,即连续两次独立访问存储器操作(读或写操作)之间所需的最小时间间隔。
${\textstyle\unicode{x2462}}$ 主存带宽($B_m$):主存带宽又称数据传输率,表示每秒从主存进出信息的最大数量,单位为字/秒、字节/秒(B/s)或位/秒(b/s)。
存取时间不等于存储周期,通常存储周期大于存取时间。这是因为对任何一种存储器,在读写操作之后,总要有一段恢复内部状态的复原时间。对于破坏性读出的存储器,存取周期往往比存取时间大得多,甚至可达$T_m = 2T_a$,因为存储器中的信息读出后需要马上进行再生。
存取时间与存取周期的关系如图3.1所示。
存储器的层次化结构
多级存储系统
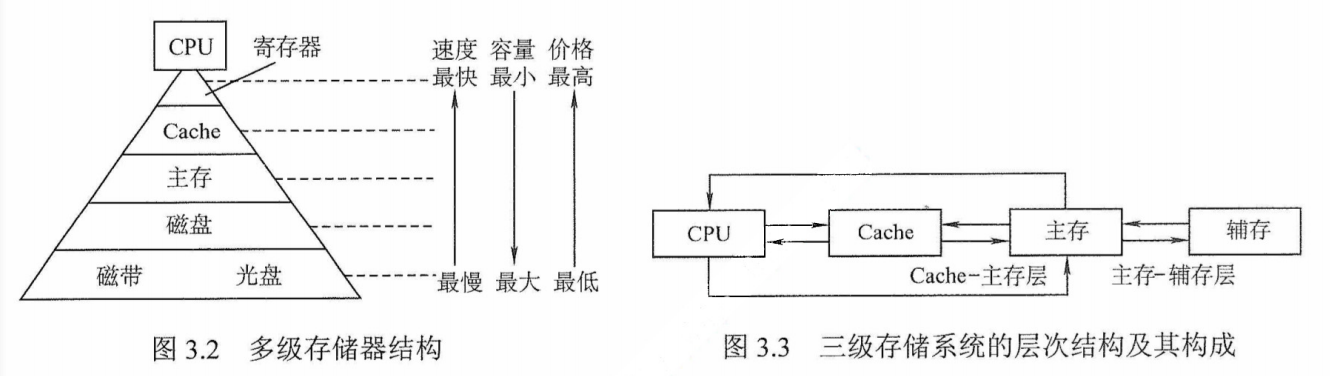
为了解决存储系统大容量、高速度和低成本3个相互制约的矛盾,在计算机系统中,通常采用多级存储器结构,如图3.2所示。在图中由上至下,位价越来越低,速度越来越慢,容量越来越大,CPU 访问的频度也越来越低。
实际上,存储系统层次结构主要体现在“Cache-主存”层次和“主存-辅存”层次。前者主要解决CPU 和主存速度不匹配的问题,后者主要解决存储系统的容量问题。在存储体系中,Cache、主存能与CPU直接交换信息,辅存则要通过主存与CPU交换信息;主存与CPU、Cache、辅存都能交换信息,如图3.3所示。
存储器层次结构的主要思想是上一层的存储器作为低一层存储器的高速缓存。从 CPU 的角度看,“Cache-主存”层次速度接近于Cache,容量和位价却接近于主存。从“主存-辅存”层次分析,其速度接近于主存,容量和位价却接近于辅存。这就解决了速度、容量、成本这三者之间的矛盾,现代计算机系统几乎都采用这种三级存储系统。需要注意的是,主存和 Cache 之间的数据调动是由硬件自动完成的,对所有程序员均是透明的;而主存和辅存之间的数据调动则是由硬件和操作系统共同完成的,对应用程序员是透明的。
在“主存-辅存”这一层次的不断发展中,逐渐形成了虚拟存储系统,在这个系统中程序员编程的地址范围与虚拟存储器的地址空间相对应。对具有虚拟存储器的计算机系统而言,编程时可用的地址空间远大于主存空间。
注意:在“Cache-主存”和“主存-辅存”层次中,上一层中的内容都只是下一层中的内容的副本,也即Cache (或主存)中的内容只是主存(或辅存)中的内容的一部分。
半导体随机存储器
p107
主存储器由DRAM 实现,靠处理器的那一层(Cache)则由 SRAM 实现它们都属于易失性存储器,只要电源被切断,原来保存的信息便会丢失。DRAM的每比特成本低于SRAM,速度也慢于SRAM,价格差异主要是因为制造DRAM需要更多的硅。而ROM属于非易失性存储器。
SRAM和 DRAM
SRAM的工作原理
通常把存放一个二进制位的物理器件称为存储元,它是存储器的最基本的构件。地址码相同的多个存储元构成一个存储单元。若干存储单元的集合构成存储体。
静态随机存储器(SRAM)的存储元是用双稳态触发器(六晶体管MOS)来记忆信息的,因此即使信息被读出后,它仍保持其原状态而不需要再生(非破坏性读出)。
SRAM的存取速度快,但集成度低,功耗较大,所以一般用来组成高速缓冲存储器。
DRAM的工作原理
与SRAM 的存储原理不同,动态随机存储器(DRAM)是利用存储元电路中栅极电容上的电荷来存储信息的,DRAM的基本存储元通常只使用一个晶体管,所以它比SRAM 的密度要高很多。DRAM 采用地址复用技术,地址线是原来的1/2,地址信号分行、列两次传送。
相对于SRAM 来说,DRAM具有容易集成、位价低、容量大和功耗低等优点,但 DRAM的存取速度比SRAM的慢,一般用来组成大容量主存系统。
DRAM 电容上的电荷一般只能维持1~2ms,因此即使电源不断电,信息也会自动消失。为此,每隔一定时间必须刷新,通常取2ms,称为刷新周期。常用的刷新方式有3种:
- 唐朔飞.pp97
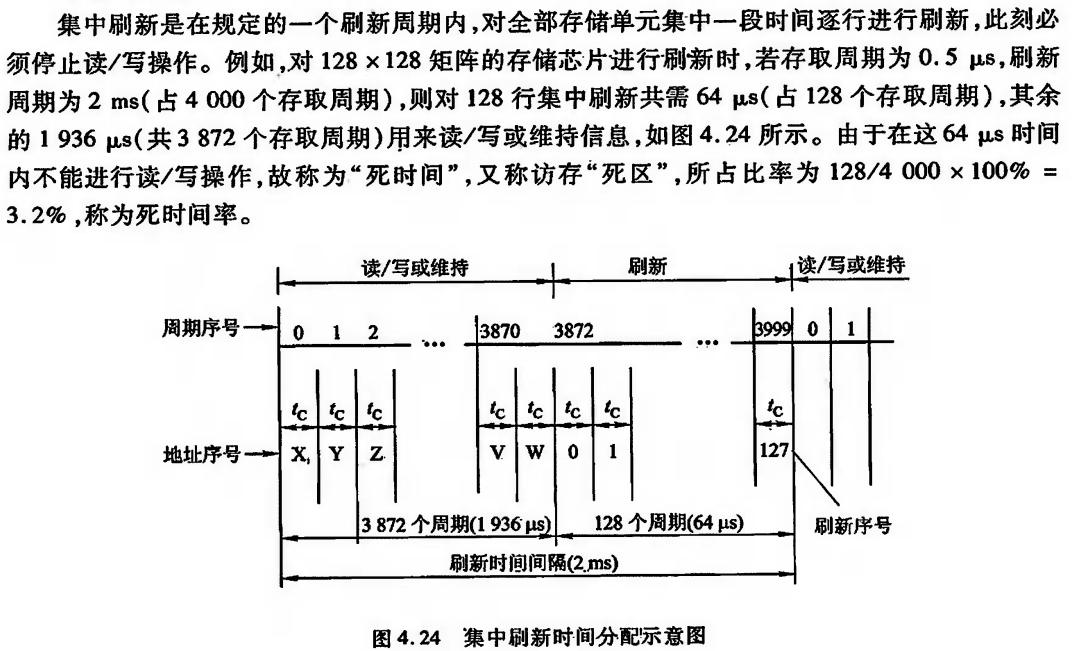
1)集中刷新:指在一个刷新周期内,利用一段固定的时间,依次对存储器的所有行进行逐一再生,在此期间停止对存储器的读写操作,称为“死时间”,又称访存“死区”。优点是读写操作时不受刷新工作的影响;缺点是在集中刷新期间(死区)不能访问存储器。
集中刷新时间分配示意图
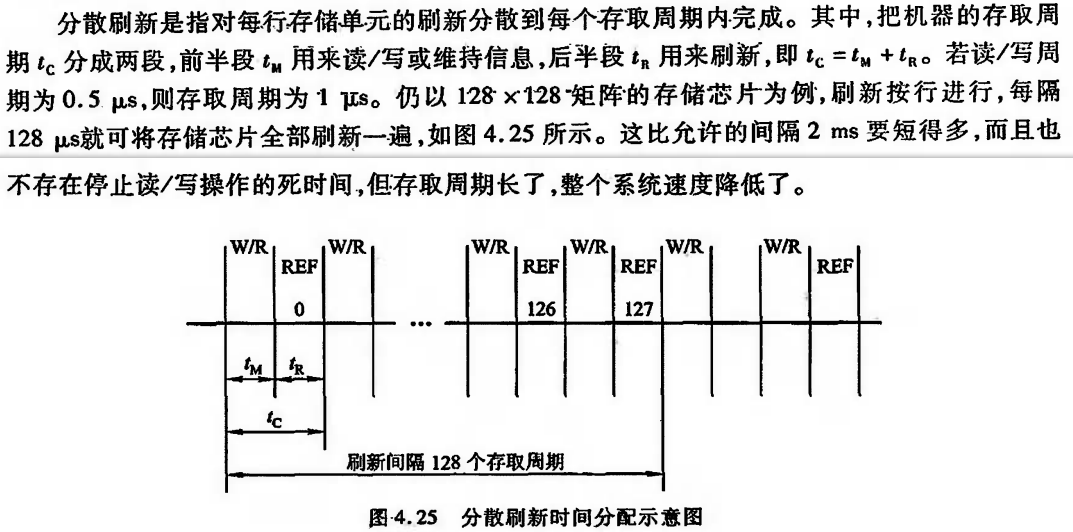
2)分散刷新:把对每行的刷新分散到各个工作周期中。这样,一个存储器的系统工作周期分为两部分:前半部分用于正常读、写或保持;后半部分用于刷新。这种刷新方式增加了系统的存取周期,如存储芯片的存取周期为0.5us,则系统的存取周期为1us。优点是没有死区;缺点是加长了系统的存取周期,降低了整机的速度。
分散刷新时间分配示意图
3)异步刷新:异步刷新是前两种方法的结合,它既可缩短“死时间”,又能充分利用最大刷新间隔为2ms的特点。具体做法是将刷新周期除以行数,得到两次刷新操作之间的时间间隔t,利用逻辑电路每隔时间t产生一次刷新请求。这样可以避免使CPU连续等待过长的时间,而且减少了刷新次数,从根本上提高了整机的工作效率。
异步刷新时间分配示意图
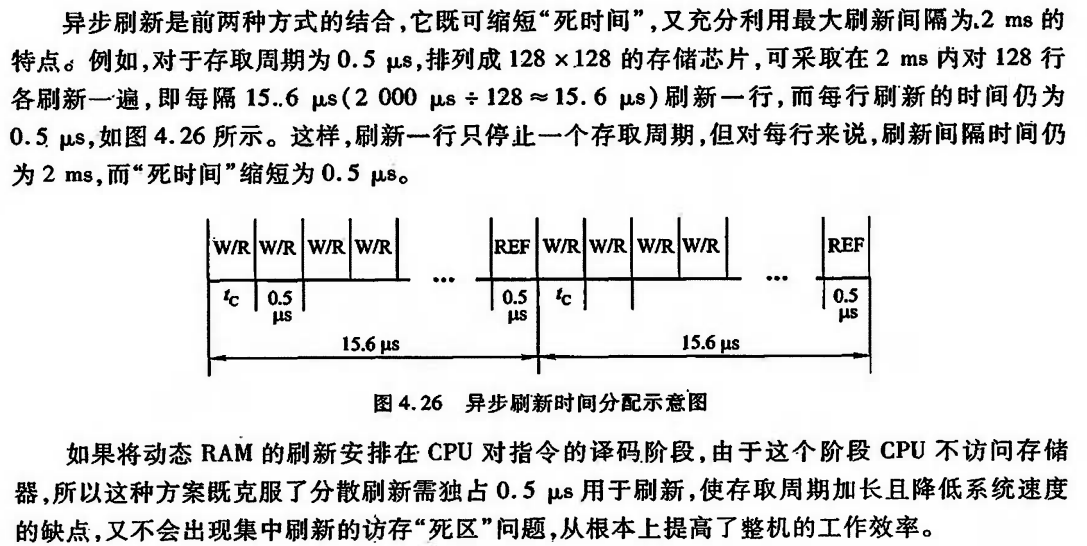
DRAM 的刷新需注意以下问题:①刷新对CPU是透明的,即刷新不依赖于外部的访问;②动态RAM 的刷新单位是行,由芯片内部自行生成行地址;③刷新操作类似于读操作,但又有所不同。另外,刷新时不需要选片,即整个存储器中的所有芯片同时被刷新。
读者需要注意易失性存储器和刷新的区别,易失性存储器是指断电后数据丢失,SRAM 和DRAM都满足断电内容消失,但需要刷新的只有DRAM,而SRAM不需要刷新。
存储器芯片的内部结构
如图3.4所示,存储器芯片由存储体、IO读写电路、地址译码和控制电路等部分组成。
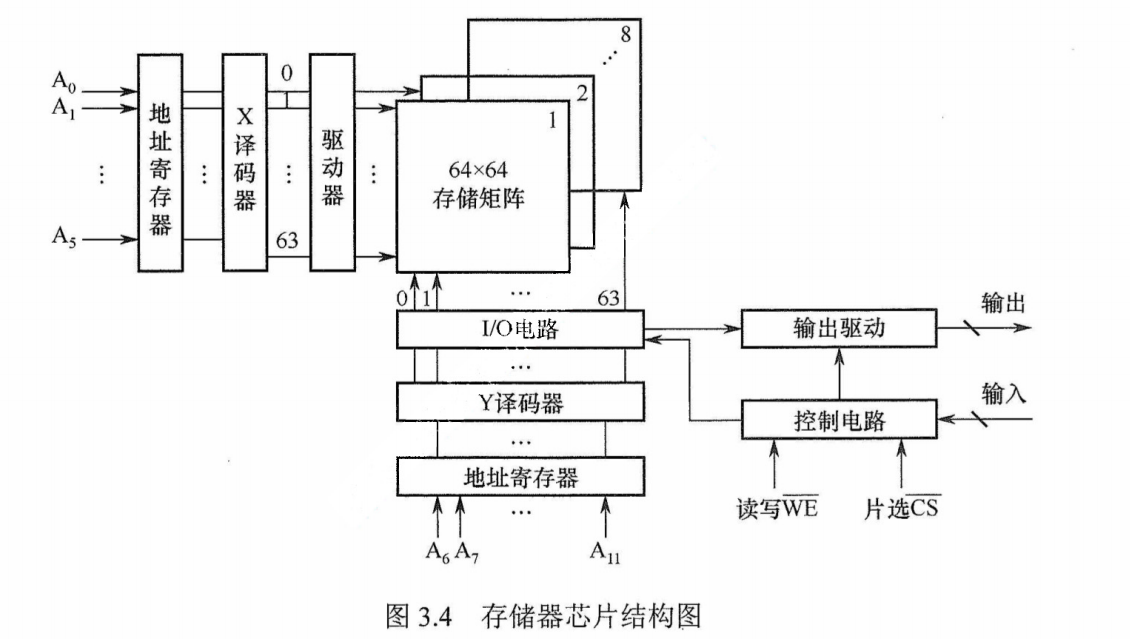
1)存储体(存储矩阵)。存储体是存储单元的集合,它由行选择线(X)和列选择线(Y)来选择所访问单元,存储体的相同行、列上的位同时被读出或写入。
2)地址译码器。用来将地址转换为译码输出线上的高电平,以便驱动相应的读写电路。3)IO控制电路。用以控制被选中的单元的读出或写入,具有放大信息的作用。
4)片选控制信号。单个芯片容量太小,往往满足不了计算机对存储器容量的要求,因此需用一定数量的芯片进行存储器的扩展。在访问某个字时,必须“选中”该存储字所在的芯片,而其他芯片不被“选中”,因此需要有片选控制信号。
5)读/写控制信号。根据CPU给出的是读命令还是写命令,控制被选中单元进行读或写。
存储器的读、写周期
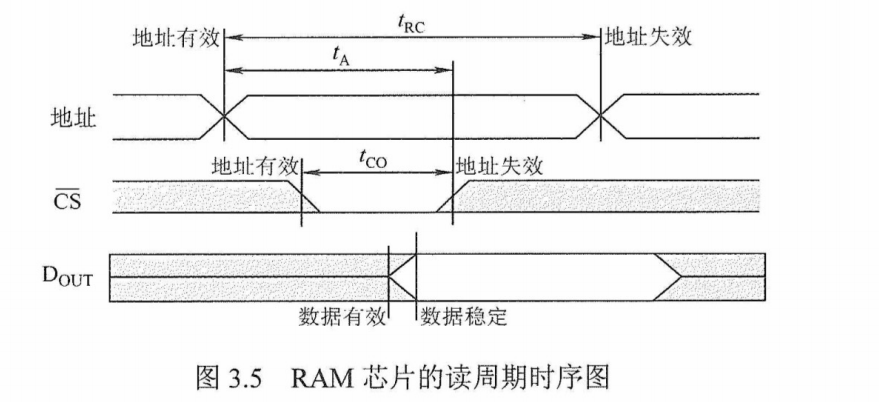
(1) RAM的读周期
从给出有效地址开始,到读出所选中单元的内容并在外部数据总线上稳定地出现所需的时间,称为读出时间($t_A$)。地址片选信号$\bar{CS}$必须保持到数据稳定输出,$t_{CO}$为片选的保持时间,在读周期中$\bar{WE}$为高电平。RAM芯片的读周期时序图如图3.5所示。
读周期与读出时间是两个不同的概念,读周期时间($t_{RC}$)表示存储芯片进行两次连续读操作时所必须间隔的时间,它总是大于等于读出时间。
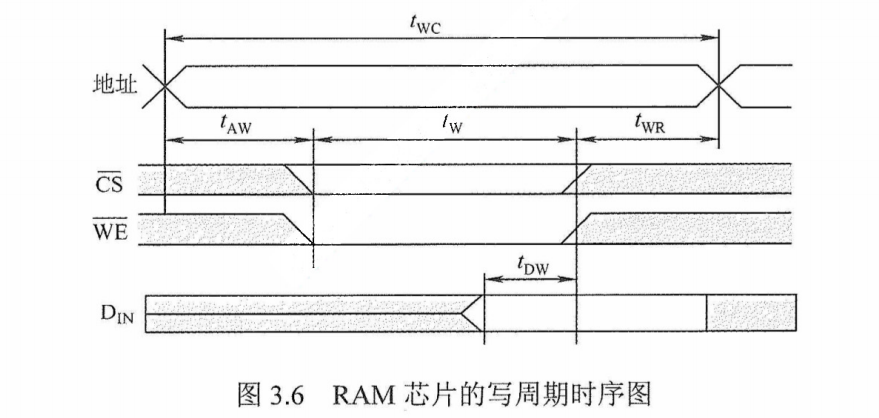
(2)RAM的写周期
要实现写操作,要求片选信号$\bar{CS}$和写命令信号$\bar{WE}$必须都为低电平。为使数据总线上的信息能够可靠地写入存储器,要求$\bar{CS}$信号与$\bar{WE}$信号相“与”的宽度至少为$t_W$
为了保证在地址变化期间不会发生错误写入而破坏存储器的内容,$\bar{WE}$信号在地址变化期间必须为高电平。为了保证有效数据的可靠写入,地址有效的时间至少应为 $t_{WC} = t_{AW} + t_W +t_{WR}$。为了保证在$\bar{WE}$和$\bar{CS}$变为无效前能把数据可靠地写入,要求写入的数据必须在 $t_{DW}$以前在数据总线上已经稳定。RAM芯片的写周期时序图如图3.6所示。
SRAM和DRAM的比较
表3.1详细列出了SRAM 和 DRAM各自的特点。
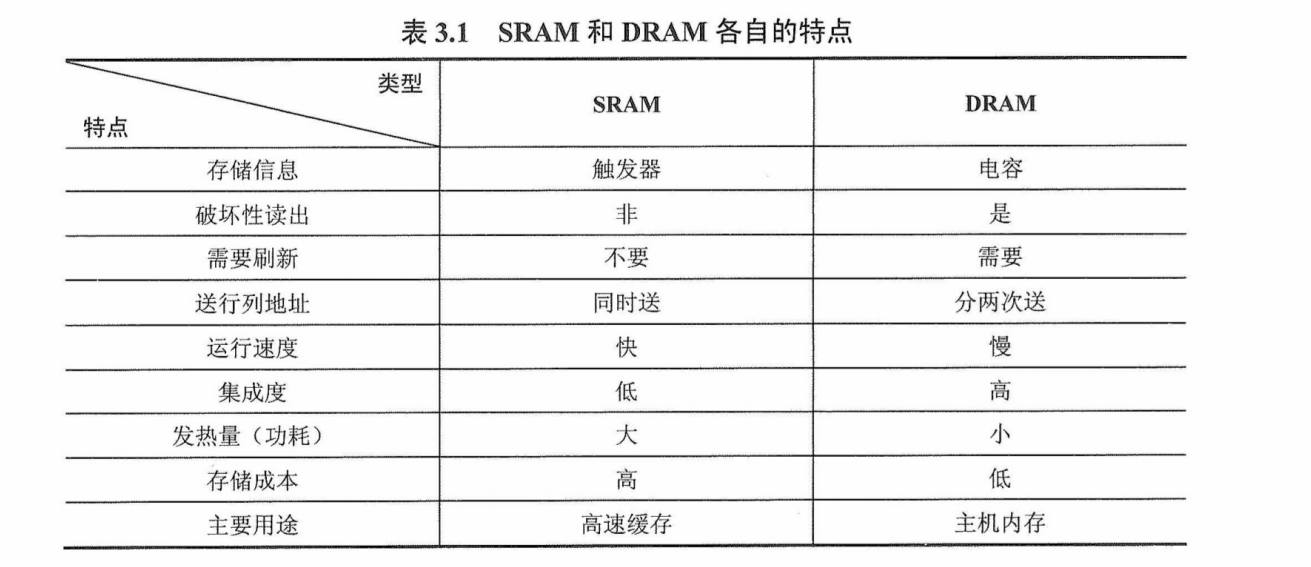
只读存储器
只读存储器(ROM)的特点
ROM 和 RAM 都是支持随机存取的存储器,其中 SRAM和 DRAM均为易失性半导体存储器。而ROM中一旦有了信息,就不能轻易改变,即使掉电也不会丢失,它在计算机系统中是只供读出的存储器。ROM器件有两个显著的优点:
1)结构简单,所以位密度比可读写存储器的高。
2)具有非易失性,所以可靠性高。
ROM的类型
根据制造工艺的不同,ROM可分为掩模式只读存储器(MROM)、一次可编程只读存储器(PROM)、可擦除可编程只读存储器(EPROM)、闪速存储器(Flash Memory)和固态硬盘(Solid State Drives)。
(1)掩模式只读存储器
MROM 的内容由半导体制造厂按用户提出的要求在芯片的生产过程中直接写入,写入以后任何人都无法改变其内容。优点是可靠性高,集成度高,价格便宜;缺点是灵活性差。
(2)一次可编程只读存储器
PROM 是可以实现一次性编程的只读存储器。允许用户利用专门的设备(编程器)写入自己的程序,一旦写入,内容就无法改变。
(3)可擦除可编程只读存储器
EPROM不仅可以由用户利用编程器写入信息,而且可以对其内容进行多次改写。需要修改EPROM 的内容时,先将其全部内容擦除,然后编程。EPROM 又可分为两种,即紫外线擦除(UVEPROM)和电擦除($E^2PROM$)。EPROM 虽然既可读又可写,但它不能取代 RAM,因为EPROM 的编程次数有限,且写入时间过长。
(4)闪速存储器(Flash Memory)
Flash Memory是在EPROM与$E^2PROM$的基础上发展起来的,其主要特点是既可在不加电的情况下长期保存信息,又能在线进行快速擦除与重写。闪速存储器既有EPROM 的价格便宜、集成度高的优点,又有$E^2PROM$电可擦除重写的特点,且擦除重写的速度快。
(5)固态硬盘(Solid State Drives,SSD)
基于闪存的固态硬盘是用固态电子存储芯片阵列制成的硬盘,由控制单元和存储单元(FLASH 芯片)组成。保留了Flash Memory长期保存信息、快速擦除与重写的特性。对比传统硬盘也具有读写速度快、低功耗的特性,缺点是价格较高。
主存储器的基本组成
图3.7是主存储器(Main Memory,MM)的基本组成框图,其中由一个个存储0或1的记忆单元(也称存储元件)构成的存储矩阵(也称存储体)是存储器的核心部分。记忆单元是具有两种稳态的能表示二进制0和1的物理器件。为了存取存储体中的信息,必须对存储单元编号(也称编址)。编址单位是指具有相同地址的那些存储元件构成的一个单位,可以按字节编址,也可以按字编址。现代计算机通常采用字节编址方式,此时存储体内的一个地址中有1字节。
指令执行过程中需要访问主存时,CPU 首先把被访问单元的地址送到MAR中,然后通过地址线将主存地址送到主存中的地址寄存器,以便地址译码器进行译码选中相应单元,同时CPU将读写信号通过控制线送到主存的读写控制电路。如果是写操作,那么CPU同时将要写的信息送到 MDR中,在读写控制电路的控制下,经数据线将信号写入选中的单元;如果是读操作,那么主存读出选中单元的内容送到数据线,然后送到 MDR 中。数据线的宽度与MDR的苋度相同,地址线的宽度与 MAR 的宽度相同。图3.6采用64位 $\color{green}{\text{数据线}}$ ,所以在按字节编址方式下,每次最多可以存取8个单元的内容。$\color{green}{\text{地址线}}$ 的位数决定了主存地址空间的最大可寻址范围。例如,36位地址的最大寻址范围为0~$2^{36}$-1,即地址从О开始编号。
图片详情
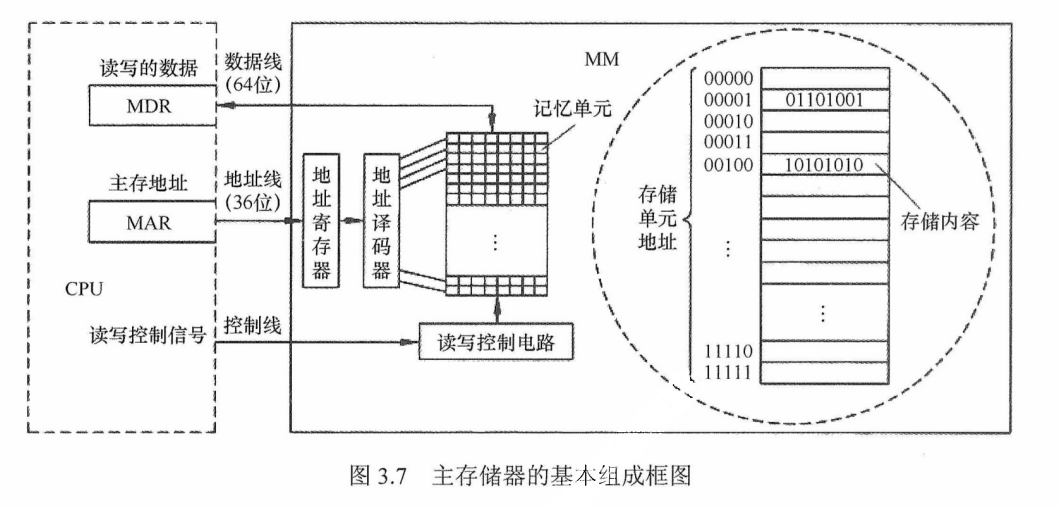
数据线数和地址线数共同反映存储体容量的大小,图3.6中芯片的容量=$2^{36}×64$位。
主存储器与CPU的连接
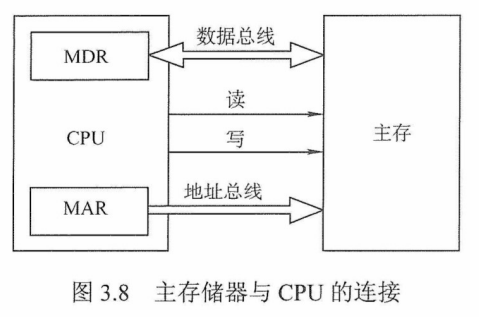
连接原理
1)主存储器通过数据总线、地址总线和控制总线与CPU连接。
2)数据总线的位数与工作频率的乘积正比于数据传输率。
3)地址总线的位数决定了可寻址的最大内存空间。4)控制总线(读/写)指出总线周期的类型和本次输入/输出操作完成的时刻。
主存储器与CPU的连接如图3.8所示。
图片详情
主存容量的扩展
由于单个存储芯片的容量是有限的,它在字数或字长方面与实际存储器的要求都有差距,因此需要在字和位两方面进行扩充才能满足实际存储器的容量要求。通常采用位扩展法、字扩展法和字位同时扩展法来扩展主存容量。
位扩展法
CPU 的数据线数与存储芯片的数据位数不一定相等,此时必须对存储芯片扩位(即进行位扩展,用多个存储器件对字长进行扩充,增加存储字长),使其数据位数与CPU的数据线数相等。位扩展的连接方式是将多个存储芯片的地址端、片选端和读写控制端相应并联,数据端分别引出。
如图3.9所示,用8片8K×1位的RAM芯片组成8K×8位的存储器。8片RAM芯片的地址线$A_{12}\backsim A_0$、$\bar{CS}$、$\bar{WE}$都分别连在一起,每片的数据线依次作为CPU数据线的一位。
图片详情
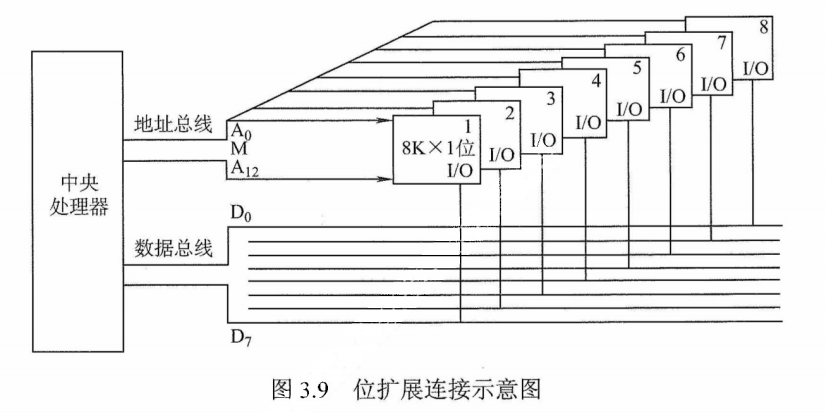
注意:仅采用位扩展时,各芯片连接地址线的方式相同,但连接数据线的方式不同,在某一时刻选中所有的芯片,所以片选信号$\bar{CS}$要连接到所有芯片。
字扩展
字扩展是指增加存储器中字的数量,而位数不变。字扩展将芯片的地址线、数据线、读写控制线相应并联,而由片选信号来区分各芯片的地址范围。
如图3.10所示,用4片16K×8位的RAM芯片组成64K×8位的存储器。4片RAM芯片的数据线$D_0\backsim D_7$和$\bar{WE}$都分别连在一起。将$A_{15}A_{14}$用作片选信号,$A_{15}A_{14}$=00时,译码器输出端0有效,选中最左边的1号芯片;$A_{15}A_{14}$= 01时,译码器输出端1有效,选中2号芯片,以此类推(在同一时间内只能有一个芯片被选中)。各芯片的地址分配如下:
第1片,最低地址:$\mathbf{00}$00000000000000;最高地址:$\mathbf{00}$11111111111111 (16位)
第2片,最低地址:$\mathbf{01}$00000000000000;最高地址:$\mathbf{01}$11111111111111
第3片,最低地址:$\mathbf{10}$00000000000000;最高地址:$\mathbf{10}$11111111111111
第4片,最低地址:$\mathbf{11}$00000000000000;最高地址:$\mathbf{11}$11111111111111
图片详情
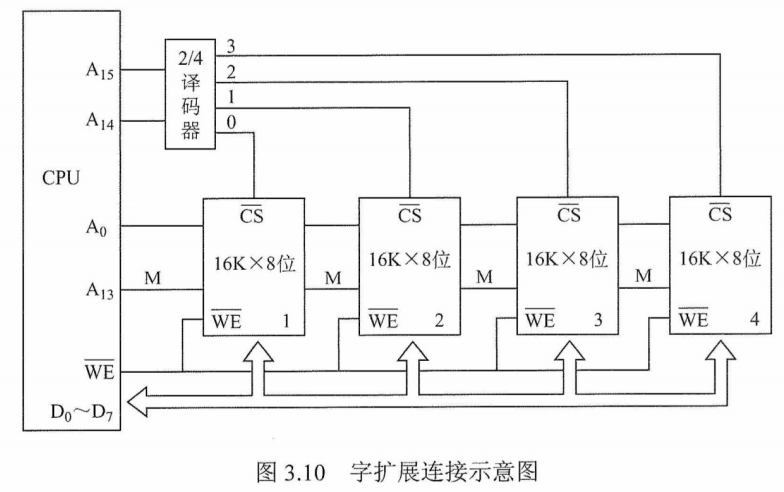
注意:仅采用字扩展时,各芯片连接地址线的方式相同,连接数据线的方式也相同,但在某一时刻只需选中部分芯片,所以通过片选信号$\overline{CS}$或采用译码器设计连接到相应的芯片。
字位同时扩展法
实际上,存储器往往需要同时扩充字和位。字位同时扩展是指既增加存储字的数量,又增加存储字长。
图片详情
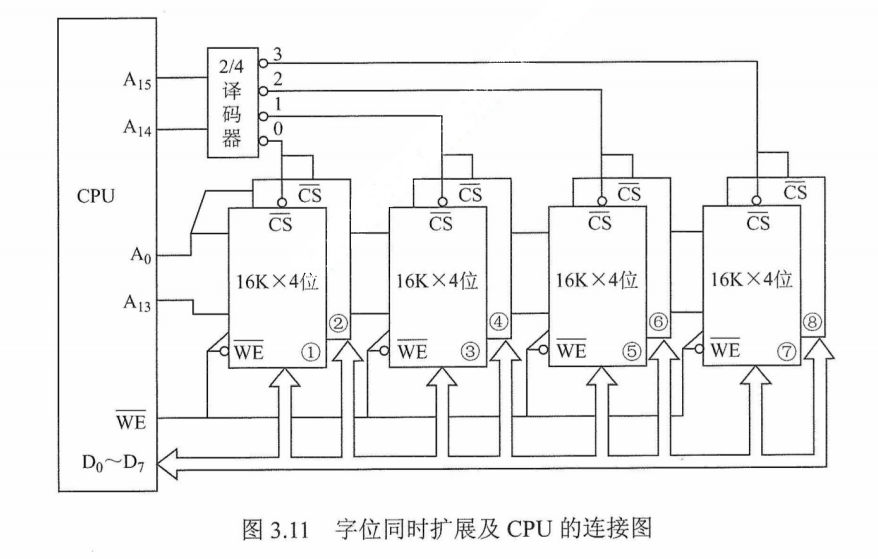
如图3.11所示,用8片16K×4位的 RAM芯片组成64K×8位的存储器。每两片构成一组16K×8位的存储器(位扩展),4组便构成64K×8位的存储器(字扩展)。地址线$A_{15}A_{14}$经译码器得到4个片选信号,$A_{15}A_{14}$ = 00时,输出端0有效,选中第一组的芯片(①和②);$A_{15}A_{14}$ =01时,输出端1有效,选中第二组的芯片(③和④),以此类推。
注意:采用字位同时扩展时,各芯片连接地址线的方式相同,但连接数据线的方式不同,而且需要通过片选信号$\overline{CS}$或采用译码器设计连接到相应的芯片。
存储芯片的地址分配和片选
CPU 要实现对存储单元的访问,首先要选择存储芯片,即进行片选;然后为选中的芯片依地址码选择相应的存储单元,以进行数据的存取,即进行字选。片内的字选通常是由CPU送出的N条低位地址线完成的,地址线直接接到所有存储芯片的地址输入端(N由片内存储容量$2^N$决定)。片选信号的产生分为线选法和译码片选法。
线选法
线选法用除片内寻址外的高位地址线直接(或经反相器)分别接至各个存储芯片的片选端,当某地址线信息为“0”时,就选中与之对应的存储芯片。这些片选地址线每次寻址时只能有一位有效,不允许同时有多位有效,这样才能保证每次只选中一个芯片(或芯片组)。假设4 片2K×8位存储芯片用线选法构成8K×8位存储器,各芯片的片选信号见表3.2,其中低位地址线$A_{10}~A_0$作为字选线,用于片内寻址。
优点:不需要地址译码器,线路简单。缺点:地址空间不连续,选片的地址线必须分时为低电平(否则不能工作),不能充分利用系统的存储器空间,造成地址资源的浪费。
图片详情
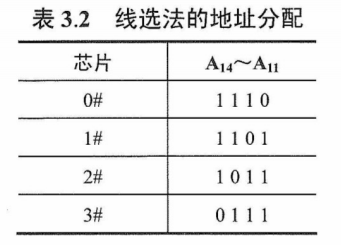
译码片选法
译码片选法用除片内寻址外的高位地址线通过地址译码器芯片产生片选信号。如用8片8K×8位的存储芯片组成64K×8位存储器(地址线为16位,数据线为8位),需要8个片选信号;若采用线选法,除去片内寻址的13位地址线,仅余高3位,不足以产生8个片选信号。因此,采用译码片选法,即用一片74LS138作为地址译码器,则$A_{15}A_{14}A_{13}$ = 000时选中第一片,$A_{15}A_{14}A_{13}$ = 001时选中第二片,以此类推(即3位二进制编码)。
存储器与CPU的连接
合理选择存储芯片
要组成一个主存系统,选择存储芯片是第一步,主要指存储芯片的类型(RAM 或ROM)和数量的选择。通常选用ROM存放系统程序、标准子程序和各类常数,RAM 则是为用户编程而设置的。此外,在考虑芯片数量时,要尽量使连线简单、方便。
地址线的连接
存储芯片的容量不同,其地址线数也不同,而CPU的地址线数往往比存储芯片的地址线数要多。通常将CPU地址线的低位与存储芯片的地址线相连,以选择芯片中的某一单元(字选),这部分的译码是由芯片的片内逻辑完成的。而CPU地址线的高位则在扩充存储芯片时使用,用来选择存储芯片(片选),这部分译码由外接译码器逻辑完成。
例如,设CPU地址线为16位,即$A_{15}~$A_0$$,1K×4位的存储芯片仅有10根地址线,此时可将CPU的低位地址$A_9~A_0$与存储芯片的地址线$A_9~A_0$相连。
数据线的连接
CPU的数据线数与存储芯片的数据线数不一定相等,在相等时可直接相连;在不等时必须对存储芯片扩位,使其数据位数与CPU的数据线数相等。
读/写命令线的连接
CPU读/写命令线一般可直接与存储芯片的读/写控制端相连,通常高电平为读,低电平为写。有些CPU的读/写命令线是分开的(读为$\overline{RD}$,写为$\overline{WE}$,均为低电平有效),此时CPU的读命令线应与存储芯片的允许读控制端相连,而CPU的写命令线则应与存储芯片的允许写控制端相连。
片选线的连接
片选线的连接是CPU与存储芯片连接的关键。存储器由许多存储芯片叠加而成,哪一片被选中完全取决于该存储芯片的片选控制端$\overline{CS}$是否能接收到来自CPU的片选有效信号。
片选有效信号与CPU的访存控制信号$\overline{MREQ}$(低电平有效)有关,因为只有当CPU要求访存时,才要求选中存储芯片。若CPU访问I/O,则$\overline{MREQ}$为高,表示不要求存储器工作。
双端口RAM和多模块存储器
为了提高CPU 访问存储器的速度,可以采用双端口存储器、多模块存储器等技术,它们同属并行技术,前者为空间并行,后者为时间并行。
双端口RAM
双端口RAM是指同一个存储器有左、右两个独立的端口,分别具有两组相互独立的地址线、数据线和读写控制线,允许两个独立的控制器同时异步地访问存储单元,如图3.12所示。当两个端口的地址不相同时,在两个端口上进行读写操作一定不会发生冲突。
两个端口同时存取存储器的同一地址单元时,会因数据冲突造成数据存储或读取错误。两个端口对同一主存操作有以下4种情况:
1)两个端口不同时对同一地址单元存取数据。
2)两个端口同时对同一地址单元读出数据。
3)两个端口同时对同一地址单元写入数据。
4)两个端口同时对同一地址单元操作,一个写入数据,另一个读出数据。
其中,第1)种和第2)种情况不会出现错误;第3)种情况会出现写入错误;第4)种情况会出现读出错误。
解决方法:置“忙”信号$\overline{BUSY}$为0,由判断逻辑决定暂时关闭一个端口(即被延时),未被关闭的端口正常访问,被关闭的端口延长一个很短的时间段后再访问。
图片详情
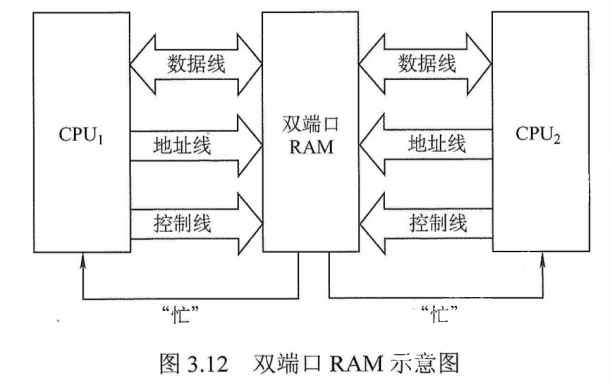
多模块存储器
低位交叉和高位交叉存储器的区别:参考文献
低地址交叉编址相当于—–横着读
高位交叉编址相当于——–竖着读
为提高访存速度,常采用多模块存储器,常用的有单体多字存储器和多体低位交叉存储器。
注意:CPU的速度比存储器的快,若同时从存储器中取出$n$条指令,就可充分利用CPU资源,提高运行速度。多体交叉存储器就是基于这种思想提出的。
单体多字存储器
单体多字系统的特点是存储器中只有一个存储体,每个存储单元存储m个字,总线宽度也为m个字。一次并行读出m个字,地址必须顺序排列并处于同一存储单元。
单体多字系统在一个存取周期内,从同一地址取出m条指令,然后将指令逐条送至CPU执行,即每隔1/m存取周期,CPU向主存取一条指令。显然,这增大了存储器的带宽,提高了单体存储器的工作速度。
缺点:指令和数据在主存内必须是连续存放的,一旦遇到转移指令,或操作数不能连续存放,这种方法的效果就不明显。
多体并行存储器
多体并行存储器由多体模块组成。每个模块都有相同的容量和存取速度,各模块都有独立的读写控制电路、地址寄存器和数据寄存器。它们既能并行工作,又能交叉工作。
多体并行存储器分为高位交叉编址(顺序方式)和低位交叉编址(交叉方式)两种。
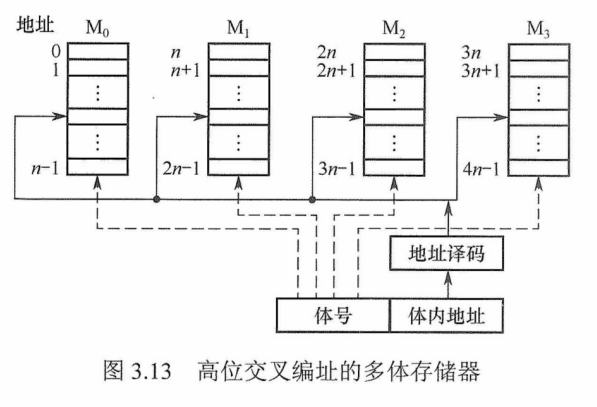
1)高位交叉编址:高位地址表示体号,低位地址为体内地址。如图 3.13所示,存储器共有4个模块$M_0~M_3$,每个模块有n个单元,各模块的地址范围如图中所示。
高位交叉编址方式下,总是把低位的体内地址达到出风也佑问完才转到下一个模块访问,问一个连续主存块时,总是先在一个模块内访问,等到该模块访问完才转到下一个模块访问,CPU总是按顺序访问存储模块,存储模块不能被并行访问,因而不能提高存储器的吞吐率。
注意:模块内的地址是连续的,存取方式仍是串行存取,因此这种存储器仍是顺序存储器。
图片详情
2)低位交叉编址:低位地址为体号,高位地址为体内地址。如图3.14所示,每个模块按“模m”交叉编址,模块号=单元地址%
m,假定m个模块,每个模块有k个单元,则0,m,$\cdots$,$(k-1)m$单元位于$M_0$;第1,m+1,$\cdots$,$(k-1)m+1$单元位于$M_1$;依次类推。
图片详情
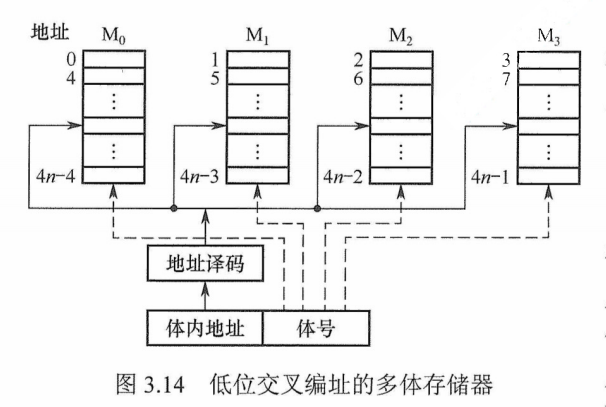
低位交叉编址方式下,总是把高位的体内地址送到由低位体号确定的模块内进行译码。程序连续存放在相邻模块中,因此称采用此编址方式的存储器为交叉存储器。采用低位交叉编址后,可在不改变每个模块存取周期的前提下,采用流水线的方式并行存取,提高存储器的带宽。
设模块字长等于数据总线宽度,模块存取一个字的存取周期为$T$,总线传送周期为$r$,为实现流水线方式存取,存储器交叉模块数应大于等于
$$
m=T/r
$$
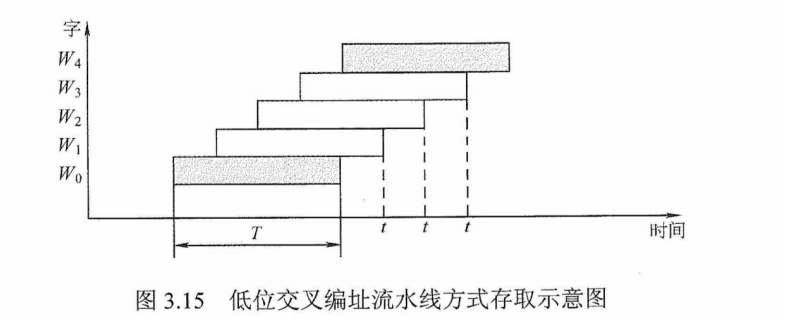
式中,m称为交叉存取度。每经过r时间延迟后启动下一个模块,交叉存储器要求其模块数必须大于等于m,以保证启动某模块后经过m×r的时间后再次启动该模块时,其上次的存取操作已经完成(即流水线不间断)。这样,连续存取m个字所需的时间为
$$
t_1 - T + (m-1)r
$$
而顺序方式连续读取m个字所需的时间为$t_2 = mT$。可见低位交叉存储器的带宽大大提高。模块数为4的流水线方式存取示意图如图3.15所示。
图片详情
多体并行例题

高速缓冲存储器
由于程序的转移概率不会很低,数据分布的离散性较大,所以单纯依靠并行主存系统提高主存系统的频宽是有限的。这就必须从系统结构上进行改进,即采用存储体系。通常将存储系统分为“Cache-主存”层次和“主存-辅存”层次。
- $\color{red}{\text{注意}}$ :Cache是主存的副本
cache中标记项的组成

- 有效位:判断一个缓冲区有效(即存放有数据
- 脏位:跟主存中的内容一不一致
- 替换控制位
程序访问的局部性原理
程序访问的局部性原理包括时间局部性和空间局部性。时间局部性是指在最近的未来要用到的信息,很可能是现在正在使用的信息,因为程序中存在循环。空间局部性是指在最近的未来要用到的信息,很可能与现在正在使用的信息在存储空间上是邻近的,因为指令通常是顺序存放、顺序执行的,数据一般也是以向量、数组等形式簇聚地存储在一起的。
高速缓冲技术就是利用程序访问的局部性原理,把程序中正在使用的部分存放在一个高速的、容量较小的Cache 中,使CPU的访存操作大多数针对Cache进行,从而大大提高程序的执行速度。
局部性比较的例题

Cache 的基本工作原理
Cache位于存储器层次结构的顶层,通常由SR
AM构成,其基本结构如图3.17所示。
图片详情
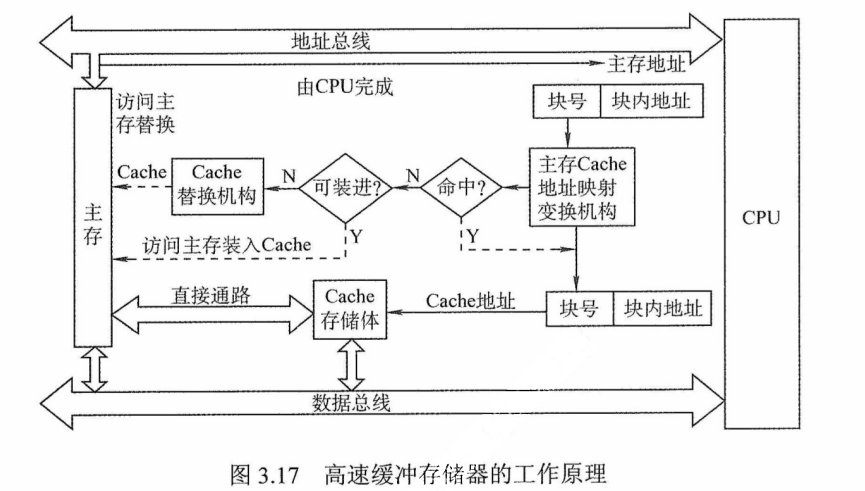
为便于Cache和主存之间交换信息,Cache和主存都被划分为相等的块,Cache块又称Cache 行,每块由若干字节组成,块的长度称为块长(Cache行长)。由于Cache 的容量远小于主存的容量,所以Cache 中的块数要远少于主存中的块数,它仅保存主存中最活跃的若干块的副本。因此Cache 按照某种策略,预测CPU在未来一段时间内欲访存的数据,将其装入Cache。
当CPU发出读请求时,若访存地址在Cache中命中,就将此地址转换成Cache地址,直接对Cache进行读操作,与主存无关;若Cache不命中,则仍需访问主存,并把此字所在的块一次性地从主存调入Cache。若此时Cache已满,则需根据某种替换算法,用这个块替换Cache中原来的某块信息。值得注意的是,CPU与Cache之间的数据交换以字为单位,而Cache 与主存之间的数据交换则以Cache块为单位。
注意:某些计算机中也采用同时访问Cache和主存的方式,若Cache命中,则主存访问终止;否则访问主存并替换Cache。
当CPU发出写请求时,若 Cache命中,有可能会遇到Cache 与主存中的内容不一致的问题。例如,由于CPU 写Cache,把 Cache 某单元中的内容从X修改成了X’,而主存对应单元中的内容仍然是X,没有改变。所以若Cache命中,需要按照一定的写策略处理,常见的处理方法有全写法和写回法,详见本节的Cache 写策略部分。
CPU欲访问的信息已在Cache 中的比率称为Cache的命中率。设一个程序执行期间,Cache的总命中次数为$N_c$,访问主存的总次数为$N_m$,则命中率$H$为
$$
H=N_c/(N_c+N_m)
$$
可见为提高访问效率,命中率$H$越接近1越好。设$t_c$.为命中时的Cache访问时间,$t_m$为未命中时的访问时间,1-H表示未命中率,则Cache-主存系统的平均访问时间$T_a$为
$$
T_a = Ht_c+(1-H)t_m
$$
平均访问时间计算的例题
这里的平均访问时间可以理解为,整个系统消耗在访存上的时间
$\mho$(为什么这里是每8次,一次未命中,而不是每4次)

Cache和主存的映射方式
Cache行中的信息是主存中某个块的副本,地址映射是指把主存地址空间映射到Cache地址空间,即把存放在主存中的信息按照某种规则装入Cache。
由于Cache行数比主存块数少得多,因此主存中只有一部分块的信息可放在 Cache 中,因此在Cache 中要为每块加一个标记,指明它是主存中哪一块的副本。该标记的内容相当于主存中块的编号。为了说明Cache行中的信息是否有效,每个Cache行需要一个有效位。
地址映射的方法有以下3种。
直接映射
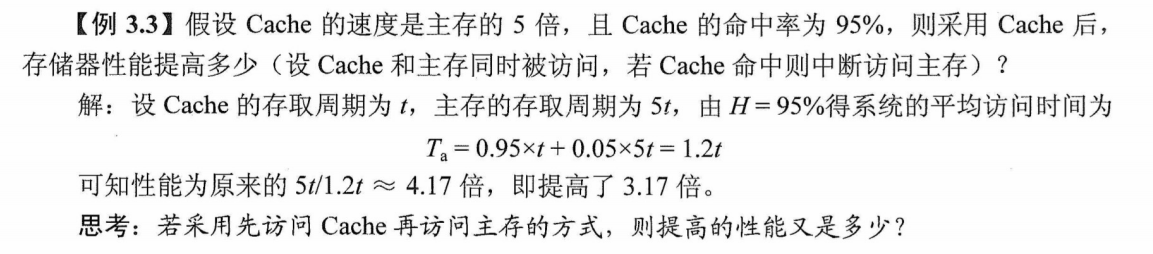
主存中的每一块只能装入Cache 中的唯一位置。若这个位置已有内容,则产生块冲突,原来的块将无条件地被替换出去(无须使用替换算法)。直接映射实现简单,但不够灵活,即使Cache的其他许多地址空着也不能占用,这使得直接映射的块冲突概率最高,空间利用率最低。
直接映射的关系可定义为
$$
j=i mod 2^c
$$
式中,$j$是Cache的块号(又称Cache行号),$i$是主存的块号,$2^c$是Cache中的总块数。在这种映射方式中,主存的第0块、第$2^c+1$块,第$2^{c+1}+1$块$\cdots$只能映射到Cache的第1行,以此类推。由映射函数可看出,主存块号的低$c$位正好是它要装入的Cache行号。给每个Cache行设置一个长为$t=m-c$的标记(tag),当主存某块调入Cache后,就将其块号的高t位设置在对应Cache行的标记中,如图3.18(a)所示。
直接映射的地址结构为
直接映射的地址结构

CPU放存过程如图3.18(b)所示。首先根据访存地址中间的c位,找到对应的Cache行,将对应Cache行中的标记和主存地址的高t位标记进行比较,若相等且有效位为1,则访问Cache“命中”,此时根据主存地址中低位的块内地址,在对应的Cache行中存取信息;若不相等或有效位为0,则“不命中”,此时CPU从主存中读出该地址所在的一块信息送到对应的Cache行中,将有效位置1,并将标记设置为地址中的高t位,同时将该地址中的内容送CPU。
图3.18 图片详情
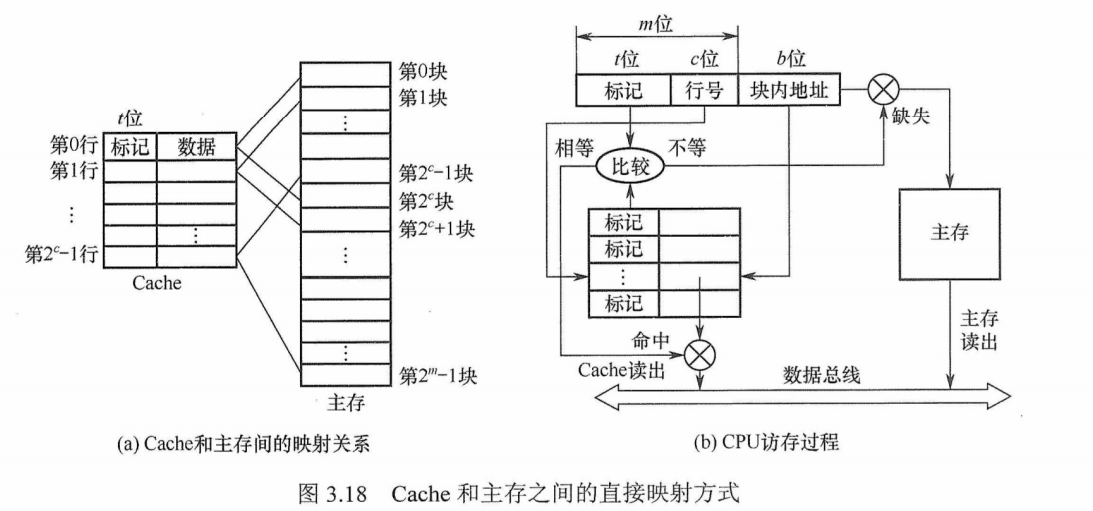
全相联映射
主存中的每一块可以装入Cache 中的任何位置,每行的标记用于指出该行取自主存的哪一块,所以CPU访存时需要与所有Cache行的标记进行比较。全相联映射方式的优点是比较灵活,Cache 块的冲突概率低,空间利用率高,命中率也高;缺点是标记的比较速度较慢,实现成本较高,通常需采用昂贵的按内容寻址的相联存储器进行地址映射,如图3.19所示。
图片详情
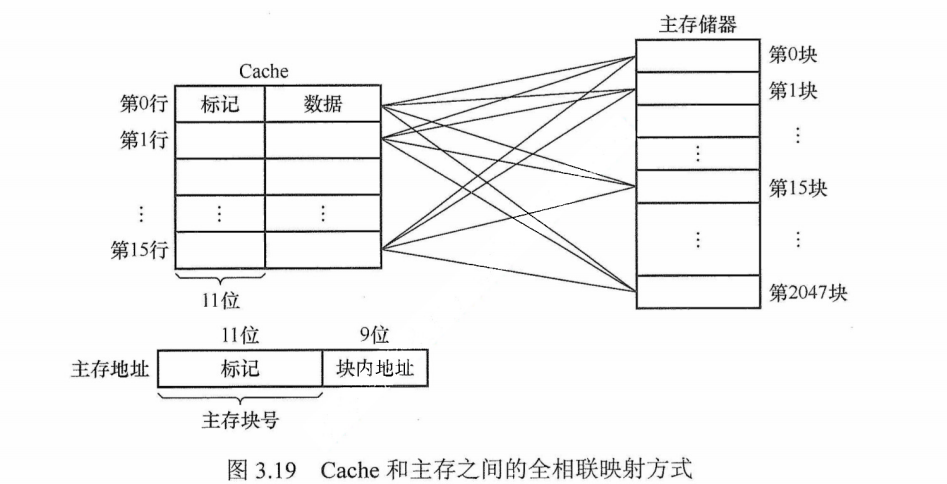
全相联映射的地址结构为
图片详情

相联存储器的特点:根据内容直接访问

组相联映射
- 组间直接相联,组内全相联
- 组内有 $2^r$ 块,cache地址和主存地址相差 $t$ 位,则标记取 $t+r$ 位。
- 如何理解这样拆分之后必然利用了全部的地址位数
- 首先( $\color{green}{\text{组号}}$ + $\color{green}{\text{组内地址}}$ + $\color{red}{\text{组内块号}}$ )= cache地址
- cache地址和主存地址的差,把 $\color{red}{\text{组内块号}}$ 的位数给减了,所以加上 $\color{red}{\text{组内块号}}$ 的位数,刚好为所有地址空间的位数
将Cache 空间分成大小相同的组,主存的一个数据块可以装入一组内的任何一个位置,即组间采取直接映射,而组内采取全相联映射,如图 3.20所示。它是对直接映射和全相联映射的一种折中,当Q= 1时变为全相联映射,当Q = Cache块数时变为直接映射。假设每组有r个Cache行,则称之为r路组相联,图3.20的设置中每组有2个Cache行,因此称为2路组相联。
组相联映射的关系可以定义为
$$
j = i mod Q
$$
式中,j式Cache行的组号,i是主存的块号,Q是Cache的组数。
路数越大,即每组 Cache 行的数量越大,发生块冲突的概率越低,但相联比较电路也越复杂。选定适当的数量,可使组相联映射的成本接近直接映射,而性能上仍接近全相联映射。
组相联映射的地址结构为
- 地址结构各部分的英文为 tag(标记),Index(组号),offset(组内地址)
组相联映射的地址结构

CPU 访存过程如下:首先根据访存地址中间的组号找到对应的Cache组;将对应Cache组中每个行的标记与主存地址的高位标记进行比较;若有一个相等且有效位为1,则访问Cache命中,此时根据主存地址中的块内地址,在对应Cache行中存取信息;若都不相等或虽相等但有效位为0,则不命中,此时CPU 从主存中读出该地址所在的一块信息送到对应Cache 组的任意一个空闲行中,将有效位置1,并设置标记,同时将该地址中的内容送CPU。
图片详情
例题

Cache 中主存块的替换算法
- 直接相联映射不存在需要复杂算法的问题
在采用全相联映射或组相联映射方式时,从主存向Cache传送一个新块,当Cache或Cache组中的空间已被占满时,就需要使用替换算法置换Cache行。而采用直接映射时,一个给定的主存块只能放到唯一的固定Cache行中,所以在对应 Cache 行已有一个主存块的情况下,新的主存块毫无选择地把原先已有的那个主存块替换掉,因而无须考虑替换算法。
常用的替换算法有随机(RAND)算法、先进先出(FIFO)算法、近期最少使用(LRU)算法和最不经常使用(LFU)算法。其中最常考查的是LRU 算法。
1)随机算法:随机地确定替换的Cache块。它的实现比较简单,但未依据程序访问的局部性原理,因此可能命中率较低。
2)先进先出算法:选择最早调入的行进行替换。它比较容易实现,但也未依据程序访问的局部性原理,因为最早进入的主存块也可能是目前经常要用的。
3)近期最少使用算法:依据程序访问的局部性原理,选择近期内长久未访问过的Cache行作为替换的行,平均命中率要比FIFO的高,是堆栈类算法。
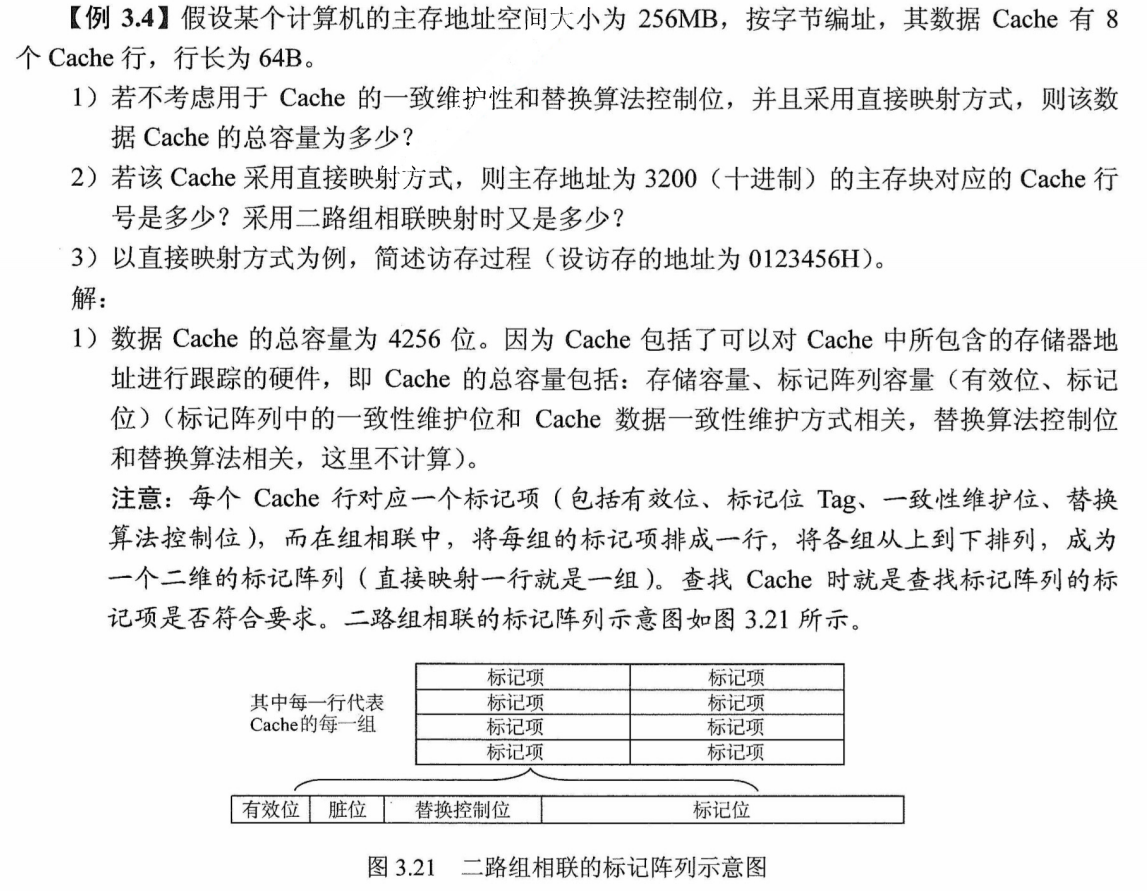
LRU算法对每个Cache行设置一个计数器,用计数值来记录主存块的使用情况,并根据计数值选择淘汰某个块,计数值的位数与Cache组大小有关,2路时有一位LRU位,4路时有两位LRU位。假定采用4路组相联,有5个主存块{1,2,3,4,5}映射到Cache 的同一组,对于主存访问序列{1,2,3,4,1,2,5,1,2,3,4,5},采用LRU算法的替换过程如图3.23所示。图中左边阴
影的数字是对应Cache行的计数值,右边的数字是存放在该行中的主存块号。
图3.23 LRU 算法的替换过程示意图
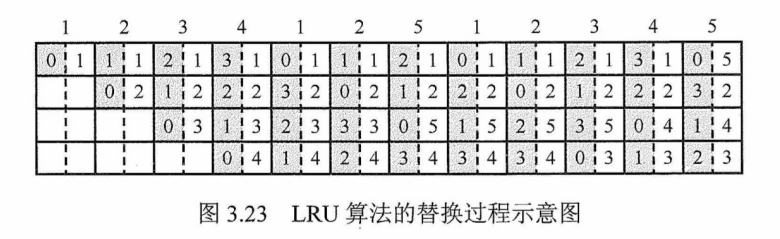
计数器的变化规则:①命中时,所命中的行的计数器清零,比其低的计数器加 1,
其余不
变;②未命中且还有空闲行时,新装入的行的计数器置0,其余全加1;③未命中且无空闲行时,计数值为3的行的信息块被淘汰,新装行的块的计数器置0,其余全加1。
当集中访问的存储区超过Cache 组的大小时,命中率可能变得很低,如上例的访问序列变为1,2,3,4,5,1,2,3,4,5,…,而Cache每组只有4行,那么命中率为0,这种现象称为抖动。
4)最不经常使用算法:将一段时间内被访问次数最少的存储行换出。每行也设置一个计数器,新行建立后从О开始计数,每访问一次,被访问的行计数器加1,需要替换时比较各特定行的计数值,将计数值最小的行换出。这种算法与LRU类似,但不完全相同。
Cache 写策略
因为Cache 中的内容是主存块副本,当对Cache 中的内容进行更新时,就需选用写操作策略使Cache内容和主存内容保持一致。此时分两种情况。
对于Cache 写命中( write hit),有两种处理方法。
1)全写法(写直通法、write-through)。当CPU对Cache写命中时,必须把数据同时写入Cache和主存。当某一块需要替换时,不必把这一块写回主存,用新调入的块直接覆盖即可。这种方法实现简单,能随时保持主存数据的正确性。缺点是增加了访存次数,降低了Cache 的效率。写缓冲:为减少全写法直接写入主存的时间损耗,在Cache和主存之间加一个写缓冲(Write Buffer ),如下图所示。CPU同时写数据到Cache 和写缓冲中,写缓冲再控制将内容写入主存。写缓冲是一个 FIFO 队列,写缓冲可以解决速度不兀配的问题。侣若出现频繁写时.会伸写缓冲饱和溢出。
图片详情
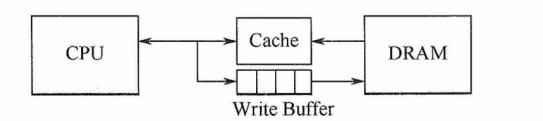
2)写回法 ( write-back)。当CPU对Cache写命中时,只修改Cache的内容,而不立即写入主存,只有当此块被换出时才写回主存。这种方法减少了访存次数,但存在个一致的隐患。采用这种策略时,每个Cache 行必须设置一个标志位(脏位),以反映此块是否被CPU修改过。
全写法和写回法都对应于Cache写命中(要被修改的单元在Cache中)时的情况。
对于Cache 写不命中,也有两种处理方法。
1)写分配法(write-allocate)。加载主存中的块到Cache 中,然后更新这个Cache 块。它试图利用程序的空间局部性,但缺点是每次不命中都需要从主存中读取一块。
2)非写分配法(not-write-allocate)法。只写入主存,不进行调块。
非写分配法通常与全写法合用,写分配法通常和写回法合用。
- $\color{green}{\text{全}}$ 写法: cache命中时,主存和cache $\color{green}{\text{全}}$ 都写入内容
- 写 $\color{green}{\text{分配}}$ 法:cache不命中时, $\color{green}{\text{分配}}$ 到cache中
- $\mho$(为什么这么搭配)
现代计算机的Cache通常设立多级Cache(通常为3级),假定设3级Cache,按离CPU的远近可各自命名为L1 Cache、L2 Cache、L3 Cache,离CPU越远,访问速度越慢,容量越大。指令Cache 与数据Cache分离一般在L1级,此时通常为写分配法与写回法合用。
下图是一个含有两级Cache的系统,L1 Cache对 L2 Cache 使用全写法,L2 Cache对主存使用写回法,由于L2 Cache 的存在,其访问速度大于主存,因此避免了因频繁写时造成的写缓冲饱和溢出。
图片详情

虚拟存储器
- 有效位到底是指存在于磁盘中还是存在于TLB中会发生冲突
主存和联机工作的辅存共同构成了虚拟存储器,二者在硬件和系统软件的共同管理下工作。对于应用程序员而言,虚拟存储器是透明的。虚拟存储器具有主存的速度和辅存的容量,提高了存储系统的性价比。
虚拟存储器的基本概念
虚拟存储器将主存或辅存的地址空间统一编址,形成一个庞大的地址空间,在这个空间内,用户可以自由编程,而不必在乎实际的主存容量和程序在主存中实际的存放位置。
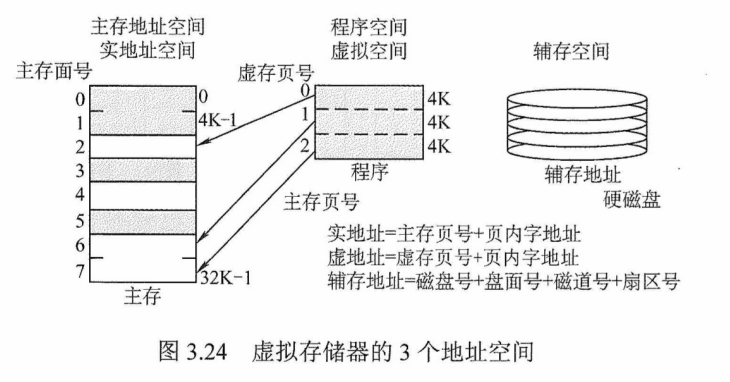
用户编程允许涉及的地址称为虚地址或逻辑地址,虚地址对应的存储空间称为虚拟空间或程序空间。实际的主存单元地址称为实地址或物理地址,实地址对应的是主存地址空间,也称实地址空间。虚地址比实地址要大很多。虚拟存储器的地址空间如图3.24所示。
CPU使用虚地址时,由辅助硬件找出虚地址和实地址之间的对应关系,并判断这个成地址对应的存储单元内容是否已装入主存。若已在主存中,则通过地址变换,CPU 可直接访问主仔指示的实际单元;若不在主存中,则把包含这个字的一页或一段调入主存后再由CPU 访问。右主存已满,则采用替换算法置换主存中的一页或一段。
在实际的物理存储层次上,所编程序和数据在操作系统管理下,先送入磁盘,然后操作系统将当前运行所需要的部分调入主存,供CPU使用,其余暂不运行的部分则留在磁盘中。
虚拟存储器的3个地址空间
页式虚拟存储器
以页为基本单位的虚拟存储器称为页式虚拟存储器。虚拟空间与主存空间都被划分成同样大小的页,主存的页称为实页,虚存的页称为虚页。把虚拟地址分为两个字段:虚页号和页内地址。虚拟地址到物理地址的转换是由页表实现的。页表是一张存放在 $\color{green}{\text{主存}}$ 中的虚页号和实页号的对照表,它记录程序的虚页调入主存时被安排在主存中的位置。页表一般长久地保存在内存中。
页表
图3.25是一个页表示例。 $\color{red}{\text{有效位}}$ 也称 $\color{red}{\text{装入位}}$ ,用来 $\color{green}{\text{表示对应页面是否在主存}}$ ,若为 1,则表示该虚拟页已从外存调入主存,此时页表项存放该页旳物理页号;若为0,则表示没有调入主存,此时页表项可以存放该页的磁盘地址。脏位也称修改位,用来表示页面是否被修改过,虚存机制中采用回写策略,利用脏位可判断替换时是否需要写回磁盘。引用位也称使用位,用来配合替换策略进行设置,例如是否实现最先调入(FIFO位)或最近最少用(LRU位)策略等。
图3.25 主存中的页表示例
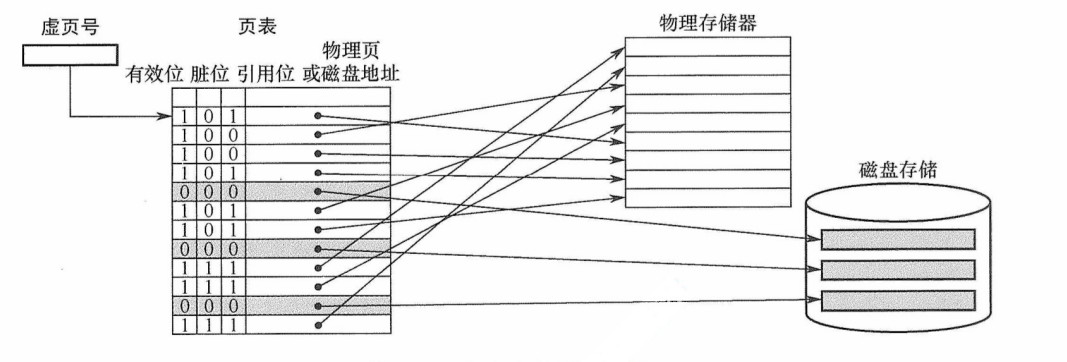
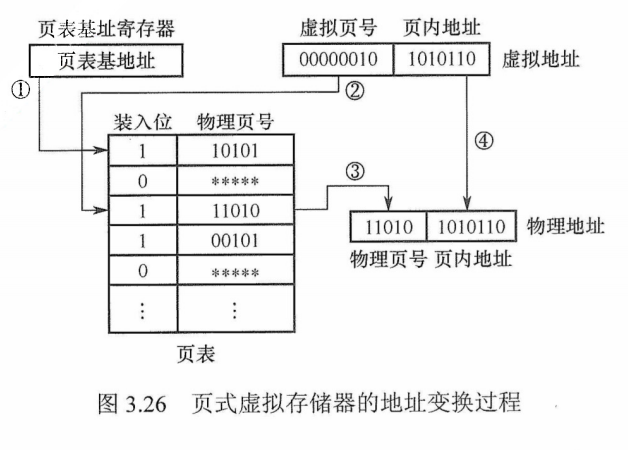
CPU 执行指令时,需要先将虚拟地址转换为主存物理地址。每个进程都有一个 $\color{green}{\text{页表基址寄存器}}$ ,存放该进程的页表首地址,然后根据虚拟地址高位部分的虚拟页号找到对应的页表项,若装入位为1,则取出物理页号,和虚拟地址低位部分的页内地址拼接,形成实际物理地址;若装入位为0,则说明缺页,需要操作系统进行缺页处理。地址变换的过程如图3.26所示。
页式虚拟存储器的优点是,页面的长度固定,页表简单,调入方便。缺点是,由于程序不可能正好是页面的整数倍,最后一页的零头将无法利用而造成浪费,并且页不是逻辑上独立的实体,所以 $\color{green}{\text{处理}}$ 、 $\color{green}{\text{保护}}$ 和 $\color{green}{\text{共享}}$ 都不及段式虚拟存储器方便。
图3.26页式虚拟存储器的地址变换过程
快表(TLB)
由地址转换过程可知,访存时先访问一次主存去查页表,再访问主存才能取得数据。如果缺页,那么还要进行页面替换、页面修改等,因此采用虚拟存储机制后,访问主存的次数更多了。
依据程序执行的局部性原理,在一段时间内总是经常访问某些页时,若把这些页对应的 $\color{green}{\text{页表项存放在高速缓冲器}}$ 组成的 $\color{red}{\text{快表}}$ (TLB)中,则可以明显提高效率。相应地把 $\color{green}{\text{放在主存中的页表}}$ 称为 $\color{red}{\text{慢表}}$ (Page)。在地址转换时,首先查找快表,若命中,则无须访问主存中的页表。
快表通常采用全相联或组相联方式。每个TLB项由页表表项内容加上一个TLB标记字段组成,TLB标记用来表示该表项取自页表中哪个虚页号对应的页表项,因此,TLB标记的内容在全相联方式下就是该页表项对应的虚页号;组相联方式下则是对应虚页号的高位部分,而虚页号的低位部分用于选择TLB组的组索引。
- $\mho$(TLB的全相联和组相联没怎么看懂)
具有TLB和Cache的多级存储系统
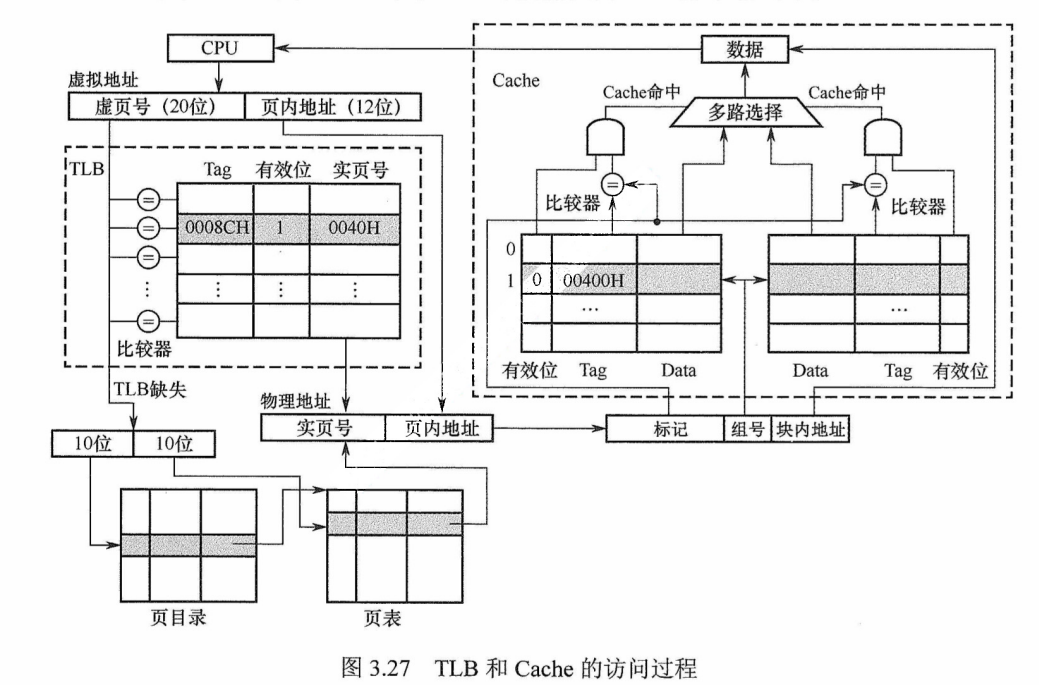
图3.27是一个具有TLB和Cache的多级存储系统,其中Cache 采用二路组相联方式。CPU给出一个32位的虚拟地址,TLB采用全相联方式,每一项都有一个比较器,查找时将虚页号与每个TLB标记字段同时进行比较,若有某一项相等且对应有效位为1,则TLB命中,此时可直接通过TLB进行地址转换;若未命中,则TLB缺失,需要访问主存去查贝表。图中所示的定网级页表方式,虚页号被分成页目录索引和页表索引两部分,由这两部分得到对应的页表项,从而进行地址转换,并将相应表项调入TLB,若 TLB已满,则还需要采用替换策略。完成由虚拟地址到物理地址的转换后,Cache机构根据映射方式将物理地址划分成多个字段,然后根据映射规则找到对应的Cache行或组,将对应Cache行中的标记与物理地址中的高位部分进行比较,若相等且对应有效位为1,则Cache命中,此时根据块内地址取出对应的字送CPU。
图3.27 TLB和 Cache的访问过程
查找时,快表和慢表也可以同步进行,若快表中有此虚页号,则能很快地找到对应的实页号,并使慢表的查找作废,从而就能做到虽采用虚拟存储器但访问主存速度几乎没有下降。
在一个具有Cache和 TLB的虚拟存储系统中,CPU一次访存操作可能涉及TLB、页表、Cache、主存和磁盘的访问,访问过程如图3.28所示。可以看出,CPU访存过程中存在三种缺失情况:①TLB缺失:要访问的页面对应的页表项不在TLB中:②Cache 缺失:要访问的主存块不在Cache 中:③缺页(Page):要访问的页面不在主存中。这三种缺失的几种可能组合情况如表3.3所示。
最好的情况是第1种组合,此时无须访问主存;第2种和第3种组合都需要访问一次主存﹔第4种组合需要访问两次主存;第5种组合发生“缺页异常”,需要访问磁盘,并且至少访问两次主存。Cache 缺失处理由硬件完成;缺页处理由软件完成,操作系统通过“缺页异常处理程序”来实现;而TLB缺失既可以用硬件又可以用软件来处理,比如操作系统有专门的“TLB缺失异常处理”程序。
图3.28 带TLB 虚拟存储器的CPU访存过程
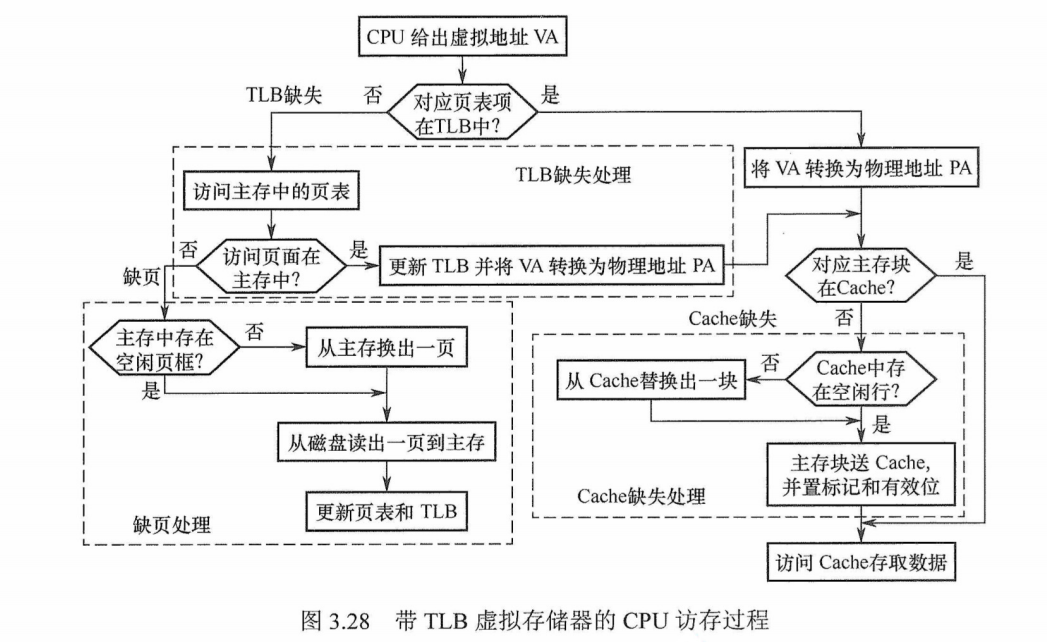
TLB、Page、Cache三种缺失的可能组合情况

段式虚拟存储器
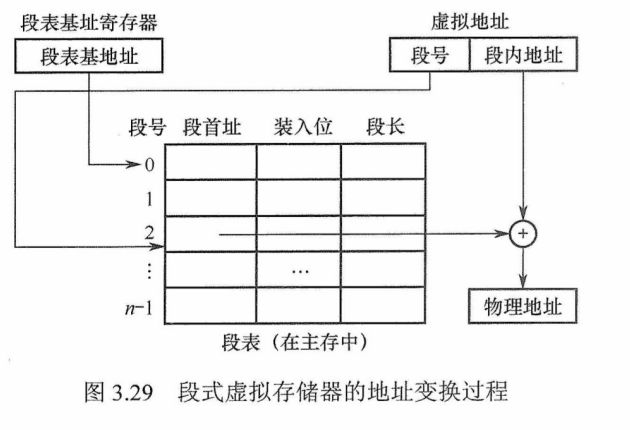
段式虚拟存储器中的段是按程序的逻辑结构划分的,各个段的长度因程序而异。把虚拟地址分为两部分:段号和段内地址。虚拟地址到实地址之间的变换是由段表来实现的。段表是程序的逻辑段和在主存中存放位置的对照表。段表的每行记录与某个段对应的段号、装入位、段起点和段长等信息。由于段的长度可变,所以段表中要给出各段的起始地址与段的长度。
CPU 根据虚拟地址访存时,首先根据段号与段表基地址拼接成对应的段表行,然后根据该段表行的装入位判断该段是否已调入主存(装入位为“1”,表示该段已调入主存;装入位为“0”,表示该段不在主存中)。已调入主存时,从段表读出该段在主存中的起始地址,与段内地址(偏移量)相加,得到对应的主存实地址。段式虚拟存储器的地址变换过程如图3.29所示。
段式虚拟存储器的优点是,段的分界与程序的自然分界相对应,因而具有逻辑独立性,使得它易于编译、管理、修改和保护,也便于多道程序的共享;缺点是因为段长度可变,分配空间不便,容易在段间留下碎片,不好利用,造成浪费。
图3.29段式虚拟存储器的地址变换过程
段页式虚拟存储器
把程序按逻辑结构分段,每段再划分为固定大小的页,主存空间也划分为大小相等的页,程序对主存的调入、调出仍以页为基本传送单位,这样的虚拟存储器称为段页式虚拟存储器。在段页式虚拟存储器中,每个程序对应一个段表,每段对应一个页表,段的长度必须是页长的整数倍,段的起点必须是某一页的起点。
虚地址分为段号、段内页号、页内地址三部分。CPU 根据虚地址访存时,首先根据段号得到段表地址;然后从段表中取出该段的页表起始地址,与虚地址段内页号合成,得到页表地址;最后从页表中取出实页号,与页内地址拼接形成主存实地址。
段页式虚拟存储器的优点是,兼具页式和段式虚拟存储器的优点,可以按段实现共享和保护。缺点是在地址变换过程中需要两次查表,系统开销较大。
虚拟存储器与Cache的比较
虚拟存储器与Cache既有很多相同之处,又有很多不同之处。
相同之处
1)最终目标都是为了提高系统性能,两者都有容量、速度、价格的梯度。
2)都把数据划分为小信息块,并作为基本的传递单位,虚存系统的信息块更大。
3)都有地址的映射、替换算法、更新策略等问题。
4)依据程序的局部性原理应用“快速缓存的思想”,将活跃的数据放在相对高速的部件中
不同之处
Cache主要解决系统速度,而虚拟存储器却是为了解决主存容量。
Cache 全由硬件实现,是硬件存储器,对所有程序员透明;而虚拟存储器由OS和硬件共同实现,是逻辑上的存储器,对系统程序员不透明,但对应用程序员透明。
对于不命中性能影响,因为CPU的速度约为Cache 的10倍,主存的速度为硬盘的100倍以上,因此虚拟存储器系统不命中时对系统性能影响更大。
CPU 与Cache和主存都建立了直接访问的通路,而辅存与CPU没有直接通路。也就是说在Cache不命中时主存能和CPU直接通信,同时将数据调入Cache;而虚拟存储器系统不命中时,只能先由硬盘调入主存,而不能直接和CPU通信。
一道题总结写策略,cache,TLB,页式存储

本章小结
存储器的层次结构主要体现在何处?为何要分这些层次?计算机如何管理这些层次?
存储器的层次结构主要体现在Cache-主存和主存-辅存这两个存储层次上。
Cache-主存层次在存储系统中主要对CPU访存起加速作用,即从整体运行的效果分析,CPU访存速度加快,接近于Cache 的速度,而寻址空间和位价却接近于主存。
主存-辅存层次在存储系统中主要起扩容作用,即从程序员的角度看,他所使用的存储器的容量和位价接近于辅存,而速度接近于主存。
综合上述两个存储层次的作用,从整个存储系统来看,就达到了速度快、容量大、位价低的优化效果。
主存与Cache 之间的信息调度功能全部由硬件自动完成。而主存与辅存层次的调度目前广泛采用虚拟存储技术实现,即将主存与辅存的一部分通过软/硬结合的技术组成虚拟存储器,程序员可用这个比主存实际空间(物理地址空间)大得多的虚拟地址空间(逻辑地址空间)编程,当程序运行时,再由软/硬件自动配合完成虚拟地址空间与主存实际物理空间的转换。因此,这两个层次上的调度或转换操作对于程序员来说都是透明的。
存取周期和存取时间有何区别?
存取周期和存取时间的主要区别是:存取时间仅为完成一次操作的时间;而存取周期不仅包含操作时间,而且包含操作后线路的恢复时间,即存取周期=存取时间+恢复时间。
在虚拟存储器中,页面是设置得大一些好还是设置得小一些好?
页面不能设置得过大,也不能设置得过小。因为页面太小时,平均页内剩余空间较少,可节省存储空间,但会使得页表增大,而且页面太小时不能充分利用访存的空间局部性来提高命中率;页面太大时,可减少页表空间,但平均页内剩余空间较大,会浪费较多存储空间,页面太大还会使页面调入/调出的时间较长。
常见问题和易混淆知识点
存取时间 $T_a$ 就是存储周期 $T_m$ 吗?
不是。存取时间 $T_a$ 是执行一次读操作或写操作的时间,分为读出时间和写入时间。读出时间是从主存接收到有效地址开始到数据稳定为止的时间;写入时间是从主存接收到有效地址开始到数据写入被写单元为止的时间。
存储周期 $T_m$ 是指存储器进行连续两次独立地读或写操作所需的最小时间间隔。所以存取时间 $T_a$ 不等于存储周期 $T_m$ 。通常存储周期 $T_m$ 大于存取时间 $T_a$ 。
Cache行的大小和命中率之间有什么关系?
行的长度较大,可以充分利用程序访问的空间局部性,使一个较大的局部空间被一起调到Cache 中,因而可以增加命中机会。但是,行长也不能太大,主要原因有两个:
1)行长大使失效损失变大。也就是说,若未命中,则需花更多时间从主存读块。
2)行长太大,Cache 项数变少,因而命中的可能性变小。
发生取指令Cache 缺失的处理过程是什么?
1)程序计数器恢复当前指令的值。
2)对主存进行读的操作。
3)将读入的指令写入 Cache 中,更改有效位和标记位。
4)重新执行当前指令。
关于Cache 的一些小知识。
1)多级Cache。现代计算机系统中,一般采用多级的Cache系统。CPU执行指令时,先到速度最快的一级Cache (Ll Cache)中寻找指令或数据,找不到时,再到速度次快的二级Cache (L2 Cache)中找最后到主存中找。
2)指令Cache和数据Cache。指令和数据可以分别存储在不同的Cache中 (L1 Cache一般会这么做),这种结构也称哈佛Cache,其特点是允许CPU在同一个Cache 存储周期内同时提取指令和数据,由于指令执行过程取指和取数据都有可能访问Cache,因此这一特性可以保证不同的指令同时访存。
指令系统
p165
【考纲内容】
(一)指令格式
指令的基本格式
定长操作码指令格式
扩展操作码指令格式
(二)指令的寻址方式
有效地址的概念
数据寻址和指令寻址
常见寻址方式
(三)CISC和 RISC的基本概念
【复习提示】
指令系统是表征一台计算机性能的重要因素。读者应注意扩展操作码技术,各种寻址方式的特点及有效地址的计算,相对寻址有关的计算,CISC与RISC 的特点与区别。本章知识点出选择题的概率较大,但也有可能结合其他章节出有关指令的综合题。2014年、2015年已连续两次出现指令系统和指令流水线的大题。指令系统格式和指令寻址方式与CPU指令执行过程部分紧密结合,希望读者引起重视。
在学习本章时,请读者思考以下问题:
1)什么是指令?什么是指令系统?为什么要引入指令系统?
2)一般来说,指令分为哪些部分?每部分有什么用处?
3)对于一个指令系统来说,寻址方式多和少有什么影响?
请读者在本章的学习过程中寻找答案,本章末尾会给出参考答案。
指令格式
指令(机器指令)是指示计算机执行某种操作的命令。一台计算机的所有指令的集合构成该机的指令系统,也称指令集。 $\color{red}{\text{指令系统}}$ 是计算机的主要属性, $\color{green}{\text{位于硬件和软件的交界面上}}$ 。
指令的基本格式
一条指令就是机器语言的一个语句,它是一组有意义的二进制代码。一条 $\color{red}{\text{指令}}$ 通常包括 $\color{green}{\text{操作码}}$ 字段和 $\color{green}{\text{地址码}}$ 字段两部分:
图片详情

其中,操作码指出指令中该指令应该执行什么性质的操作以及具有何种功能。操作码是识别指令、了解指令功能及区分操作数地址内容的组成和使用方法等的关键信息。例如,指出是算术加运算还是算术减运算,是程序转移还是返回操作。
地址码给出被操作的信息(指令或数据)的地址,包括参加运算的一个或多个操作数所在的地址、运算结果的保存地址、程序的转移地址、被调用的子程序的入口地址等。
指令的长度是指一条指令中所包含的二进制代码的位数。指令字长取决于操作码的长度、操作数地址码的长度和操作数地址的个数。指令长度与机器字长没有固定的关系,它可以等于机器字长,也可以大于或小于机器字长。通常,把指令长度等于机器字长的指令称为 $\color{green}{\text{单字长指令}}$ ,指令长度等于半个机器字长的指令称为 $\color{green}{\text{半字长指令}}$ ,指令长度等于两个机器字长的指令称为 $\color{green}{\text{双字长指令}}$ 。
在一个指令系统中,若所有指令的长度都是相等的,则称为 $\color{green}{\text{定长指令字结构}}$ 。定字长指令的执行速度快,控制简单。若各种指令的长度随指令功能而异,则称为 $\color{green}{\text{变长指令字结构}}$ 。然而,因为主存一般是按字节编址的,所以指令字长多为字节的整数倍。
根据指令中操作数地址码的数目的不同,可将指令分成以下几种格式。
零地址指令
图片详情
只给出操作码OP,没有显式地址。这种指令有两种可能:
1)不需要操作数的指令,如空操作指令、停机指令、关中断指令等。
2)零地址的运算类指令仅用在堆栈计算机中。通常参与运算的两个操作数隐含地从栈顶和次栈顶弹出,送到运算器进行运算,运算结果再隐含地压入堆栈。
一地址指令
图片详情

这种指令也有两种常见的形态,要根据操作码的含义确定究竟是哪一种。
1)只有目的操作数的单操作数指令,按 $A_1$ 地址读取操作数,进行OP操作后,结果存回原地址。
指令含义:$\text{OP}(\text{A}_1) \to \text{A}_1$
如操作码含义是加1、减1、求反、求补等。
2)隐含约定目的地址的双操作数指令,按指令地址A、可读取源操作数,指令可隐含约定另一个操作数由ACC(累加器)提供,运算结果也将存放在ACC中。
指令含义:$\text{(ACC)OP}(\text{A}_1) \to \text{ACC}$
若指令字长为32位,操作码占8位,1个地址码字段占24位,则指令操作数的直接寻址范围为$2^{24}=16\text{M}$
二地址指令
图片详情

指令含义:$(\text{A}_1)\text{OP}(\text{A}_2)\to \text{A}_1$
若指令字长为32位,操作码占8位,两个地址码字段各占12位,则指令操作数的直接寻址范围为$2^{12}=4\text{K}$
三地址指令
图片详情

指令含义:$(\text{A}_1)\text{OP}(\text{A}_2) \to \text{A}_3$
若指令字长为32位,操作码占8位,3个地址码字段各占8位,则指令操作数的直接寻址范围为$2^8=256$若地址字段均为主存地址,则完成一条三地址需要4次访问存储器(取指令1次,取两个操作数2次,存放结果1次)。
四地址指令
图片详情

指令含义:$(\text{A}_1)\text{OP}(\text{A}_2) \to \text{A}_3, \text{A}_4$=下一条将要执行指令的地址。
若指令字长为32位,操作码占8位,4个地址码字段各占6位,则指令操作数的直接寻址范围为$2^6=64$
定长操作码指令格式
定长操作码指令在指令字的最高位部分分配固定的若干位(定长)表示操作码。一般$n$位操作码字段的指令系统最大能够表示$2^n$条指令。定长操作码对于简化计算机硬件设计,提高指令译码和识别速度很有利。当计算机字长为32位或更长时,这是常规用法。
扩展操作码指令格式
为了在指令字长有限的前提下仍保持比较丰富的指令种类,可采取可变长度操作码,即全部指令的操作码字段的位数不固定,且分散地放在指令字的不同位置上。显然,这将增加指令译码和分析的难度,使控制器的设计复杂化。
最常见的变长操作码方法是扩展操作码,它使操作码的长度随地址码的减少而增加,不同地址数的指令可具有不同长度的操作码,从而在满足需要的前提下,有效地缩短指令字长。图4.1所示即为一种扩展操作码的安排方式。
再图4.1中,指令字长为16位,其中4位为基本操作码字段$\text{OP}$,另有3个4位长的地址字段$A_1,A_2\text{和}A_3$。四位操作码若全部用于三地址指令,则有16条。图4.1中所示的三地址指令为15条,1111留作扩展操作码之用;二地址指令为15条,1111 1111留作扩展操作码之用;一地址指令为15条,1111 1111 1111留作扩展操作码之用;零地址指令为16条。
除这种安排外,还有其他多种扩展方法,如形成15条三地址指令、12条二地址指令、63条一地址指令和16条零地址指令,共106条指令,请读者自行分析。
在设计扩展操作码指令格式时,必须注意以下两点:
1)不允许短码是长码的前缀,即短操作码不能与长操作码的前面部分的代码相同。
2)各指令的操作码一定不能重复。通常情况下,对使用频率较高的指令分配较短的操作码,对使用频率较低的指令分配较长的操作码,从而尽可能减少指令译码和分析的时间。
图4.1 扩展操作码技术
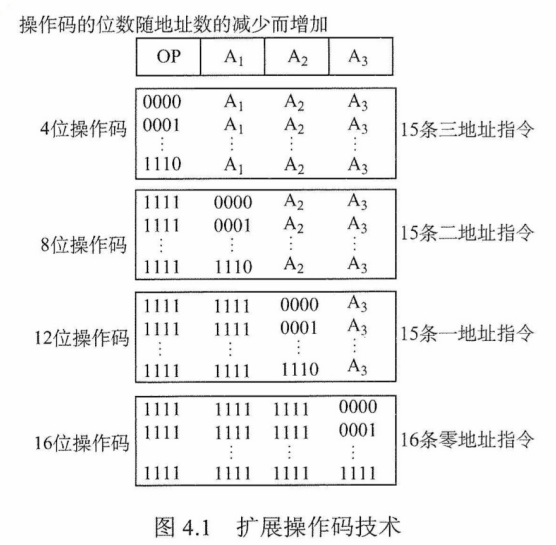
指令的操作类型
设计指令系统时必须考虑应提供哪些操作类型,指令操作类型按功能可分为以下几种。
数据传送
传送指令通常有寄存器之间的传送(MOV)、从内存单元读取数据到CPU寄存器(LOAD)、从CPU寄存器写数据到内存单元(STORE))等。
算术和逻辑运算
这类指令主要有加(ADD)、减(SUB)、比较(CMP)、乘(MUL)、除(DIV)、加1(INC)、减1 (DEC)、与(AND)、或(OR)、取反(NOT)、异或(XOR)等。
移位操作
移位指令主要有算法移位、逻辑移位、循环移位等。
转移操作
转移指令主要有无条件转移(JMP)、条件转移(BRANCH)、调用(CALL )、返回(RET)、陷阱(TRAP)等。无条件转移指令在任何情况下都执行转移操作,而条件转移指令仅在特定条件满足时才执行转移操作,转移条件一般是某个标志位的值,或两个或两个以上的标志位组合。
调用指令和转移指令的区别:执行调用指令时必须保存下一条指令的地址(返回地址),当子程序执行结束时,根据返回地址返回到主程序继续执行;而转移指令则不返回执行。
输入输出操作
这类指令用于完成CPU 与外部设备交换数据或传送控制命令及状态信息。
指令的寻址方式
寻址方式是指寻找指令或操作数有效地址的方式,即确定本条指令的数据地址及下一条待执行指令的地址的方法。寻址方式分为 $\color{green}{\text{指令寻址}}$ 和 $\color{green}{\text{数据寻址}}$ 两大类。
指令中的地址码字段并不代表操作数的真实地址,这种地址称为 $\color{green}{\text{形式地址}}$ (A)。形式地址结合寻址方式,可以计算出操作数在存储器中的真实地址,这种地址称为 $\color{green}{\text{有效地址}}$ (EA)。
注意,(A)表示地址为A的数值,A既可以是寄存器编号,也可以是内存地址。对应的(A)就是寄存器中的数值,或相应内存单元的数值。例如,EA=(A)意思是有效地址是地址A中的数值。
指令寻址和数据寻址
寻址方式分为指令寻址和数据寻址两大类。寻找下一条将要执行的指令地址称为指令寻址;寻找操作数的地址称为数据寻址。
$\color{red}{\text{指令寻址}}$
指令寻址方式有两种:一种是顺序寻址方式,另一种是跳跃寻址方式。
1) $\color{green}{\text{顺序寻址}}$ 可通过程序计数器(PC)加1(1个指令字长),自动形成下一条指令的地址。
2) $\color{green}{\text{跳跃寻址}}$ 通过转移类指令实现。所谓跳跃,是指下条指令的地址码不由程序计数器给出,而由本条指令给出下条指令地址的计算方式。注意,是否跳跃可能受到状态寄存器和操作数的控制,而跳跃到的地址分为绝对地址(由标记符直接得到)和相对地址(相对于当前指令地址的偏移量),跳跃的结果是当前指令修改PC值,所以下一条指令仍然通过程序计数器(PC)给出。
数据寻址
数据寻址是指如何在指令中表示一个操作数的地址,如何用这种表示得到操作数或怎样计算出操作数的地址。
数据寻址的方式较多,为区别各种方式,通常在指令字中设一个字段,用来指明属于哪种寻址方式,由此可得指令的格式如下所示:
图片详情

常见的数据寻址方式
隐含寻址
这种类型的指令不明显地给出操作数的地址,而在指令中隐含操作数的地址。例如,单地址的指令格式就不明显地在地址字段中指出第二操作数的地址,而规定累加器(ACC)作为第二操作数地址,指令格式明显指出的仅是第一操作数的地址。因此,累加器(ACC)对单地址指令格式来说是隐含寻址,如图4.2所示。
隐含寻址的优点是有利于缩短指令字长;缺点是需增加存储操作数或隐含地址的硬件。
图片详情
立即(数)寻址
这种类型的指令的地址字段指出的不是操作数的地址,而是操作数本身,又称立即数。数据采用补码形式存放。图4.3所示为立即寻址示意图,图中#表示立即寻址特征,A就是操作数本身。
立即寻址的优点是指令在执行阶段不访问主存,指令执行时间最短;缺点是A 的位数限制了立即数的范围。
立即(数)寻址
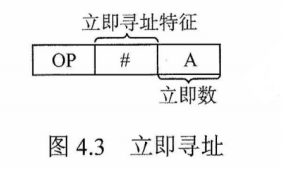
直接寻址
指令字中的形式地址A是操作数的真实地址:EA,即EA=A,如图4.4所示。
直接寻址
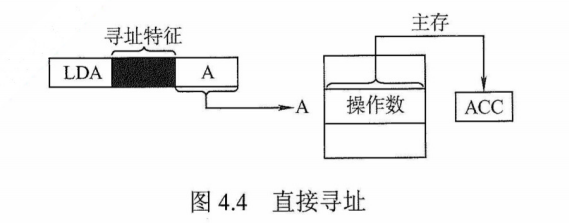
直接寻址的优点是简单,指令在执行阶段仅访问一次主存,不需要专门计算操作数的地址;缺点是A的位数决定了该指令操作数的寻址范围,操作数的地址不易修改。
间接寻址
间接寻址是相对于直接寻址而言的,指令的地址字段给出的形式地址不是操作数的真正地址,而是操作数有效地址所在的存储单元的地址,也就是操作数地址的地址,即 EA =(A),如图4.5所示。间接寻址可以是一次间接寻址,还可以是多次间接寻址。
图片详情
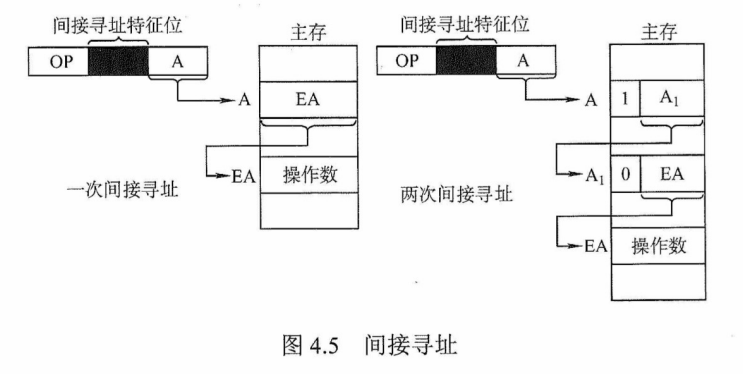
在图4.5中,主存字第一位为1时,表示取出的仍不是操作数的地址,即多次间址;主存字第一位为0时,表示取得的是操作数的地址。
间接寻址的优点是可扩大寻址范围(有效地址EA 的位数大于形式地址A的位数),便于编制程序(用间接寻址可方便地完成子程序返回);缺点是指令在执行阶段要多次访存(一次间接寻址需两次访存,多次间接寻址需根据存储字的最高位确定访存次数)。由于访问速度过慢,这种寻址方式并不常用。一般问到扩大寻址范围时,通常指的是寄存器间接寻址。
寄存器寻址
寄存器寻址是指在指令字中直接给出操作数所在的寄存器编号,即EA = $R_i$,其操作数在由R;所指的寄存器内,如图4.6所示。
寄存器寻址的优点是指令在执行阶段不访问主存,只访问寄存器,因寄存器数量较少,对应地址码长度较小,使得指令字短且因不用访存,所以执行速度快,支持向量/矩阵运算;缺点是寄存器价格昂贵,计算机中的寄存器个数有限。
图片详情
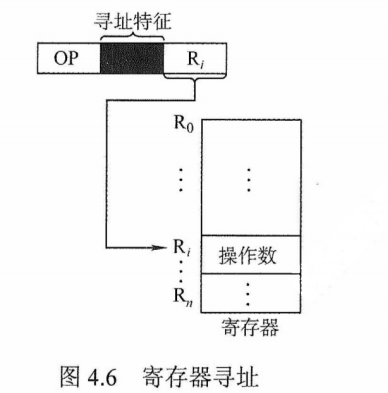
寄存器间接寻址
寄存器间接寻址是指在寄存器$R_i$中给出的不是一个操作数,而是操作数所在主存单元的地址,即 EA=($R_i$),如图4.7所示。
图片详情
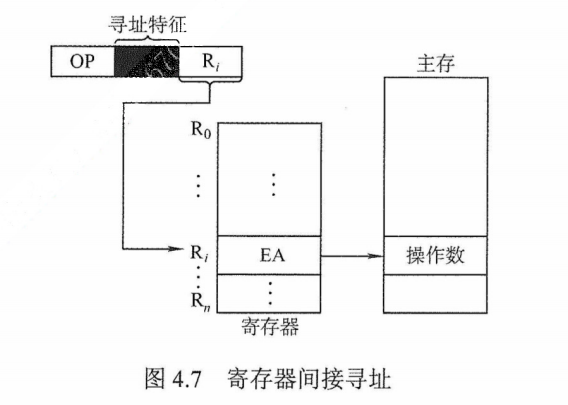
寄存器间接寻址的特点是,与一般间接寻址相比速度更快,但指令的执行阶段需要访问主存(因为操作数在主存中)。
相对寻址
相对寻址是把程序计数器(PC)的内容加上指令格式中的形式地址A而形成操作数的有效地址,即 EA= (PC)+A,其中A是相对于当前指令地址的位移量,可正可负,补码表示,如图4.8所示。
在图4.8中,A的位数决定操作数的寻址范围。
相对寻址的优点是操作数的地址不是固定的,它随PC值的变化而变化,且与指令地址之间总是相差一个固定值,因此便于程序浮动。相对寻址广泛应用于转移指令。
图片详情
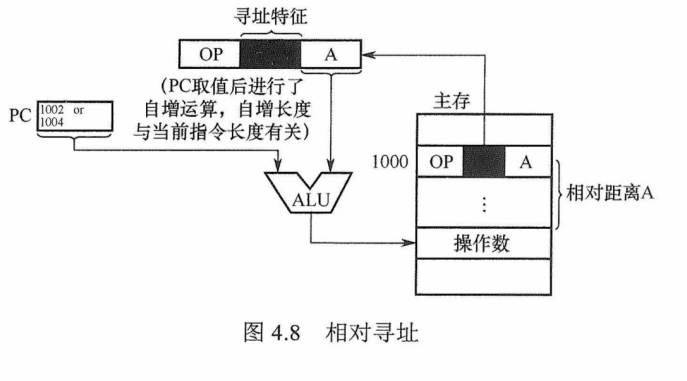
注意,对于转移指令JMP A,当CPU从存储器中取出一字节时,会自动执行(PC)+1→PC。若转移指令的地址为X,且占2B,在取出该指令后,PC的值会增2,即$(\text{PC})=X+1$,这样在执行完该指令后,会自动跳转到$\text{X+2+A}$的地址继续执行。
基址寻址
基址寻址是指将CPU 中基址寄存器(BR)的内容加上指令格式中的形式地址A而形成操作数的有效地址,即EA =(BR)+ A。其中基址寄存器既可采用专用寄存器,又可采用通用寄存器,如图4.9所示。
图片详情
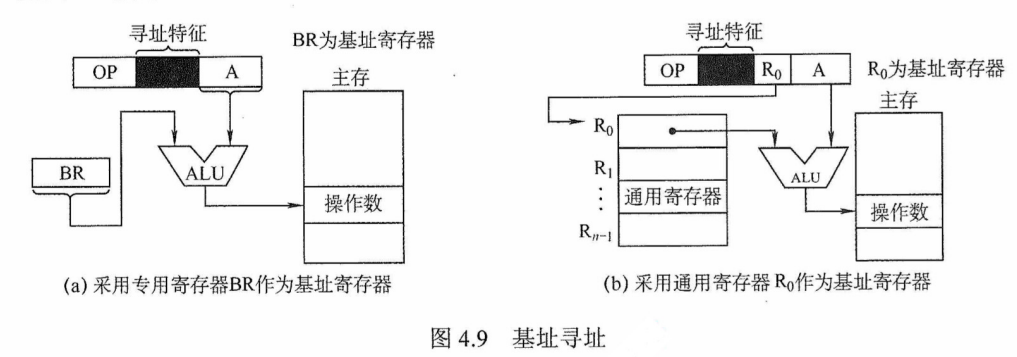
基址寄存器是面向操作系统的,其内容由操作系统或管理程序确定,主要用于解决程序逻辑空间与存储器物理空间的无关性。在程序执行过程中,基址寄存器的内容不变(作为基地址),形式地址可变(作为偏移量)。采用通用寄存器作为基址寄存器时,可由用户决定哪个寄存器作为基址寄存器,但其内容仍由操作系统确定。
基址寻址的优点是可扩大寻址范围(基址寄存器的位数大于形式地址A的位数);用户不必考虑自己的程序存于主存的哪个空间区域,因此有利于多道程序设计,并可用于编制浮动程序,但偏移量(形式地址A)的位数较短。
变址寻址
变址寻址是指有效地址EA 等于指令字中的形式地址A与变址寄存器IX的内容之和,即EA = (IX)+ A,其中为变址寄存器(专用),也可用通用寄存器作为变址寄存器。图4.10所示为采用专用寄存器IX的变址寻址示意图。
变址寄存器是面向用户的,在程序执行过程中,变址寄存器的内容可由用户改变(作为偏移量),形式地址A不变(作为基地址)。
变址寻址的优点是可扩大寻址范围(变址寄存器的位数大于形式地址A的位数);在数组处理过程中,可设定A 为数组的首地址,不断改变变址寄存器IX的内容,便可很容易形成数组中任一数据的地址,特别适合编制循环程序。偏移量(变址寄存器IX)的位数足以表示整个存储空间。
显然,变址寻址与基址寻址的有效地址形成过程极为相似。但从本质上讲,两者有较大区别。基址寻址面向系统,主要用于为多道程序或数据分配存储空间,因此基址寄存器的内容通常由操作系统或管理程序确定,在程序的执行过程中其值不可变,而指令字中的A是可变的;变址寻址立足于用户,主要用于处理数组问题,在变址寻址中,变址寄存器的内容由用户设定,在程序执行过程中其值可变,而指令字中的A是不可变的。
图片详情
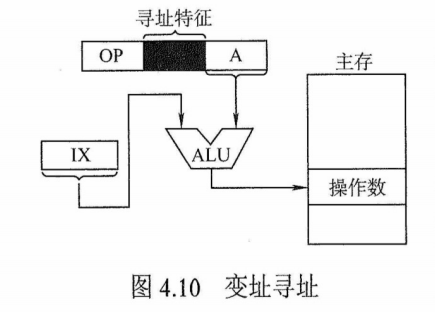
堆栈寻址
堆栈是存储器(或专用寄存器组)中一块特定的、按后进先出(LIFO)原则管理的存储区,该存储区中读/写单元的地址是用一个特定的寄存器给出的,该寄存器称为堆栈指针(SP)。 $\color{red}{\text{堆栈}}$ 可分为 $\color{green}{\text{硬堆栈}}$ 与 $\color{green}{\text{软堆栈}}$ 两种。
寄存器堆栈又称硬堆栈。寄存器堆栈的成本较高,不适合做大容量的堆栈;而从主存中划出一段区域来做堆栈是最合算且最常用的方法,这种堆栈称为软堆栈。
在采用堆栈结构的计算机系统中,大部分指令表面上都表现为无操作数指令的形式,因为操作数地址都隐含使用了SP。通常情况下,在读/写堆栈中的一个单元的前后都伴有自动完成对SP内容的增量或减量操作。
下面简单总结寻址方式、有效地址及访存次数(不包含为了取本条指令而做的访存),见表4.1。
图片详情
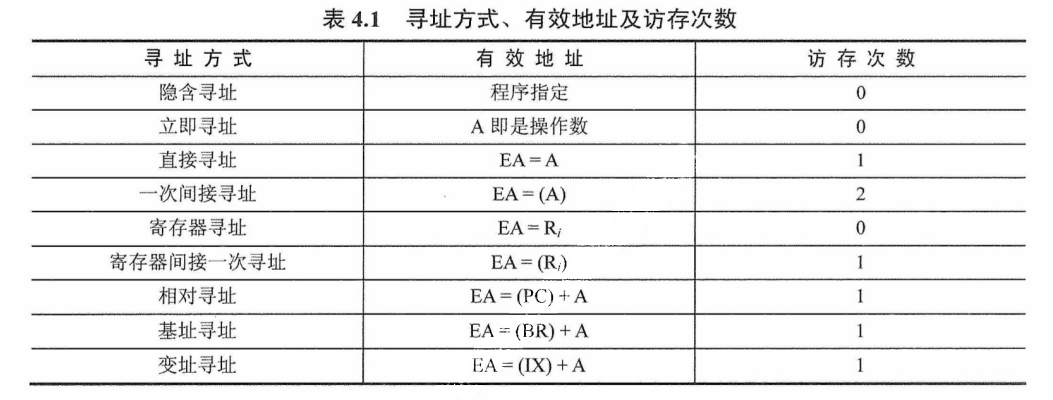
- $\mho$(为什么隐含寻址的访存次数是0,他不是向 $\color{green}{\text{内存}}$ 取操作数就算一次访存吗,否则变址寻址这些凭什么是1次)
X86汇编指令入门
近几年的408真题频繁涉及X86汇编指令和机器代码相关的知识,这部分内容并不在考纲范围内,但如果对汇编知识和程序在机内执行的原理毫无了解,那么解题可能会难以下手。
相关寄存器
X86处理器中有8个32位的通用寄存器,各寄存器及说明如图4.11所示。为了向后兼容,EAX、EBX、ECX和 EDX 的高两位字节和低两位字节可以独立使用,E为Extended,表示32位的寄存器。例如,EAX的低两位字节称为AX,而AX的高低字节又可分别作为两个8位寄存器,分别称为AH和AL。寄存器的名称与大小写无关,既可以用EAX,又可以用eax。
图片详情
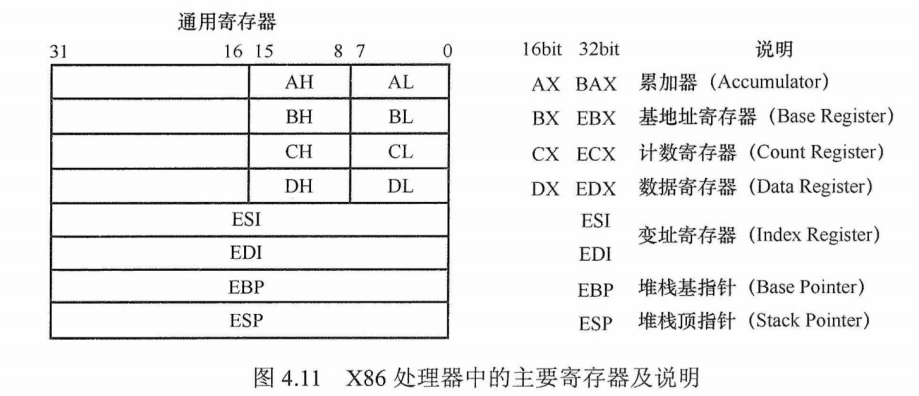
- $\blacktriangleright$(图中的BAX应该是EAX吧)
除EBP和 ESP外,其他几个寄存器的用途是比较任意的。
寻址模式和内存分配
1)寻址模式
X86提供了一种灵活的内存寻址方式,这里以mov指令为例。mov用于在内存和寄存器之间移动数据,它有两个参数:第一个是目的地址,第二个是源地址。
下面的例子是汇编程序中常见的方式:
代码详情
1 | mov eax, [ebx] ;将ebx值指示的内存地址中的4字节传送到eax |
最多只能利用两个32位寄存器和一个32位的有符号常数相加计算出一个内存地址,下面是两个违反规则的例子:
代码详情
1 | mov eax, [ebx-ecx] ;错误,只能用加法 |
2)数据类型长度规定
在汇编语言中声明内存大小时,一般显式地使用DB(字母D表示 Data,字母B表示Byte)、DW(字母W表示Word,2Bytes)和DD(第二个字母D表示Double Word,4Bytes),这样就能很好地指导编译器分配内存空间,但是对于
代码详情
1 | mov [ebx], 2; |
若无特殊标识,则不确定常数⒉是单字节、双字节还是双字。对于这种情况,X86提供了三个指示规则标记,分别为BYTE PTR、WORD PTR和 DWORD PTR,如将上例写成
代码详情
1 | mov byte ptr [ebx],2 ;将2以单字节形式传送到ebx值指示的内存地址中 |
常用指令
汇编指令通常可以分为数据传送指令、逻辑计算指令和控制流指令,本节将讲述其中最重要的指令。以下用于操作数的标记分别表示寄存器、内存和常数。
<reg>:表示任意寄存器,若其后带有数字,则指定其位数,如<reg32>表示32位寄存器(EAX、EBX、ECX、EDX、ESI、EDI、ESP或EBP);<reg16>表示16位寄存器(AX、 BX、CX或 DX);<reg8>表示8位寄存器(AH、AL、BH、BL、CH、CL、DH、DL )。
<mem>:表示内存地址(如[ eax ]、[ var+4 ]或dword ptr [ eax+ebx ])。
<con>:表示8位、16位或32位常数。<con8>表示8位常数;<con16>表示16位常数;<con32>表示32位常数。(constant)
X86中的指令机器码长度为1字节,对同一指令的不同用途有多种编码方式,比如 mov指令就有28种机内编码,用于不同操作数类型或用于特定寄存器,例如,
代码详情
1 | mov ax,<con16>;机器码为B8H |
数据传送指令
mov指令
mov指令将第二个操作数(寄存器的内容、内存中的内容或常数值)复制到第一个操作数(寄存器或内存)。但不能用于直接从内存复制到内存,其语法如下:
代码详情
1 | mov <reg>,<reg> |
举例:
代码详情
1 | mov eax, ebx;将ebx值复制到eax |
push指令
push 指令将操作数压入内存的栈,常用于函数调用。ESP是栈顶,压栈前先将 $\color{green}{\text{ESP值减4}}$ (栈增长方向与内存地址增长方向相反),然后将操作数压入ESP指示的地址。其语法如下:
代码详情
1 | push <reg32> |
举例(注意, $\color{green}{\text{栈中元素固定为32位}}$ ):
代码详情
1 | push eax;将eax值压栈 |
pop指令
与push指令相反,pop 指令执行的是出栈工作,出栈前先将ESP指示的地址中的内容出栈,然后将ESP值加4。其语法如下:
代码详情
1 | pop edi ;弹出栈顶元素送到edi |
算术和逻辑运算指令
add/sub指令
add指令将两个操作数相加,相加的结果保存到第一个操作数中。sub指令用于两个操作数相减,相减的结果保存到第一个操作数中。它们的语法格式类似,语法如下:
代码详情
1 | add <reg>,<reg> / sub <reg>,<reg> |
举例:
代码详情
1 | sub eax, 10;eaxeax-10 |
inc/dec指令
inc、dec指令分别表示将操作数自加1、自减1,其语法如下:
代码详情
1 | inc <reg> / dec <reg> |
举例
代码详情
1 | dec eax; eax值自减1 |
imul指令
带符号整数乘法指令,它有两种格式:①两个操作数,将两个操作数相乘,并将结果保存在第一个操作数中,第一个操作数必须为寄存器;②三个操作数,将第二个和第三个操作数相乘,并将结果保存在第一个操作数中,第一个操作数必须为寄存器。其语法如下:
代码详情
1 | imul <reg32>,<reg32> |
举例:
代码详情
1 | imul eax, [var];eaxeax*[var] |
乘法操作结果可能溢出,则编译器置溢出标志OF=1,以使CPU调出溢出异常处理程序。
idiv指令
idiv是带符号整数除法指令,它只有一个操作数,即除数,而被除数则为edx:eax 中的内容(64位整数),操作结果有两部分:商和余数,商送到eax,余数则送到edx。其语法如下:
代码详情
1 | idiv <reg32> |
举例:
代码详情
1 | idiv ebx |
and/or/xor指令
and、or、xor指令分别是逻辑与、逻辑或、逻辑异或操作指令,用于操作数的位操作,操作结果放在第一个操作数中。其语法如下:
代码详情
1 | and <reg>,<reg> / or <reg>,<reg> / xor <reg>,<reg> |
举例:
代码详情
1 | and eax,OfH;将eax中的前28位全部置为0,最后4位保持不变 |
not指令
not指令是位翻转指令,将操作数中的每一位翻转,即0→1、1→0。其语法如下:
代码详情
1 | not<reg> |
举例:
代码详情
1 | not byte ptr [var];将var值指示的内存地址的一字节的所有位翻转 |
neg指令
neg是取负指令。其语法如下:
代码详情
1 | neg <reg> |
举例:
代码详情
1 | neg eax ;eax <- -eax |
shl/shr指令
shl、shr是逻辑移位指令,shl为逻辑左移,shr为逻辑右移,第一个操作数表示被操作数,第二个操作数指示移位的位数。其语法如下:
代码详情
1 | shl <reg>,<con8> / shr <reg>,<con8> |
举例:
代码详情
1 | shl eax,1;将eax值左移1位,相当于乘以2 |
控制流指令
X86 处理器维持着一个指示当前执行指令的指令指针(P),当一条指令执行后,此指针自动指向下一条指令。IP寄存器不能直接操作,但可以用控制流指令更新。通常用标签(label)指示程序中的指令地址,在X86汇编代码中,可在任何指令前加入标签。例如,
代码详情
1 | mov esi, [ebp+8] |
这样就用begin指示了第二条指令,控制流指令通过标签就可以实现程序指令的跳转。
jmp指令
jmp指令控制I转移到label所指示的地址(从label中取出指令执行)。其语法如下:
代码详情
1 | jmp <label> |
举例:
代码详情
1 | jmp begin ;转跳到begin标记的指令执行 |
jcondition指令
条件转移指令,它依据处理机状态字中的一系列条件状态转移。处理机状态字中包括指示最后一个算术运算结果是否为0,运算结果是否为负数等。其语法如下:
代码详情
1 | je <label> (jump when equal) |
举例:
代码详情
1 | cmp eax, ebx |
cmp指令
cmp 指令用于比较两个操作数的值,并根据比较结果设置处理机状态字中的条件码。其语法如下:
代码详情
1 | cmp <reg>,reg> |
cmp指令通常和jcondition指令搭配使用,举例:
代码详情
1 | cmp dword ptr [var],10 |
call/ret指令
call 和 ret这两条指令分别实现子程序(过程、函数等)的调用及返回。call 指令首先将当前执行指令地址入栈,然后无条件转移到由标签指示的指令。与其他简单的跳转指令不同,call指令保存调用之前的地址信息(当call 指令结束后,返回调用之前的地址)。ret指令实现子程序的返回机制,ret 指令弹出栈中保存的指令地址,然后无条件转移到保存的指令地址执行。call和ret是函数调用中最关键的两条指令,其语法如下:
代码详情
1 | call <label> |
理解上述指令的语法和用途,可以更好地帮助读者解答相关题型。汇编语言虽不在考纲范围,但计算机组成原理是一门和硬件紧密关联的学科,涉及编译、指令、内存、处理机等方方面面。读者在上机调试℃程序代码时,也可以尝试用编译器调试,以便更好地帮助理解机器指令的执行,这也从侧面说明了408真题越来越重视考查学生的综合能力。
CISC和 RISC的基本概念
指令系统朝两个截然不同的方向的发展:一是增强原有指令的功能,设置更为复杂的新指令实现软件功能的硬化,这类机器称为复杂指令系统计算机(CISC),典型的有采用X86架构的计算机;二是减少指令种类和简化指令功能,提高指令的执行速度,这类机器称为精简指令系统计算机(RISC),典型的有ARM、MIPS 架构的计算机。
复杂指令系统计算机(CISC)
随着VLSI 技术的发展,硬件成本不断下降,软件成本不断上升,促使人们在指令系统中增加更多、更复杂的指令,以适应不同的应用领域,这样就构成了复杂指令系统计算机(CISC)。
CISC的主要特点如下:
1)指令系统复杂庞大,指令数目一般为200条以上。
2) $\color{green}{\text{指令的长度不固定}}$,指令格式多,寻址方式多。
3)可以访存的指令不受限制。
4)各种指令使用频度相差很大。
5)各种指令执行时间相差很大,大多数指令需多个时钟周期才能完成。
6)控制器大多数采用微程序控制。有些指令非常复杂,以至于无法采用硬连线控制。
7)难以用优化编译生成高效的目标代码程序。
如此庞大的指令系统,对指令的设计提出了极高的要求,研制周期变得很长。后来人们发现,一味地追求指令系统的复杂和完备程度不是提高计算机性能的唯一途径。对传统CISC指令系统的测试表明,各种指令的使用频率相差悬殊,大概只有20%的比较简单的指令被反复使用,约占整个程序的80%;而 80%左右的指令则很少使用,约占整个程序的20%。从这一事实出发,人们开始了对指令系统合理性的研究,于是 RISC随之诞生。
精简指令系统计算机(RISC)
精简指令系统计算机(RISC)的中心思想是要求指令系统简化,尽量使用寄存器-寄存器操作指令,指令格式力求一致。RISC的主要特点如下:
1)选取使用频率最高的一些简单指令,复杂指令的功能由简单指令的组合来实现。
2) $\color{green}{\text{指令长度固定}}$ ,指令格式种类少,寻址方式种类少。
3)只有Load/Store(取数/存数)指令访存,其余指令的操作都在寄存器之间进行。
4)CPU中通用寄存器的数量相当多。
5)RISC一定采用指令流水线技术,大部分指令在一个时钟周期内完成。
6)以硬布线控制为主,不用或少用微程序控制。
7)特别重视编译优化工作,以减少程序执行时间。
值得注意的是,从指令系统兼容性看,CISC大多能实现软件兼容,即高档机包含了低档机的全部指令,并可加以扩充。但RISC简化了指令系统,指令条数少,格式也不同于老机器,因此大多数RISC机不能与老机器兼容。由于 RISC具有更强的实用性,因此应该是未来处理器的发展方向。但事实上,当今时代Intel 几乎一统江湖,且早期很多软件都是根据CISC 设计的,单纯的RISC将无法兼容。此外,现代CISC结构的CPU已经融合了很多RISC的成分,其性能差距已经越来越小。CISC可以提供更多的功能,这是程序设计所需要的。
CISC和 RISC的比较
和 CISC相比,RISC的优点主要体现在以下几点:
1)RISC 更能充分利用VLSI芯片的面积。CISC的控制器大多采用微程序控制,其控制存储器在CPU芯片内所占的面积达50%以上,而RISC控制器采用组合逻辑控制,其硬布线逻辑只占CPU芯片面积的10%左右。
2)RISC 更能提高运算速度。RISC 的指令数、寻址方式和指令格式种类少,又设有多个通用寄存器,采用流水线技术,所以运算速度更快,大多数指令在一个时钟周期内完成
3)RISC便于设计,可降低成本,提高可靠性。RISC指令系统简单,因此机器设计周期短;其逻辑简单,因此可靠性高。
4)RISC有利于编译程序代码优化。RISC 指令类型少,寻址方式少,使编译程序容易选择更有效的指令和寻址方式,并适当地调整指令顺序,使得代码执行更高效化。
CISC和 RISC的对比见表4.2。
4.2 CISC和 RISC的比较
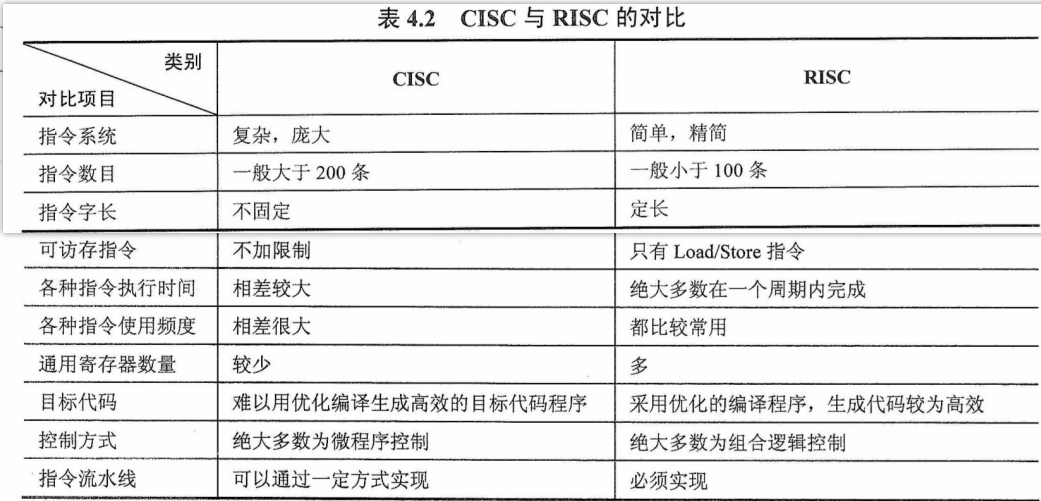
本章小结
什么是指令?什么是指令系统?为什么要引入指令系统?
指令就是要计算机执行某种操作的命令。一台计算机中所有机器指令的集合,称为这台计算机的指令系统。引入指令系统后,避免了用户与二进制代码直接接触,使得用户编写程序更为方便。另外,指令系统是表征一台计算机性能的重要因素,它的格式与功能不仅直接影响到机器的硬件结构,而且也直接影响到系统软件,影响到机器的适用范围。
一般来说,指令分为哪些部分?每部分有什么用处?
一条指令通常包括操作码字段和地址码字段两部分。其中,操作码指出指令中该指令应该执行什么性质的操作和具有何种功能,它是识别指令、了解指令功能与区分操作数地址内容的组成和使用方法等的关键信息。地址码用于给出被操作的信息(指令或数据)的地址,包括参加运算的一个或多个操作数所在的地址、运算结果的保存地址、程序的转移地址、被调用子程序的入口地址等。
对于一个指令系统来说,寻址方式多和少有什么影响?
寻址方式的多样化能让用户编程更为方便,但多重寻址方式会造成CPU结构的复杂化(详见下章),也不利于指令流水线的运行。而寻址方式太少虽然能够提高CPU的效率,但对于用户而言,少数几种寻址方式会使编程变得复杂,很难满足用户的需求。
常见问题和易混淆知识点
简述各常见指令寻址方式的特点和适用情况。
立即寻址操作数获取便捷,通常用于给寄存器赋初值。
直接寻址相对于立即寻址,缩短了指令长度。
间接寻址扩大了寻址范围,便于编制程序,易于完成子程序返回。
寄存器寻址的指令字较短,指令执行速度较快。
寄存器间接寻址扩大了寻址范围。
基址寻址扩大了操作数寻址范围,适用于多道程序设计,常用于为程序或数据分配存储空间。
变址寻址主要用于处理数组问题,适合编制循环程序。相对寻址用于控制程序的执行顺序、转移等。
基址寻址和变址寻址的区别:两种方式有效地址的形成都是寄存器内容+偏移地址,但是在基址寻址中,程序员操作的是偏移地址,基址寄存器的内容由操作系统控制,在执行过程中是动态调整的;而在变址寻址中,程序员操作的是变址寄存器,偏移地址是固定不变的。
一个操作数在内存可能占多个单元,怎样在指令中给出操作数的地址?
现代计算机都采用字节编址方式,即一个内存单元只能存放一字节的信息。一个操作数(如char、int、float、double)可能是8位、16位、32位或64位等,因此可能占用1个、2个、4个或8个内存单元。也就是说,一个操作数可能有多个内存地址对应。
有两种不同的地址指定方式:大端方式和小端方式。
大端方式:指令中给出的地址是操作数最高有效字节(MSB)所在的地址。
小端方式:指令中给出的地址是操作数最低有效字节(LSB)所在的地址。
装入/存储(Load/Store)型指令有什么特点?
装入/存储型指令是用在规整型指令系统中的一种通用寄存器型指令风格。这种指令风格在RISC 指令系统中较为常见。为了规整指令格式,使指令具有相同的长度,规定只有Load/Store指令才能访问内存。而运算指令不能直接访问内存,只能从寄存器取数进行运算,运算的结果也只能送到寄存器。因为寄存器编号较短,而主存地址位数较长,通过某种方式可使运算指令和访存指令的长度一致。
这种装入/存储型风格的指令系统的最大特点是,指令格式规整,指令长度一致,一般为32位。由于只有Load/Store指令才能访问内存,程序中可能会包含许多装入指令和存储指令,与一般通用寄存器型指令风格相比,其程序长度会更长。
中央处理器
p202
【考纲内容】
(一)CPU的功能和基本结构
(二)指令执行过程
(三)数据通路的功能和基本结构
(四)控制器的功能和工作原理
硬布线控制器
微程序控制器:微程序、微指令和微命令,微指令格式,微命令的编码方式,微地址的形成方式
(五)指令流水线
指令流水线的基本概念;指令流水线的基本实现
超标量和动态流水线的基本概念
【复习提示】
中央处理器是计算机的中心,也是本书的难点。其中,数据通路的分析、指令执行阶段的节拍与控制信号的安排、流水线技术与性能分析易出综合题。而关于各种寄存器的特点、指令执行的各种周期与特点、控制器的相关概念、流水线的相关概念也极易出选择题。
在学习本章时,请读者思考以下问题;
1)CPU分为哪几部分?分别实现什么功能?
2)指令和数据均存放在内存中,计算机如何从时间和空间上区分它们是指令还是数据?
3)什么是指令周期、机器周期和时钟周期?它们之间有何关系?
4)指令周期是否有一个固定值?为什么?
5)什么是微指令?它和第4章谈到的指令有什么关系?
6)什么是指令流水线?指令流水线相对于传统计算机体系结构的优势是什么?如何计算指令流水线的加速比?
请读者在本章的学习过程中寻找答案,本章末尾会给出参考答案。
总结一下, $\color{red}{\text{寄存器与字长之间的关系}}$
$\color{red}{\text{指令周期分为哪几个阶段,哪几个阶段会修改PC寄存器的值}}$
$\color{red}{\text{各种标志位的作用是啥,产生的时机又是啥}}$
$\color{red}{\text{哪些寄存器是透明的}}$
| 组件 | 是否透明 |
|---|---|
| 暂存寄存器 | |
| 累加寄存器 | |
| 程序计数器 | $\color{red}{\times}$ |
| 通用寄存器组 | $\color{red}{\times}$ |
| 程序状态字寄存器 | $\color{red}{\times}$ |
| 指令寄存器 | $\color{green}{\checkmark}$ |
| 指令译码器 | |
| 存储器地址寄存器 | |
| 存储器数据寄存器 |
全部习题之间增加分割线
(^##### )----------\n$1
CPU的功能和基本结构
CPU的功能
$\color{red}{\text{中央处理器}}$ (CPU)由 $\color{green}{\text{运算器}}$ 和 $\color{green}{\text{控制器}}$ 组成。其中, $\color{red}{\text{控制器}}$ 的功能是负责协调并控制计算机各部件执行程序的指令序列,包括 $\color{green}{\text{取指令}}$ 、 $\color{green}{\text{分析指令}}$ 和 $\color{green}{\text{执行指令}}$ ; $\color{red}{\text{运算器}}$ 的功能是 $\color{green}{\text{对数据进行加工}}$ 。CPU的具体功能包括:
1)指令控制。完成取指令、分析指令和执行指令的操作,即程序的顺序控制。
2)操作控制。一条指令的功能往往由若干操作信号的组合来实现。CPU 管理并产生由内存取出的每条指令的操作信号,把各种操作信号送往相应的部件,从而控制这些部件按指令的要求进行动作。
3)时间控制。对各种操作加以时间上的控制。时间控制要为每条指令按时间顺序提供应有的控制信号。
4)数据加工。对数据进行算术和逻辑运算。
5)中断处理。对计算机运行过程中出现的异常情况和特殊请求进行处理。
CPU的基本结构
在计算机系统中,中央处理器主要由运算器和控制器两大部分组成,如图5.1所示。
图片详情
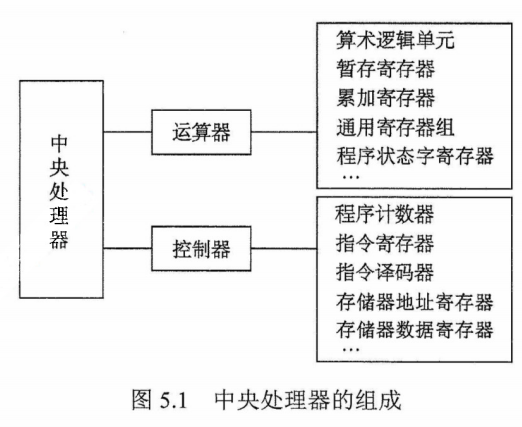
$\color{red}{\text{运算器}}$
运算器接收从控制器送来的命令并执行相应的动作,对数据进行加工和处理。运算器是计算机对数据进行加工处理的中心,它主要由算术逻辑单元(ALU)、暂存寄存器、累加寄存器(ACC)、通用寄存器组、程序状态字寄存器(PSW)、移位器、计数器(CT)等组成。
1) $\color{green}{\text{算术逻辑单元}}$ 。主要功能是进行算术/逻辑运算。
2) $\color{green}{\text{暂存寄存器}}$ 。用于暂存从主存读来的数据,该数据不能存放在通用寄存器中,否则会破坏其原有内容。暂存寄存器对应用程序员是透明的。
3) $\color{green}{\text{累加寄存器}}$ 。它是一个通用寄存器,用于暂时存放ALU运算的结果信息,可以作为加法运算的一个输入端。
4) $\color{green}{\text{通用寄存器组}}$ 。如AX、BX、CX、DX、SP等,用于存放操作数(包括源操作数、目的操作数及中间结果)和各种地址信息等。SP是堆栈指针,用于指示栈顶的地址。
5) $\color{green}{\text{程序状态字寄存器}}$ 。保留田昇个之西界R标志(ZF)、进位标志(CF)等。PSW 中息,如溢出标志(OF)、符号标志(SF)、零标志(ZF)、进位标志(CF)等。PSW中的这些位参与并决定微操作的形成。
6) $\color{green}{\text{移位器}}$ 。对操作数或运算结果进行移位运算。
7) $\color{green}{\text{计数器}}$ 。控制乘除运算的操作步数。
$\color{red}{\text{控制器}}$
控制器是整个系统的指挥中枢,在控制器的控制下,运算器、存储器和输入/输出设备等功能部件构成一个有机的整体,根据指令的要求指挥全机协调工作。控制器的基本功能是执行指令,每条指令的执行是由控制器发出的一组微操作实现的。
控制器有硬布线控制器和微程序控制器两种类型(见5.4节)。
控制器由程序计数器(PC)、指令寄存器(IR)、指令译码器、存储器地址寄存器(MAR)、存储器数据寄存器(MDR)、时序系统和微操作信号发生器等组成。
1) $\color{green}{\text{程序计数器}}$ 。用于指出下一条指令在主存中的存放地址。CPU根据PC的内容去主存中取指令。因程序中指令(通常)是顺序执行的,所以PC有自增功能。
2) $\color{green}{\text{指令寄存器}}$ 。用于保存当前正在执行的那条指令。
3) $\color{green}{\text{指令译码器}}$ 。仅对操作码字段进行译码,向控制器提供特定的操作信号。
4) $\color{green}{\text{存储器地址寄存器}}$ 。用于存放要访问的主存单元的地址。
5) $\color{green}{\text{存储器数据寄存器}}$ 。用于存放向主存写入的信息或从主存读出的信息。
6) $\color{green}{\text{时序系统}}$ 。用于产生各种时序信号,它们都由统一时钟(CLOCK)分频得到。
7) $\color{green}{\text{微操作信号发生器}}$ 。根据R的内容(指令)、PSW的内容(状态信息)及时序信号产生控制整个计算机系统所需的各种控制信号,其结构有组合逻辑型和存储逻辑型两种。
控制器的工作原理是,根据指令操作码、指令的执行步骤(微命令序列)和条件信号来形成当前计算机各部件要用到的控制信号。计算机整机各硬件系统在这些控制信号的控制下协同运行,产生预期的执行结果。
注意:CPU内部寄存器大致可分为两类:一类是用户可见的寄存器,可对这类寄存器编程,如通用寄存器组、程序状态字寄存器;另一类是用户不可见的寄存器,对用户是透明的,不可对这类寄存器编程,如存储器地址寄存器、存储器数据寄存器、指令寄存器。
指令执行过程
指令周期
CPU从主存中 $\color{green}{\text{取出并执行一条指令的时间称为指令周期}}$ ,不同指令的指令周期可能不同。指令周期常用若干机器周期来表示,一个机器周期又包含若干 $\color{yellow}{\text{时钟周期}}$ (也称 $\color{yellow}{\text{节拍}}$ 或T周期,它是CPU操作的最基本单位)。每个指令周期内的机器周期数可以不等,每个机器周期内的节拍数也可以不等。图5.2反映了上述关系。图5.2(a)为定长的机器周期,每个机器周期包含4个节拍(T);图5.2(b)所示为不定长的机器周期,每个机器周期包含的节拍数可以为4个,也可以为3个。
图片详情
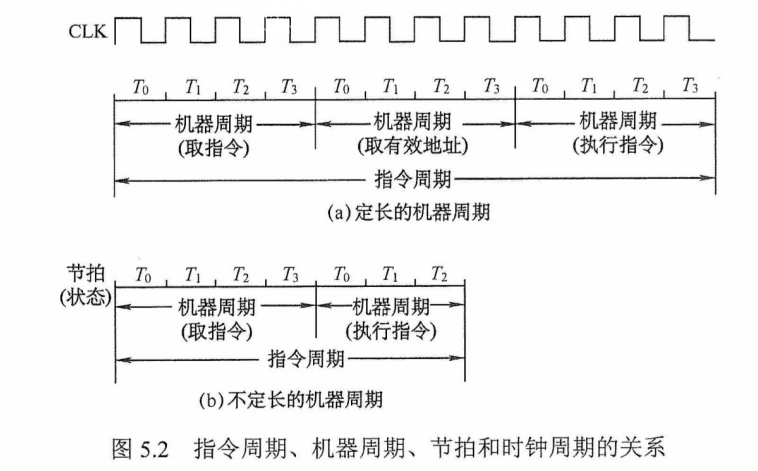
对于无条件转移指令JMP X,在执行时不需要访问主存,只包含取指阶段(包括取指和分析)和执行阶段,所以其指令周期仅包含取指周期和执行周期。
对于间接寻址的指令,为了取操作数,需要先访问一次主存,取出有效地址,然后访问主存,取出操作数,所以还需包括间址周期。间址周期介于取指周期和执行周期之间。
当CPU采用中断方式实现主机和I/O设备的信息交换时,CPU在每条指令执行结束前,都要发中断查询信号,若有中断请求,则CPU进入中断响应阶段,又称中断周期。这样,一个完整的 $\color{red}{\text{指令周期}}$ 应包括 $\color{green}{\text{取指}}$ 、 $\color{green}{\text{间址}}$ 、 $\color{green}{\text{执行}}$ 和 $\color{green}{\text{中断}}$ 4个周期,如图5.3所示。
图片详情
上述4个工作周期都有CPU访存操作,只是访存的目的不同。取指周期是为了取指令,间址周期是为了取有效地址,执行周期是为了取操作数,中断周期是为了保存程序断点。
为了区别不同的工作周期,在CPU内设置4个标志触发器FE、IND、EX和 INT,它们分别对应取指、间址、执行和中断周期,并以“1”状态表示有效,分别由1→FE、1→ND、1→EX和1→INT这4个信号控制。
注意:中断周期中的进栈操作是将SP减1,这和传统意义上的进栈操作相反,原因是计算机的堆栈中都是向低地址增加,所以进栈操作是减1而不是加1。
指令周期的数据流
数据流是根据指令要求依次访问的数据序列。在指令执行的不同阶段,要求依次访问的数据序列是不同的。而且对于不同的指令,它们的数据流往往也是不同的。
- $\color{red}{\text{注意到}}$ :虽然有三种总线,每种寄存器和内存之间的通信,只能经过一种特定的总线
取指周期
取指周期的任务是根据PC中的内容从主存中取出指令代码并存放在IR中。
取指周期的数据流如图5.4所示。PC 中存放的是指令的地址,根据此地址从内存单元中取出的是指令,并放在指令寄存器IR中,取指令的同时,PC加1。
图片详情
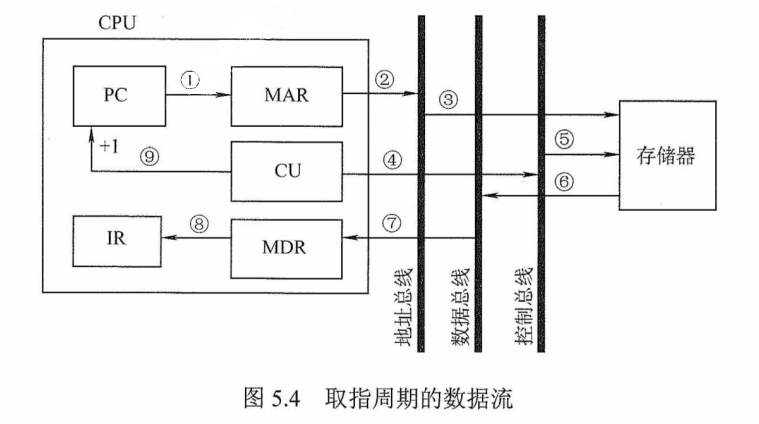
取指周期的数据流向如下:
1)PC①MAR②地址总线 ${\textstyle\unicode{x2462}}$ 主存。
2)CU 发出控制信号④控制总线⑤主存。
3)主存⑥数据总线⑦MDR⑧IR(存放指令)。
4)CU发出读命令⑨PC内容加1。
间址周期
间址周期的任务是取操作数有效地址。以一次间址为例(见图5.5),将指令中的地址码送到MAR并送至地址总线,此后CU向存储器发读命令,以获取有效地址并存至MDR.
图片详情
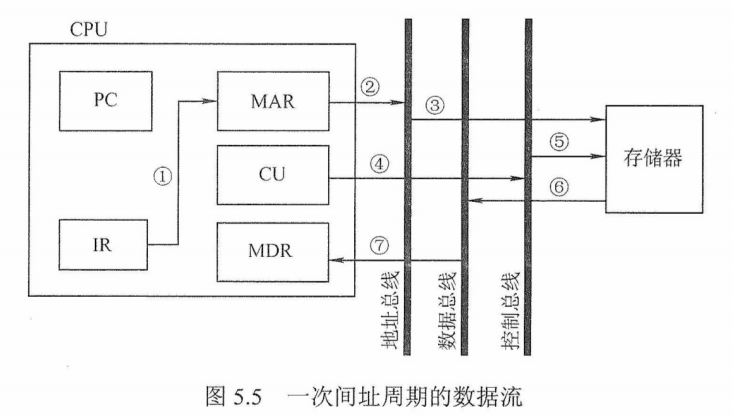
间址周期的数据流向如下:
1)Ad(IR)(或MDR① MAR②地址总线③主存。
2)CU 发出读命令④控制总线⑤主存。
3)主存⑥数据总线⑦MDR(存放有效地址)。
其中,Ad(IR)表示取出IR中存放的指令字的地址字段。
执行周期
执行周期的任务是根据IR中的指令字的操作码和操作数通过 ALU操作产生执行结果。不同指令的执行周期操作不同,因此没有统一的数据流向。
中断周期
中断周期的任务是处理中断请求。假设程序断点存入堆栈中,并用SP指示栈顶地址,而且进栈操作是先修改栈顶指针,后存入数据,数据流如图5.6所示。
图片详情
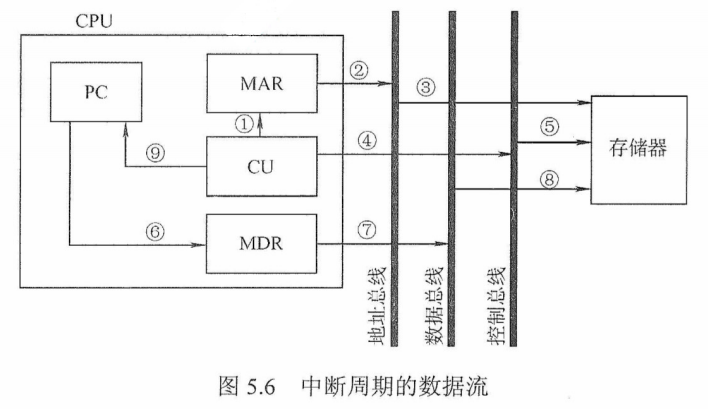
中断周期的数据流向如下:
1)CU控制将SP减1,SP ① MAR②地址总线③主存。
2)CU发出写命令④控制总线⑤主存。
3)PC⑥ MDR⑦数据总线⑧主存(程序断点存入主存)。
4)CU(中断服务程序的入口地址)⑨PC。
指令执行方案
一个指令周期通常要包括几个时间段(执行步骤),每个步骤完成指令的一部分功能,几个依次执行的步骤完成这条指令的全部功能。出于性能和硬件成本等考虑,可以选用3种不同的方案来安排指令的执行步骤。
- $\color{green}{\text{单}}$ 指令周期,周期只有 $\color{green}{\text{一}}$ 种情况
- $\color{green}{\text{多}}$ 指令周期,周期有 $\color{green}{\text{多}}$ 种情况
单指令周期
对所有指令都选用 $\color{green}{\text{相同的执行时间}}$ 来完成,称为单指令周期方案。此时每条指令都在固定的时钟周期内完成,指令之间串行执行,即下一条指令只能在前一条指令执行结束后才能启动。因此,指令周期取决于执行时间最长的指令的执行时间。对于那些本来可以在更短时间内完成的指令,要使用这个较长的周期来完成,会降低整个系统的运行速度。
多指令周期
对不同类型的指令选用不同的执行步骤来完成,称为 $\color{green}{\text{多指令周期方案}}$ 。指令之间串行执行,即下一条指令只能在前一条指令执行结束后才能启动。但可选用不同个数的时钟周期来完成不同指令的执行过程,指令需要几个周期就为其分配几个周期,而不再要求所有指令占用相同的执行时间。
流水线方案
指令之间可以并行执行的方案,称为流水线方案,其追求的目标是力争在每个时钟脉冲周期完成一条指令的执行过程(只在理想情况下才能达到该效果)。这种方案通过在每个时钟周期启动一条指令, $\color{green}{\text{尽量让多条指令同时运行,但各自处在不同的执行步骤中}}$ 。
数据通路的功能和基本结构
数据通路的功能
数据在功能部件之间传送的路径称为 $\color{red}{\text{数据通路}}$ 。路径上的部件称为 $\color{red}{\text{数据通路部件}}$ ,如 $\color{green}{\text{ALU}}$ 、 $\color{green}{\text{通用寄存器}}$ 、 $\color{green}{\text{状态寄存器}}$ 、 $\color{green}{\text{异常}}$ 和 $\color{green}{\text{中断处理逻辑}}$ 等。数据通路描述了信息从什么地方开始,中间经过哪个寄存器或多路开关,最后传送到哪个寄存器,这些都需要加以控制。
数据通路中专门进行数据运算的部件称为 $\color{red}{\text{执行部件}}$ 或 $\color{red}{\text{功能部件}}$ 。数据通路由 $\color{red}{\text{控制部件}}$ 控制,控制部件根据每条指令功能的不同生成对数据通路的控制信号,并正确控制指令的执行流程。数据通路的功能是 $\color{green}{\text{实现CPU内部的运算器与寄存器及寄存器之间的数据交换}}$ 。
数据通路的基本结构
数据通路的基本结构主要有以下几种:
1) $\color{green}{\text{CPU 内部单总线方式}}$ 。将所有寄存器的输入端和输出端都连接到一条公共通路上,这种结构比较简单,但数据传输存在较多的冲突现象,性能较低。连接各部件的总线只有一条时,称为单总线结构;CPU中有两条或更多的总线时,构成双总线结构或多总线结构。图5.7所示为CPU内部总线的数据通路和控制信号。
2) $\color{green}{\text{CPU内部三总线方式}}$ 。将所有寄存器的输入端和输出端都连接到多条公共通路上,相比之下单总线中一个时钟内只允许传一个数据,因而指令执行效率很低,因此采用多总线方式,同时在多个总线上传送不同的数据,提高效率。
3) $\color{green}{\text{专用数据通路方式}}$ 。根据指令执行过程中的数据和地址的流动方向安排连接线路,避免使用共享的总线,性能较高,但硬件量大。
在图5.7中,规定各部件用大写字母表示,字母加“in”表示该部件的允许输入控制信号;字母加“out”表示该部件的允许输出控制信号。
图片详情
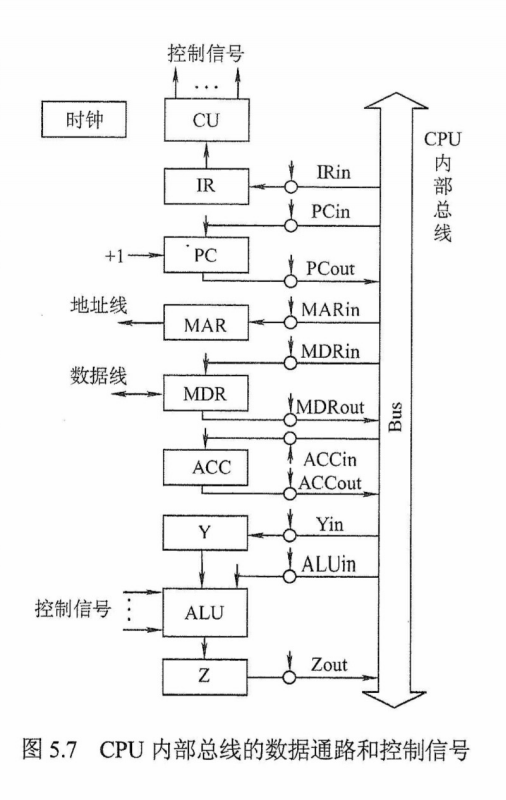
注意: $\color{red}{\text{内部总线}}$ 是指同一部件,如CPU内部连接各寄存器及运算部件之间的总线; $\color{red}{\text{系统总线}}$ 是指同一台计算机系统的各部件,如CPU、内存、通道和各类IO接口间互相连接的总线。
寄存器之间的数据传送
寄存器之间的数据传送可通过CPU内部总线完成。在图5.7中,某寄存器AX的输出和输入分别由AXout 和AXin控制。这里以PC寄存器为例,把PC内容送至MAR,实现传送操作的流程及控制信号为
PC→Bus PCout有效,PC内容送总线
Bus→MAR MARin有效,总线内容送MAR
主存与CPU之间的数据传送
主存与CPU之间的数据传送也要借助CPU内部总线完成。现以CPU 从主存读取指令为例说明数据在数据通路中的传送过程。实现传送操作的流程及控制信号为
PC→Bus→MAR PCout 和 MARin有效,现行指令地址→MAR
1→R CU发读命令
MEM(MAR)→MDR MDRin有效
MDR→BuS→IR MDRout和 IRin有效,现行指令→IR
执行算术或逻辑运算
执行算术或逻辑操作时,由于ALU本身是没有内部存储功能的组合电路,因此如要执行加法运算,相加的两个数必须在 ALU的两个输入端同时有效。图5.7中的暂存器Y即用于该目的。先将一个操作数经CPU内部总线送入暂存器Y保存,Y的内容在 ALU的左输入端始终有效,再将另一个操作数经总线直接送到ALU的右输入端。这样两个操作数都送入了ALU,运算结果暂存在暂存器Z中。
Ad(IR)→Bus→MAR MDRout和 MARin有效
1→R CU发读命令
MEM→数据线→MDR 操作数从存储器→数据线→MDR
MDR→Bus→Y MDRout 和 Yin有效,操作数→Y
(ACC)+(Y)→Z ACCout 和 ALUin有效,CU向ALU发加命令,结果→Z
Z→ACC Zout和 ACCin有效,结果→ACC
数据通路结构直接影响CPU内各种信息的传送路径,数据通路不同,指令执行过程的微操作序列的安排也不同,它关系着微操作信号形成部件的设计。
控制器的功能和工作原理
控制器的结构和功能
从图5.8可以看到计算机硬件系统的五大功能部件及其连接关系。它们通过数据总线、地址总线和控制总线连接在一起,其中点画线框内的是控制器部件。
图片详情
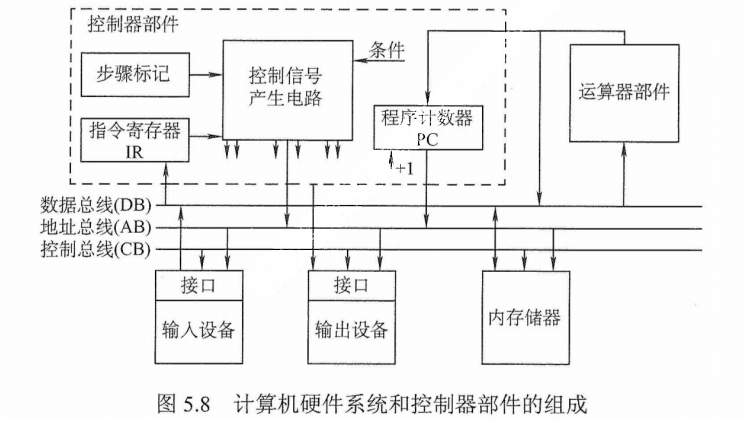
现对其主要连接关系简单说明如下:
1)运算器部件通过数据总线与内存储器、输入设备和输出设备传送数据。2)输入设备和输出设备通过接口电路与总线相连接。
3)内存储器、输入设备和输出设备从地址总线接收地址信息,从控制总线得到控制信号,通过数据总线与其他部件传送数据。
4)控制器部件从数据总线接收指令信息,从运算器部件接收指令转移地址,送出指令地址到地址总线,还要向系统中的部件提供它们运行所需要的控制信号。控制器是计算机系统的指挥中心,控制器的主要功能有:
1)从主存中取出一条指令,并指出下一条指令在主存中的位置。
2)对指令进行译码或测试,产生相应的操作控制信号,以便启动规定的动作。
3)指挥并控制CPU、主存、输入和输出设备之间的数据流动方向。
根据控制器产生微操作控制信号的方式的不同,控制器可分为硬布线控制器和微程序控制器,两类控制器中的PC和IR是相同的,但确定和表示指令执行步骤的办法以及给出控制各部件运行所需要的控制信号的方案是不同的。
硬布线控制器
硬布线控制器的基本原理是根据指令的要求、当前的时序及外部和内部的状态,按时间的顺序发送一系列微操作控制信号。它由复杂的组合逻辑门电路和一些触发器构成,因此又称组合逻辑控制器。
- $\color{green}{\text{组合逻辑电路}}$ 和 $\color{green}{\text{时序逻辑电路}}$
硬布线控制单元图
指令的操作码是决定控制单元发出不同操作命令(控制信号)的关键。为了简化控制单元(CU)的逻辑,将指令的操作码译码和节拍发生器从CU分离出来,便可得到简化的控制单元图,如图5.9所示。
CU的输入信号来源如下:
1)经指令译码器译码产生的指令信息。现行指令的操作码决定了不同指令在执行周期所需完成的不同操作,因此指令的 $\color{green}{\text{操作码}}$ 字段是控制单元的输入信号,它与时钟配合产生不同的控制信号。
2)时序系统产生的机器周期信号和节拍信号。为了使控制单元按一定的先后顺序、一定的节奏发出各个控制信号,控制单元必须受时钟控制,即一个时钟脉冲使控制单元发送一个操作命令,或发送一组需要同时执行的操作命令。
3)来自执行单元的反馈信息即标志。控制单元有时需依赖CPU当前所处的状态产生控制信号,如BAN指令,控制单元要根据上条指令的结果是否为负来产生不同的控制信号。
图片详情
图5.9 中,节拍发生器产生各机器周期中的节拍信号,使不同的微操作命令$C_i$(控制信号)按时间的先后发出。个别指令的操作不仅受操作码控制,还受状态标志控制,因此CU的输入来自操作码译码电路ID、节拍发生器及状态标志,其输出到CPU内部或外部控制总线上。
注意:控制单元还接收来自系统总线(控制总线)的控制信号,如中断请求、DMA请求。
硬布线控制器的时序系统及微操作
1)时钟周期。用时钟信号控制节拍发生器,可以产生节拍,每个节拍的宽度正好对应一个时钟周期。在每个节拍内机器可完成一个或几个需同时执行的操作。
2)机器周期。机器周期可视为所有指令执行过程中的一个基准时间。不同指令的操作不同,指令周期也不同。访问一次存储器的时间是固定的,因此通常以存取周期作为基准时间,即内存中读取一个指令字的最短时间作为机器周期。在存储字长等于指令字长的前提下,取指周期也可视为机器周期。
在一个机器周期里可完成若干微操作,每个微操作都需一定的时间,可用时钟信号来控制产生每个微操作命令。
3)指令周期。指令周期详见5.2.1节。
4)微操作命令分析。控制单元具有发出各种操作命令(控制信号)序列的功能。这些命令与指令有关,而且必须按一定次序发出,才能使机器有序地工作。
执行程序的过程中,对于不同的指令,控制单元需发出各种不同的微操作命令。一条指令分为3个工作周期:取指周期、间址周期和执行周期。下面分析各个子周期的微操作命令。
图片详情

CPU 的控制方式
控制单元控制一条指令执行的过程,实质上是依次执行一个确定的微操作序列的过程。由于不同指令所对应的微操作数及复杂程度不同,因此每条指令和每个微操作所需的执行时间也不同。主要有以下3种控制方式。
1) $\color{green}{\text{同步控制方式}}$ 。所谓同步控制方式,是指系统有一个统一的时钟,所有的控制信号均来自这个统一的时钟信号。通常以最长的微操作序列和最烦琐的微操作作为标准,采取完全统一的、具有相同时间间隔和相同数目的节拍作为机器周期来运行不同的指令。同步控制方式的优点是控制电路简单,缺点是运行速度慢。
2) $\color{green}{\text{异步控制方式}}$ 。异步控制方式不存在基准时标信号,各部件按自身固有的速度工作,通过应答方式进行联络。异步控制方式的优点是运行速度快,缺点是控制电路比较复杂。
3) $\color{green}{\text{联合控制方式}}$ 。联合控制方式是介于同步、异步之间的一种折中。这种方式对各种不同的指令的微操作实行大部分采用同步控制、小部分采用异步控制的办法。
硬布线控制单元设计步骤
硬布线控制单元设计步骤包括:
1)列出微操作命令的操作时间表。先根据微操作节拍安排,列出微操作命令的操作时间表。操作时间表中包括各个机器周期、节拍下的每条指令完成的微操作控制信号。表5.1列出了CLA、COM、SHR等10条机器指令微操作命令的操作时间表。表中FE、IND 和EX为CPU 工作周期标志,$T_0~T_2$,为节拍,Ⅰ为间址标志,在取指周期的$T_2$时刻,若测得I=1,则IND触发器置“1”,标志进入间址周期;若I=0,则EX触发器置“1”,标志进入执行周期。同理,在间址周期的$T_2$时刻,若测得IND=0(表示一次间接寻址),则EX触发器置“1”,进入执行周期;若测得IND= 1(表示多次间接寻址),则继续间接寻址。在执行周期的$T_2$时刻,CPU 要向所有中断源发中断查询信号,若检测到有中断请求并满足响应条件,则INT触发器置“1”,标志进入中断周期。表中未列出INT触发器置“1”的操作和中断周期的微操作。表中第一行对应10条指令的操作码,代表不同的指令。若某指令有表中所列出的微操作命令,其对应的单元格内为1。
2)进行微操作信号综合。在列出微操作时间表后,即可对它们进行综合分析、归类,根据
微操作时间表可写出各微操作控制信号的逻辑表达式并进行适当的简化。表达式一般包括下列因素:
微操作控制信号=机器周期$\wedge$节拍$\wedge$脉冲$\wedge$操作码$\wedge$机器状态条件
根据表5.1便可列出每个微操作命令的初始逻辑表达式,经化简、整理可获得能用现有门电路实现的微操作命令逻辑表达式。
图片详情
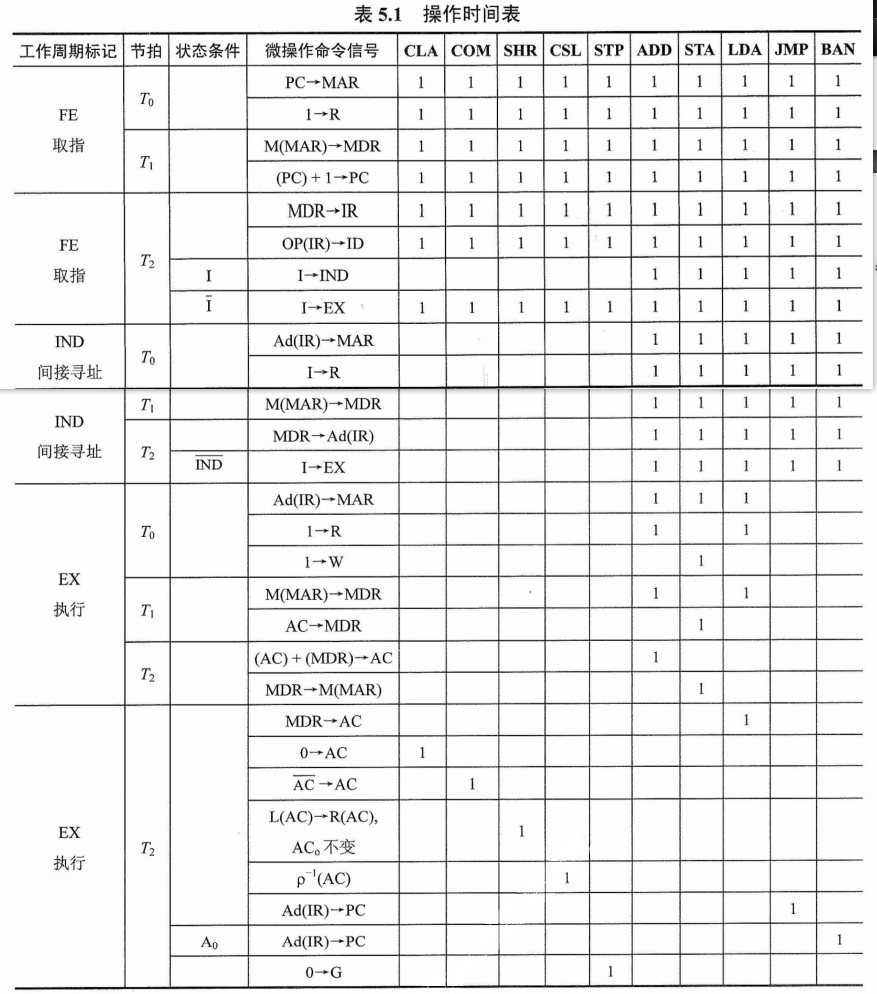
例如,根据表5.1可写出 M(MAR)–MDR微操作命令的逻辑表达式:
M(MAR)→MDR
=FE$\cdot T_1$+IND$\cdot T_1$;(ADD + STA + LDA + JMP + BAN)+EX$\cdot T_1$;(ADD +LDA)=$T_1${FE+ IND(ADD + STA+ LDA+JMP+BAN)+EX(ADD +LDA)}
式中,ADD、STA、LDA、JMP、BAN均来自操作码译码器的输出。
3)画出微操作命令的逻辑图。根据逻辑表达式可画出对应每个微操作信号的逻辑电路图,
并用逻辑门电路实现。
例如,M(MAR)-MDR的逻辑表达式所对应的逻辑图如图5.10 所示,图中未考虑门的扇入系数。
$\color{red}{\text{Q}}$ :什么是扇入系数
图片详情
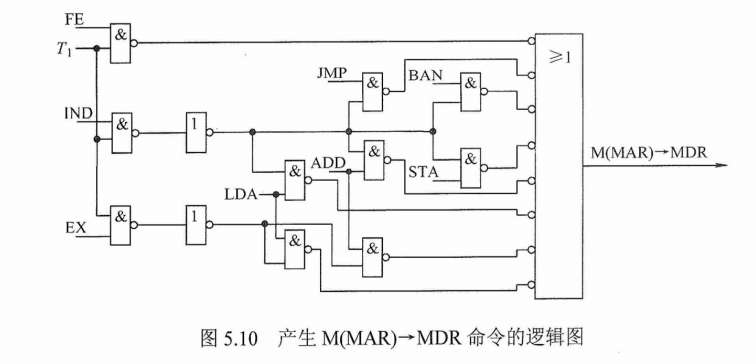
微程序控制器
微程序控制器采用存储逻辑实现,也就是把微操作信号代码化,使每条机器指令转化成为一段微程序并存入一个专门的存储器(控制存储器)中,微操作控制信号由微指令产生。
微程序控制的基本概念
微程序设计思想就是将每条机器指令编写成一个微程序,每个微程序包含若干微指令,每条微指令对应一个或几个微操作命令。这些微程序可以存到一个控制存储器中,用寻址用户程序机器指令的办法来寻址每个微程序中的微指令。目前,大多数计算机都采用微程序设计技术。
微程序设计技术涉及的基本术语如下:
1) $\color{green}{\text{微命令与微操作}}$ 。一条机器指令可以分解成一个微操作序列,这些微操作是计算机中最基本的、不可再分解的操作。在微程序控制的计算机中,将控制部件向执行部件发出的各种控制命令称为 $\color{red}{\text{微命令}}$ ,它是构成控制序列的最小单位。例如,打开或关闭某个控制门的电位信号、某个寄存器的打入脉冲等。微命令和微操作是一一对应的。微命令是微操作的控制信号,微操作是微命令的执行过程。
微命令有相容性和互斥性之分。相容性微命令是指那些可以同时产生、共同完成某一些微操作的微命令;而互斥性微命令是指在机器中不允许同时出现的微命令。相容和互斥都是相对的,一个微命令可以和一些微命令相容,和另一些微命令互斥。
注意:在组合逻辑控制器中也存在微命令与微操作这两个概念,它们并非只是微程序控制器的专有概念。
2) $\color{green}{\text{微指令与微周期}}$ 。微指令是若干微命令的集合。存放微指令的控制存储器的单元地址称为微地址。一条微指令通常至少包含两大部分信息:
① $\color{green}{\text{操作控制字段}}$ ,又称微操作码字段,用于产生某一步操作所需的各种操作控制信号。
${\textstyle\unicode{x2461}}$ $\color{green}{\text{顺序控制字段}}$ ,又称微地址码字段,用于控制产生下一条要执行的微指令地址。微周期通常指从控制存储器中读取一条微指令并执行相应的微操作所需的时间。
3)主存储器与控制存储器。主存储器用于存放程序和数据,在CPU外部,用RAM 实现;控制存储器(CM)用于存放微程序,在CPU内部,用ROM实现。
4)程序与微程序。 $\color{red}{\text{程序}}$ 是 $\color{green}{\text{指令的有序集合}}$ ,用于完成特定的功能; $\color{red}{\text{微程序}}$ 是 $\color{green}{\text{微指令的有序集合}}$ ,一条指令的功能由一段微程序来实现。
微程序和程序是两个不同的概念。微程序是由微指令组成的,用于描述机器指令。微程序实际上是机器指令的实时解释器,是由计算机设计者事先编制好并存放在控制存储器中的,一般不提供给用户。对于程序员来说,计算机系统中微程序的结构和功能是透明的,无须知道。而程序最终由机器指令组成,是由软件设计人员事先编制好并存放在主存或辅存中的。
读者应注意区分以下寄存器:
①地址寄存器(MAR)。用于存放主存的读/写地址。
${\textstyle\unicode{x2461}}$ 微地址寄存器(CMAR)。用于存放控制存储器的读/写微指令的地址。
③指令寄存器(IR)。用于存放从主存中读出的指令。
④微指令寄存器(CMDR或uIR)。用于存放从控制存储器中读出的微指令。
微程序控制器组成和工作过程
微程序控制器的基本组成
图5.11所示为一个微程序控制器的基本结构,主要画出了微程序控制器比组合逻辑控制器多出的部件,包括:
${\textstyle\unicode{x2460}}$ 控制存储器。它是微程序控制器的核心部件,用于存放各指令对应的微程序,控制存储器可用只读存储器ROM构成。
${\textstyle\unicode{x2461}}$ 微指令寄存器。用于存放从CM中取出的微指令,它的位数同微指令字长相等。
${\textstyle\unicode{x2462}}$ 微地址形成部件。用于产生初始微地址和后继微地址,以保证微指令的连续执行。
${\textstyle\unicode{x2463}}$ 微地址寄存器。接收微地址形成部件送来的微地址,为在CM中读取微指令作准备。
图5.11微程序控制器的基本结构
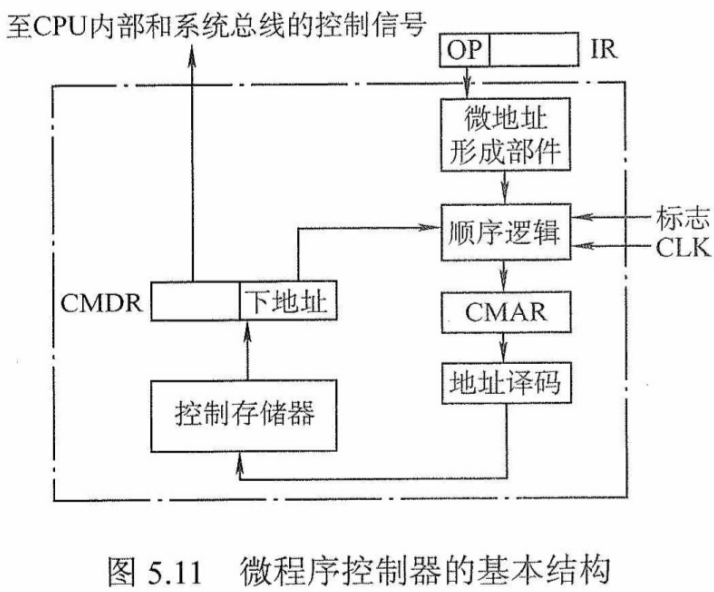
微程序控制器的工作过程
微程序控制器的工作过程实际上就是在微程序控制器的控制下计算机执行机器指令的过程,这个过程可以描述如下:
${\textstyle\unicode{x2460}}$ 执行取微指令公共操作。具体的执行是:在机器开始运行时,自动将取指微程序的入口地址送入CMAR,并从CM 中读出相应的微指令送入CMDR。取指微程序的入口地址一般为CM的0号单元,当取指微程序执行完后,从主存中取出的机器指令就已存入指令寄存器中。
${\textstyle\unicode{x2461}}$ 由机器指令的操作码字段通过微地址形成部件产生该机器指令所对应的微程序的入口地
址,并送入CMAR。
③从CM中逐条取出对应的微指令并执行。
④执行完对应于一条机器指令的一个微程序后,又回到取指微程序的入口地址,继续第①
步,以完成取下一条机器指令的公共操作。
以上是一条机器指令的执行过程,如此周而复始,直到整个程序执行完毕。
微程序和机器指令
通常,一条机器指令对应一个微程序。由于任何一条机器指令的取指令操作都是相同的,因此可将取指令操作的微命令统一编成一个微程序,这个微程序只负责将指令从主存单元中取出并送至指令寄存器。
此外,也可编出对应间址周期的微程序和中断周期的微程序。这样,控制存储器中的微程序个数应为机器指令数再加上对应取指、间址和中断周期等共用的微程序数。
注意:若指令系统中具有$n$种机器指令,则控制存储器中的微程序数至少是$n +1 $(1为公共的取指微程序)。
微指令的编码方式
微指令的编码方式又称微指令的控制方式,是指如何对微指令的控制字段进行编码,以形成控制信号。编码的目标是在保证速度的情况下,尽量缩短微指令字长。
直接编码(直接控制)方式
微指令的直接编码方式如图5.12所示。直接编码法无须进行译码,微指令的微命令字段中每位都代表一个微命令。设计微指令时,选用或不选用某个微命令,只要将表示该微命令的对应位设置成1或0即可。每个微命令对应并控制数据通路中的一个微操作。
这种编码的优点是简单、直观,执行速度快,操作并行性好;缺点是微指令字长过长,$n$个微命令就要求微指令的操作字段有$n$位,造成控制存储器容量极大。
图5.12微指令的直接编码方式
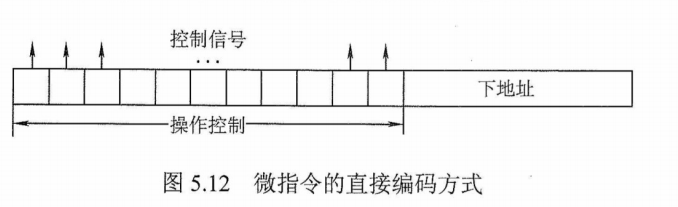
字段直接编码方式
将微指令的微命令字段分成若干小字段,把互斥性微命令组合在同一字段中,把相容性微命令组合在不同字段中,每个字段独立编码,每种编码代表一个微命令且各字段编码含义单独定义,与其他字段无关,这就是字段直接编码方式,如图5.13所示。
这种方式可以缩短微指令字长,但因为要通过译码电路后再发出微命令,因此比直接编码方式慢。
微命令字段分段的原则:
${\textstyle\unicode{x2460}}$ 互斥性微命令分在同一段内,相容性微命令分在不同段内。
${\textstyle\unicode{x2461}}$ 每个小段中包含的信息位不能太多,否则将增加译码线路的复杂性和译码时间。
${\textstyle\unicode{x2462}}$ 一般每个小段还要留出一个状态,表示本字段不发出任何微命令。因此,当某字段的长度为3位时,最多只能表示7个互斥的微命令,通常用000表示不操作。
图5.13微指令的字段直接编码方式
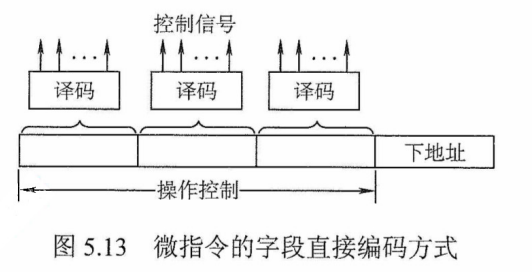
字段间接编码方式
一个字段的某些微命令需由另一个字段中的某些微命令来解释,由于不是靠字段直接译码发出的微命令,因此称为字段间接编码,又称隐式编码。这种方式可进一步缩短微指令字长,但因削弱了微指令的并行控制能力,因此通常作为字段直接编码方式的一种辅助手段。
微指令的地址形成方式
后继微地址的形成主要有以下两大基本类型:
1)直接由微指令的下地址字段指出。微指令格式中设置一个下地址字段,由微指令的下地址字段直接指出后继微指令的地址,这种方式又称断定方式。
2)根据机器指令的操作码形成。机器指令取至指令寄存器后,微指令的地址由操作码经微地址形成部件形成。
实际上,微指令序列地址的形成方式还有以下几种:
①增量计数器法,即(CMAR)+1→CMAR,适用于后继微指令的地址连续的情况。
${\textstyle\unicode{x2461}}$ 根据各种标志决定微指令分支转移的地址。
③通过网络测试形成。
④由硬件直接产生微程序入口地址。
电源加电后,第一条微指令的地址可由专门的硬件电路产生,也可由外部直接向CMAR输入微指令的地址,这个地址即为取指周期微程序的入口地址。
微指令的格式
微指令格式与微指令的编码方式有关,通常分水平型微指令和垂直型微指令两种。
1)水平型微指令。从编码方式看,直接编码、字段直接编码、字段间接编码和混合编码都属于水平型微指令。水平型微指令的基本指令格式如图5.14所示,指令字中的一位对应-一个控制信号,有输出时为1,否则为0。一条水平型微指令定义并执行几种并行的基本操作。
图片详情

水平型微指令的优点是微程序短,执行速度快;缺点是微指令长,编写微程序较麻烦。
2)垂直型微指令。垂直型微指令的特点是采用类似机器指令操作码的方式,在微指令中设置微操作码字段,采用微操作码编译法,由微操作码规定微指令的功能,其基本的指令格式如图5.15所示。一条垂直型微指令只能定义并执行一种基本操作。
图片详情

垂直型微指令格式的优点是微指令短、简单、规整,便于编写微程序;缺点是微程序长,执行速度慢,工作效率低。
3)混合型微指令。在垂直型的基础上增加一些不太复杂的并行操作。微指令较短,仍便于编写;微程序也不长,执行速度加快。
4)水平型微指令和垂直型微指令的比较如下:
${\textstyle\unicode{x2460}}$ 水平型微指令并行操作能力强、效率高、灵活性强;垂直型微指令则较差。
${\textstyle\unicode{x2461}}$ 水平型微指令执行一条指令的时间短;垂直型微指令执行的时间长。
${\textstyle\unicode{x2462}}$ 由水平型微指令解释指令的微程序,具有微指令字较长但微程序短的特点;垂直型
微指令则与之相反,其微指令字较短而微程序长。
④水平型微指令用户难以掌握,而垂直型微指令与指令比较相似,相对容易掌握。
微程序控制单元的设计步骤
微程序控制单元设计的主要任务是编写各条机器指令所对应的微程序。具体的设计步骤如下:
1)写出对应机器指令的微操作命令及节拍安排。无论是组合逻辑设计还是微程序设计,对应相同的CPU 结构,两种控制单元的微操作命令和节拍安排都是极相似的。如微程序控制单元在取指阶段发出的微操作命令及节拍安排如下:
$T_0$ PC→MAR,1→R
$T_1$ M(MAR)→MDR,(PC)+1-→PC
$T_2$ MDR→IR,OP(IR)→微地址形成部件
与硬布线控制单元相比,只在$T_2$节拍内的微操作命令不同。微程序控制单元在$T_2$节拍内要将指令的操作码送至微地址形成部件,即OP(IR)→微地址形成部件,以形成该条机器指令的微程序首地址。而硬布线控制单元在$T_2$,节拍内要将指令的操作码送至指令译码器,以控制CU 发出相应的微命令,即 OP(IR)→ID。
若把一个节拍T内的微操作安排在一条微指令中完成,上述微操作对应3条微指令。但由于微程序控制的所有控制信号都来自微指令,而微指令又存在控制存储器中,因此欲完成上述这些微操作,必须先将微指令从控制存储器中读出,即必须先给出这些微指令的地址。在取指微程序中,除第一条微指令外,其余微指令的地址均由上一条微指令的下地址字段直接给出,因此上述每条微指令都需增加一个将微指令下地址字段送至CMAR 的微操作,记为 Ad(CMDR)→CMAR。取指微程序的最后一条微指令,其后继微指令的地址是由微地址形成部件形成的,即微地址形成部件→CMAR。为了反映该地址与操作码有关,因此记为OP(IR)→微地址形成部件→CMAR。
综上所述,考虑到需要形成后继微指令地址,上述分析的取指操作共需6条微指令完成:
$T_0$ PC→MAR,1→R
$T_1$ Ad(CMDR)→CMAR
$T_2$ M(MAR)→MDR,(PC)+1→PC
$T_3$ Ad(CMDR)→CMAR
$T_4$ MDR→IR
$T_5$ OP(IR)→微地址形成部件→CMAR
执行阶段的微操作命令及节拍安排,分配原则类似。与硬布线控制单元微操作命令的节拍安排相比,多了将下一条微指令地址送至CMAR 的微操作命令,即 Ad(CMDR)→CMAR。其余的微操作命令与硬布线控制单元相同。
注意:这里为了理解,应将微指令和机器指令相联系,因为每执行完一条微指令后要得到下一条微指令的地址。
2)确定微指令格式。微指令格式包括微指令的编码方式、后继微指令地址的形成方式和微指令字长等。
根据微操作个数决定采用何种编码方式,以确定微指令的操作控制字段的位数。由微指令数确定微指令的顺序控制字段的位数。最后按操作控制字段位数和顺序控制字段位数就可确定微指令字长。
3)编写微指令码点。根据操作控制字段每位代表的微操作命令,编写每条微指令的码点。
动态微程序设计和毫微程序设计
1)动态微程序设计。在一台微程序控制的计算机中,假如能根据用户的要求改变微程序,则这台机器就具有动态微程序设计功能。
动态微程序的设计需要可写控制寄存器的支持,否则难以改变微程序的内容。实现动态微程序设计可采用可擦除可编程只读存储器(EPROM)。
2)毫微程序设计。在普通的微程序计算机中,从主存取出的每条指令是由放在控制存储器中的微程序来解释执行的,通过控制线对硬件进行直接控制。
若硬件不由微程序直接控制,而是通过存放在第二级控制存储器中的毫微程序来解释的,这个第二级控制存储器就称为毫微存储器,直接控制硬件的是毫微微指令。
硬布线和微程序控制器的特点
1)硬布线控制器的特点。硬布线控制器的优点是由于控制器的速度取决于电路延迟,所以速度快;缺点是由于将控制部件视为专门产生固定时序控制信号的逻辑电路,所以把用最少元件和取得最高速度作为设计目标,一旦设计完成,就不可能通过其他额外修改添加新功能。
2)微程序控制器的特点。微程序控制器的优点是同组合逻辑控制器相比,微程序控制器具有规整性、灵活性、可维护性等一系列优点;缺点是由于微程序控制器采用了存储程序原理,所以每条指令都要从控制存储器中取一次,影响速度。
为便于比较,下面以表格的形式对比二者的不同,见表5.2。
图片详情
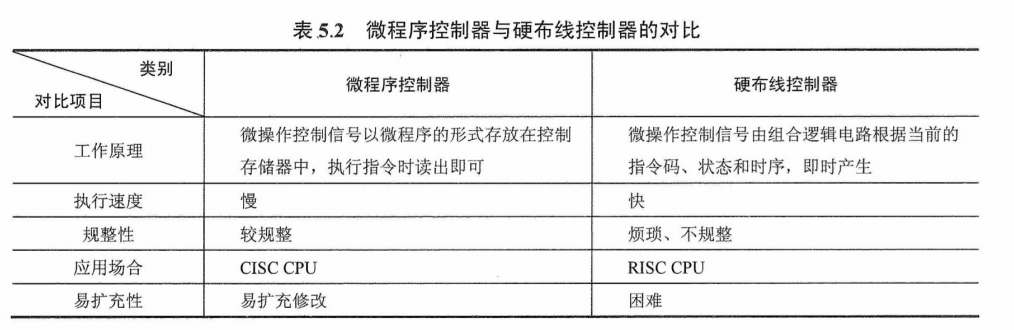
指令流水线
指令流水线的基本概念
一条指令的执行过程可分解为若干阶段,每个阶段由相应的功能部件完成。如果将各阶段视为相应的流水段,则指令的执行过程就构成了一条指令流水线。采用流水线技术只需增加少量硬件就能把计算机的运算速度提高几倍,因此成为计算机中普遍使用的一种并行处理技术。
指令流水的定义
根据计算机的不同,具体的分法也不同。例如,图5.16把一条指令的执行过程分为如下 $\color{red}{\text{三}}$ 个阶段(或过程)。
图片详情

$\color{green}{\text{取指}}$ :根据PC内容访问主存储器,取出一条指令送到IR中。
$\color{green}{\text{分析}}$ :对指令操作码进行译码,按照给定的寻址方式和地址字段中的内容形成操作数的有效地址EA,并从有效地址EA中取出操作数。
$\color{green}{\text{执行}}$ :根据操作码字段,完成指令规定的功能,即把运算结果写到通用寄存器或主存中。
当多条指令在处理器中执行时,可以采用以下两种方式。
1)顺序执行方式。前一条指令执行完后,才启动下一条指令,如图5.17(a)所示。假设取指、分析、执行三个阶段的时间都相等,用t表示,顺序执行n条指令所用时间T为
$$
T=3nt
$$
传统冯·诺依曼机采用顺序执行方式,又称串行执行方式。其优点是控制简单,硬件代价小;缺点是执行指令的速度较慢,在任何时刻,处理机中只有一条指令在执行,各功能部件的利用率很低。例如取指时内存是忙碌的,而指令执行部件是空闲的。
2)流水线执行方式。为了提高指令的执行速度,可以把取k+1条指令提前到分析第k条指令的期间完成,而将分析第k+1条指令与执行第k条指令同时进行,如图5.17(b)所示。采用此种方式时,执行n条指令所用的时间为
$$
T=(2 + n)t
$$
与顺序执行方式相比,采用流水线执行方式能使指令的执行时间缩短近2/3,各功能部件的利用率明显提高。但为此需要付出硬件上较大开销的代价,控制过程也更复杂。在理想情况下,每个时钟周期都有一条指令进入流水线,处理机中同时有3条指令在执行,每个时钟周期都有一条指令完成,每条指令的时钟周期数(即 CPI)都为1。
图片详情
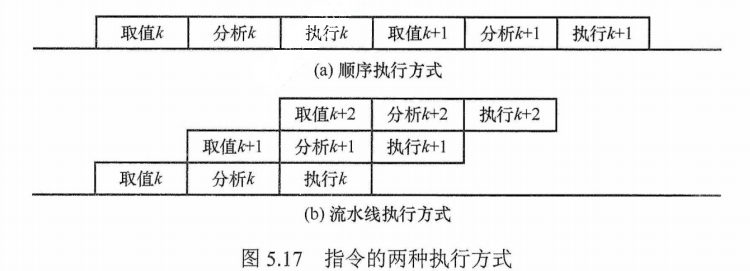
为了进一步获得更高的执行速度,还可以将流水段进一步细分。如将一条指令的执行过程分为 $\color{green}{\text{取指令}}$ 、 $\color{green}{\text{指令译码}}$ 、 $\color{green}{\text{执行}}$ 和 $\color{green}{\text{写回}}$ 四个阶段,就形成了 $\color{red}{\text{四级流水}}$ ;还可进一步分为 $\color{green}{\text{取指令(IF)}}$ 、 $\color{green}{\text{指令译码(ID)}}$ 、 $\color{green}{\text{取操作数(OF)}}$ 、 $\color{green}{\text{执行(EX)}}$ 和 $\color{green}{\text{写回(WB)}}$ ,就形成了 $\color{red}{\text{五级流水}}$ 。
- 各缩写的全称
- IF:instruction fetch
- ID:instruction decode
- EX:execute
- M:memory
- WB:write back
流水线设计的原则是如下:指令流水段个数以最复杂指令所用的功能段个数为准;流水段的长度以最复杂的操作所花的时间为准。假设某条指令的3个阶段所花的时间分别如下。①取指:200ps;分析:100ps;③执行: 150ps。不考虑数据通路中的各种延迟,该指令的总执行时间为450ps。按照流水线设计原则,每个流水段的长度为200ps,所以每条指令的执行时间为600ps,反正比串行执行时增加了150ps。因此,流水线方式并不能缩短一条指令的执行时间,但是,对于整个程序来说,可以大大增加指令执行的吞吐率。
为了利于实现指令流水线,指令集应具有如下特征:
1)指令长度应尽量一致,有利于简化取指令和指令译码操作。否则,取指令所花时间长短不易,使取指部件极其复杂,且也不利于指令译码。
2)指令格式应尽量规整,尽量保证源寄存器的位置相同,有利于在指令未知时就可取寄存器操作数,否则须译码后才能确定指令中各寄存器编号的位置。
3)采用Load/Store 指令,其他指令(如运算指令)都不能访问存储器,这样可把Load/Store指令的地址计算和运算指令的执行步骤规整在同一个周期中,有利于减少操作步骤。
4)数据和指令在存储器中“对齐”存放。这样,有利于减少访存次数,使所需数据在一个流水段内就能从存储器中得到。
流水线的表示方法
通常用时空图来直观地描述流水线的工作过程,如图5.18所示。
在时空图中,横坐标表示时间,即输入流水线中的各个任务在流水线中所经过的时间。流水线中各个流水段的执行时间都相等时,横坐标就被分割成相等长度的时间段。纵坐标表示空间,即流水线的每个流水段(对应各执行部件)。
在图5.18中,第一条指令$\text{I}_1$在时刻$t_0$进入流水线,在时刻$t_4$流出流水线。第二条指令$\text{I}——2$在时刻$t_1$进入流水线,在时刻$t_5$流出流水线。以此类推,每经过一个$\Delta t$时间,便有一条指令进入流水线,从时刻t4开始有一条指令流出流水线。
从图5.18中可以看出,当$t_8$ =$8\Delta t$ 时,流水线上便有5条指令流出。若采用串行方式执行指令,当$t_8$ =$8\Delta t$时,只能执行2条指令,可见使用流水线方式成倍地提高了计算机的速度。
图片详情
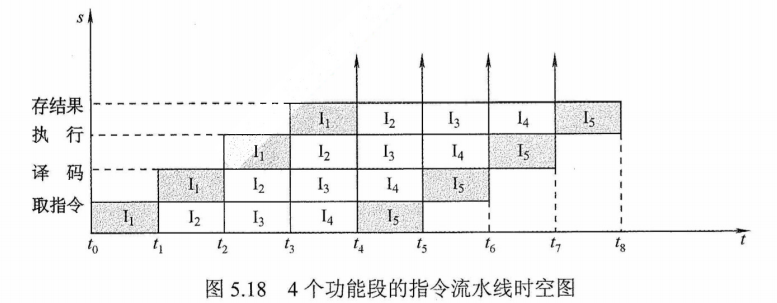
流水线方式的特点
与传统的串行执行方式相比,采用流水线方式具有如下特点:
1)把一个任务(一条指令或一个操作)分解为几个有联系的子任务,每个子任务由一个专门的功能部件来执行,并依靠多个功能部件并行工作来缩短程序的执行时间。
2)流水线每个功能段部件后面都要有一个缓冲寄存器,或称锁存器,其作用是保存本流水段的执行结果,供给下一流水段使用。
3)流水线中各功能段的时间应尽量相等,否则将引起堵塞、断流。
4)只有连续不断地提供同一种任务时才能发挥流水线的效率,所以在流水线中处理的必须是连续任务。在采用流水线方式工作的处理机中,要在软件和硬件设计等多方面尽量为流水线提供连续的任务。
5)流水线需要有装入时间和排空时间。装入时间是指第一个任务进入流水线到输出流水线的时间。排空时间是指最后一个任务进入流水线到输出流水线的时间。
流水线的分类
按照不同的分类标准,可以把流水线分成多种不同的种类。下面从几个不同的角度介绍流水线的基本分类方法。
部件功能级、处理机级和处理机间级流水线
根据流水线使用级别的不同,流水线可分为部件功能级流水线、处理机级流水线和处理机间流水线。
$\color{red}{\text{部件功能级流水}}$ 将复杂的算术逻辑运算组成流水线工作方式。例如,可将浮点加法操作分成求阶差、对阶、尾数相加及结果规格化等4个子过程。
$\color{red}{\text{处理机级流水}}$ 把一条指令解释过程分成多个子过程,如前面提到的取指、译码、执行、访存和写回5个子过程。
处理机间流水是一种宏流水,其中每个处理机完成某一专门任务,各个处理机得到的结果需存放在与下一个处理机共享的存储器中。
单功能流水线和多功能流水线
按可以完成的功能,流水线可分为单功能流水线和多功能流水线。
$\color{red}{\text{单功能流水线}}$ 是指只能实现一种固定的专门功能的流水线; $\color{red}{\text{多功能流水线}}$ 是指通过各段间的不同连接方式可以同时或不同时地实现多种功能的流水线。
动态流水线和静态流水线
按同一时间内各段之间的连接方式,流水线可分为静态流水线和动态流水线。
$\color{red}{\text{静态流水线}}$ 指在同一时间内,流水线的各段只能按同一种功能的连接方式工作。
$\color{red}{\text{动态流水线}}$ 指在同一时间内,当某些段正在实现某种运算时,另一些段却正在进行另一种运算。这样对提高流水线的效率很有好处,但会使流水线控制变得很复杂。
线性流水线和非线性流水线
按流水线的各个功能段之间是否有反馈信号,流水线可分为线性流水线与非线性流水线。
$\color{red}{\text{线性流水线}}$ 中,从输入到输出,每个功能段只允许经过一次,不存在反馈回路。 $\color{red}{\text{非线性流水线}}$ 存在反馈回路,从输入到输出的过程中,某些功能段将数次通过流水线,这种流水线适合进行线性递归的运算。
流水线的每个子过程由专用的功能段实现,各功能段所需的时间应尽量相等。否则,时间长的功能段将成为流水线的瓶颈。
影响流水线的因素
在指令流水线中,可能会遇到一些情况使得流水线无法正确执行后续指令而引起流水线阻塞或停顿,这种现象称为流水线冲突(冒险)。导致流水线冲突的原因主要有3种: $\color{green}{\text{资源冲突}}$ (结构冒险)、 $\color{green}{\text{数据冲突}}$ (数据冒险)和 $\color{green}{\text{控制冲突}}$ (控制冒险)。
资源冲突
由于多条指令在同一时刻争用同一资源而形成的冲突称为资源冲突,即由硬件资源竞争造成的冲突,有以下两种解决办法:
1)前一指令访存时,使后一条相关指令(以及其后续指令)暂停一个时钟周期。
2)单独设置数据存储器和指令存储器,使取数和取指令操作各自在不同的存储器中进行。
事实上,现代计算机都引入了Cache机制,而L1 Cache通常采用数据Cache和指令Cache分离的方式,因而也就避免了资源冲突的发生。
数据冲突
在一个程序中,下一条指令会用到当前指令计算出的结果,此时这两条指令即为数据冲突。当多条指令重叠处理时就会发生冲突,数据冲突可分为三类(结合综合题3理解):
1) $\color{green}{\text{写后读}}$ (Read After Write,RAW)相关:表示当前指令将数据写入寄存器后,下一条指令才能从该寄存器读取数据。否则,先读后写,读到的就是错误(旧)数据。
2) $\color{green}{\text{读后写}}$ (Write After Read,WAR)相关:表示当前指令读出数据后,下一条指令才能写该寄存器。否则,先写后读,读到的就是错误(新)数据。
3) $\color{green}{\text{写后写}}$ (Write After Write,WAW)相关:表示当前指令写入寄存器后,下一条指令才能写该寄存器。否则,下一条指令在当前指令之前写,将使寄存器的值不是最新值。解决的办法有以下几种:
1)把遇到数据相关的指令及其后续指令都暂停一至几个时钟周期,直到数据相关问题消失后再继续执行,可分为硬件阻塞(stall)和软件插入“NOP”指令两种方法。
2)设置相关专用通路,即不等前一条指令把计算结果写回寄存器组,下一条指令也不再读寄存器组,而直接把前一条指令的 ALU的计算结果作为自己的输入数据开始计算过程,使本来需要暂停的操作变得可以继续执行,这称为数据旁路技术。
3)通过编译器对数据相关的指令编译优化的方法,调整指令顺序来解决数据相关。
解决的办法有以下几种:
1)把遇到数据相关的指令及其后续指令都暂停一至几个时钟周期,直到数据相关问题消失后再继续执行,可分为硬件阻塞(stall)和软件插入“NOP”指令两种方法。
2)设置相关专用通路,即不等前一条指令把计算结果写回寄存器组,下一条指令也不再读寄存器组,而直接把前一条指令的 ALU的计算结果作为自己的输入数据开始计算过程,使本来需要暂停的操作变得可以继续执行,这称为数据旁路技术。
3)通过编译器对数据相关的指令编译优化的方法,调整指令顺序来解决数据相关。
控制冲突
一条指令要确定下一条指令的位置,例如在执行转移、调用或返回等指令时会改变PC值,而造成断流,会引起控制冒险。解决的办法有以下几种:
1)对转移指令进行分支预测,尽早生成转移目标地址。分支预测分为简单(静态)预测和动态预测。静态预测总是预测条件不满足,即继续执行分支指令的后续指令。动态预测根据程序执行的历史情况,进行动态预测调整,有较高的预测准确率。
2)预取转移成功和不成功两个控制流方向上的目标指令。
3)加快和提前形成条件码。
4)提高转移方向的猜准率。
注意:Cache缺失的处理过程也会引起流水线阻塞。在不过多增加硬件成本的情况下,如何尽可能地提高指令流水线的运行效率是选用指令流水线技术必须解决的关键问题。
流水线的性能指标
- $\color{red}{\text{Q}}$ :没怎么看懂
衡量流水线性能的主要指标有吞吐率、加速比和效率。下面以线性流水线为例分析流水线的主要性能指标,其分析方法和有关公式也适用于非线性流水线。
$$
TP=\dfrac{n}{T_k}
$$
式中,$n$是任务数,$T_k$是处理完$n$个任务所用的时间。下面以流水线中各段执行时间都相等为例来讨论流水线的 $\color{green}{\text{吞吐率}}$ 。
图5.19所示为各段执行时间均相等的流水线时空图。在输入流水线中的任务连续的理想情况下,一条k段线性流水线能够在k+n-1个时钟周期内完成n个任务。在图5.19中,k为流水线的段数,△t为时钟周期。得出流水线的实际吞吐率为
$$
TP = \dfrac{n}{(k+n-1) \Delta} t
$$
连续输入的任务数$n\to \infty$时,得最大吞吐率为$TP_{max}= 1/\Delta t$ 。
图片详情
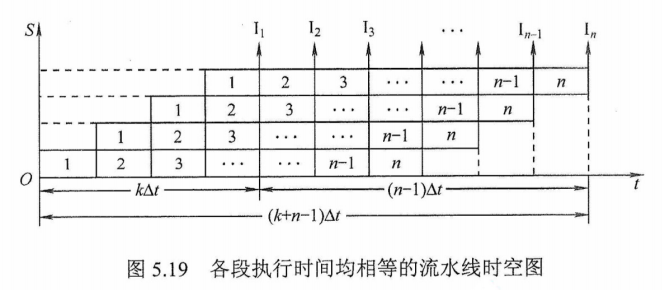
完成同样一批任务,不使用流水线所用的时间与使用流水线所用的时间之比,称为流水线的 $\color{green}{\text{加速比}}$ 。
设$T_0$表示不使用流水线时的执行时间,即顺序执行所用的时间;$T_k$表示使用流水线时的执行时间,则计算流水线加速比(S)的基本公式为
$$
S=\dfrac{T_0}{T_k}
$$
若流水线各段执行的时间都相等,则一条k段流水线完成n个任务所需的时间为$T_k=(k + n-1)\Delta t$。而不使用流水线,即顺序执行$n$个任务时,所需的时间为$T_0= kn\Delta t$。将$T_0$和$T_k$值代入上式,得实际加速比为
$$
S=\dfrac{kn\Delta t}{(k+n-1)\Delta t}=\dfrac{kn}{(k+n-1)}
$$
流水线的效率
流水线的设备利用率称为流水线的 $\color{green}{\text{效率}}$ 。在时空图上,流水线的效率定义为完成$n$个任务占用的时空区有效面积,与$n$ 个任务所用的时间及$k$ 个流水段所围成的时空区总面积之比。因此,流水线的效率包含了时间和空间两个因素。
- $\color{red}{\text{Q}}$ :啥玩意儿为啥还有空间的说法
$n$个任务占用的时空区有效面积就是顺序执行n个任务所使用的总时间$T_0$,而n 个任务所用的时间与k个流水段所围成的时空区总面积为 $kT_k$,其中$T_k$是流水线完成n个任务所使用的总时间,因此计算流水线效率(E)的一般公式为
$$
E = \dfrac{n\text{个任务占用的时空区有效面积}}{n个任务所用的时间与k个流水段所围成的时空区总面积} = \dfrac{T_0}{kT_k}
$$
若流水线的各段执行时间相等,上式中的分子部分是n 个任务实际占用的有效面积,分母部分是完成n个任务所用的时间与k个流水段所围成的总面积。因此,通过时空图来计算流水线的效率非常方便。
流水线的各段执行时间均相等,当连续输入的任务数$n \to \infty$时,最高效率为$E_{max}=1$。
超标量流水线的基本概念
超标量流水线技术
每个时钟周期内可并发多条独立指令,即以并行操作方式将两条或多条指令编译并执行,为此需配置多个功能部件。
超标量计算机不能调整指令的执行顺序,因此通过编译优化技术,把可并行执行的指令搭配起来,挖掘更多的指令并行性,如图5.20所示。
图片详情
超流水线技术
在一个时钟周期内再分段,在一个时钟周期内一个功能部件使用多次。
不能调整指令的执行顺序,靠编译程序解决优化问题,如图5.21所示。
图片详情
超长指令字
由编译程序挖掘出指令间潜在的并行性,将多条能并行操作的指令组合成一条具有多个操作码字段的超长指令字(可达几百位),为此需要采用多个处理部件。
本章小结
CPU分为哪几部分?分别实现什么功能?
CPU分为运算器和控制器。其中运算器主要负责数据的加工,即对数据进行算术和逻辑运算。控制器是整个系统的指挥中枢,对整个计算机系统进行有效的控制,包括指令控制、操作控制、时间控制和中断处理。
指令和数据均存放在内存中,计算机如何从时间和空间上区分它们是指令还是数据?
从时间上讲,取指令事件发生在“取指周期”,取数据事件发生在“执行周期”。从空间上讲,从内存读出的指令流流向控制器(指令寄存器),从内存读出的数据流流向运算器(通用寄存器)。
什么是指令周期、机器周期和时钟周期?它们之间有何关系?
CPU每取出并执行一条指令所需的全部时间称为指令周期;机器周期是在同步控制的机器中,执行指令周期中一步相对完整的操作(指令步)所需的时间,通常安排机器周期长度=主存周期;时钟周期是指计算机主时钟的周期时间,它是计算机运行时最基本的时序单位,对应完成一个微操作所需的时间,通常时钟周期=计算机主频的倒数。
指令周期是否有一个固定值?为什么?
由于计算机中各种指令执行所需的时间差异很大,因此为了提高CPU的运行效率,即使在同步控制的机器中,不同指令的指令周期长度都是不一致的,即指令周期对不同的指令来说不是一个固定值。
什么是微指令?它和上一章谈到的指令有什么关系?
控制部件通过控制线向执行部件发出各种控制命令,通常把这种控制命令称为微命令,而一组实现一定操作功能的微命令的组合,构成一条微指令。许多条微指令组成的序列构成微程序,微程序完成对指令的解释执行。指令,即指机器指令。每条指令可以完成一个独立的算术运算或逻辑运算操作。在采用微程序控制器的CPU中,一条指令对应一个微程序,一个微程序由许多微指令构成,一条微指令会发出很多不同的微命令。
什么是指令流水线?指令流水线相对于传统计算机体系结构的优势是什么?如何计算指令流水线的加速比?
指令流水线是把指令分解为若干子过程,通过将每个子过程与其他子过程并行执行,来提高计算机的吞吐率的技术。采用流水线技术只需增加少量硬件就能把计算机的运算速度提高几倍,因此成为计算机中普遍使用的一种并行处理技术,通过在同一个时间段使用各功能部件,使得利用率明显提高。
流水线的加速比指的是完成同样一批任务,不使用流水线所用的时间与使用流水线所用的时间之比。一条k段流水线理论上的最大加速比为 $S_{max}$ = k。因此,在现代计算机中提高流水线段数有利于提高计算机的吞吐量。具体的加速比要使用时空图来计算。
常见问题和易混淆知识点
流水线越多,并行度就越高。是否流水段越多,指令执行越快?
$\color{red}{\text{错误}}$ ,因为如下:
1)流水段缓冲之间的额外开销增大。每个流水段有一些额外开销用于缓冲间传送数据、进行各种准备和发送等功能,这些开销加长了一-条指令的整个执行时间,当指令间逻辑上相互依赖时,开销更大。
2)流水段间控制逻辑变多、变复杂。用于流水线优化和存储器(或寄存器)冲突处理的控制逻辑将随流水段的增加而大增,这可能导致用于流水段之间控制的逻辑比段本身的控制逻辑更复杂。
有关指令相关、数据相关的几个概念
1)两条连续的指令读取相同的寄存器时,会产生读后读(Read After Read,RAR)相关,这种相关不会影响流水线。
2)某条指令要读取上一条指令所写入的寄存器时,会产生写后读(Read After Write,RAW)相关,它称数据相关或真相关,影响流水线。按序流动的流水线只可能出现RAW相关。
3)某条指令的上条指令要读/写该指令的输出寄存器时,会产生读后写(Write After Read,WAR)和写后写(Write After Write, WAW)相关。在非按序流动的流水线中,既可能发生RAW相关,又可能发生WAR相关和 WAW相关。
对流水线影响最严重的指令相关是数据相关。
总线
【考纲内容】
(一)总线概述
总线的基本概念;总线的分类;总线的组成及性能指标
(二)总线操作和定时
同步定时方式;异步定时方式
(三)总线标准
【复习提示】
本章的知识点较少,其中总线仲裁及总线操作和定时方式是难点。本章内容通常以选择题的形式出现,特别是系统总线的特点、性能指标、各种仲裁方式的特点、异步定时方式及常见的总线标准和特点等。总线带宽的计算也可能结合其他章节出综合题。
在学习本章时,请读者思考以下问题:
1)引入总线结构有什么好处?
2)引入总线结构会导致什么问题?如何解决?
请读者在学习本章的过程中寻找答案,本章末尾会给出参考答案。
总线概述
随着计算机的发展和应用领域的不断扩大,IO 设备的种类和数量也越来越多。为了更好地解决IO设备和主机之间连接的灵活性问题,计算机的结构从分散连接发展为总线连接。为了进一步简化设计,又提出了各类总线标准。
总线基本概念
总线的定义
总线是一组能为多个部件分时共享的公共信息传送线路。分时和共享是总线的两个特点。
$\color{green}{\text{分时}}$ 是指同一时刻只允许有一个部件向总线发送信息,若系统中有多个部件,则它们只能分时地向总线发送信息。
$\color{green}{\text{共享}}$ 是指总线上可以挂接多个部件,各个部件之间互相交换的信息都可通过这组线路分时共享。在某一时刻只允许有一个部件向总线发送信息,但多个部件可同时从总线上接收相同的信息。
总线设备
总线上所连接的设备,按其对总线有无控制功能可分为主设备和从设备两种。
$\color{green}{\text{主设备}}$ :总线的主设备是指获得总线控制权的设备。
$\color{green}{\text{从设备}}$ :总线的从设备是指被主设备访问的设备,它只能响应从主设备发来的各种总线命令。
总线特性
总线特性是指 $\color{green}{\text{机械特性}}$ (尺寸、形状)、 $\color{green}{\text{电气特性}}$ (传输方向和有效的电平范围)、 $\color{green}{\text{功能特性}}$ (每根传输线的功能)和 $\color{green}{\text{时间特性}}$ (信号和时序的关系)。
总线的猝发传输方式
在一个总线周期内传输存储地址连续的多个数据字的总线传输方式,称为 $\color{green}{\text{猝发传送}}$ 。
- 又称突发传输
- 传送一个起始地址之后,可以连续读取连续的地址的内容
- 没有突发传输的话,后面的内容每一次都要传送地址
总线的分类
计算机系统中的总线,按功能划分为以下3类。
$\color{green}{\text{片内总线}}$
片内总线是芯片内部的总线,它是CPU 芯片内部寄存器与寄存器之间、寄存器与ALU 之间的公共连接线。
$\color{green}{\text{系统总线}}$
系统总线是计算机系统内各功能部件(CPU、主存、I/O接口)之间相互连接的总线。按系统总线传输信息内容的不同,又可分为3类:数据总线、地址总线和控制总线。
1)$\color{green}{\text{数据总线}}$ 用来传输各功能部件之间的数据信息,它是双向传输总线,其位数与 $\color{green}{\text{机器字长}}$ 、 $\color{green}{\text{存储字长}}$ 有关。
2)$\color{green}{\text{地址总线}}$ 用来指出数据总线上的源数据或目的数据所在的 $\color{green}{\text{主存单元}}$ 或 $\color{green}{\text{I/O端口的地址}}$ ,它是单向传输总线,地址总线的位数与主存地址空间的大小有关。
3)$\color{green}{\text{控制总线}}$ 传输的是控制信息,包括CPU送出的控制命令和主存(或外设)返回CPU的反馈信号。
注意区分数据通路和数据总线:各个功能部件通过数据总线连接形成的数据传输路径称为数据通路。数据通路表示的是数据流经的路径,而 $\color{green}{\text{数据总线}}$ 是承载的媒介。
$\color{green}{\text{通信总线}}$
通信总线是在计算机系统之间或计算机系统与其他系统(如远程通信设备、测试设备)之间传送信息的总线,通信总线也称外部总线。
此外,按时序控制方式可将总线划分为 $\color{green}{\text{同步总线}}$ 和 $\color{green}{\text{异步总线}}$ ,还可按数据传输格式将总线划分为 $\color{green}{\text{并行总线}}$ 和 $\color{green}{\text{串行总线}}$ 。
系统总线的结构
总线结构通常分为单总线结构、双总线结构和三总线结构等。
单总线结构
单总线结构将CPU、主存、IO设备(通过IO接口)都挂在一组总线上,允许IO设备之间、IO设备与主存之间直接交换信息,如图6.1所示。CPU与主存、CPU与外设之间可直接进行信息交换,而无须经过中间设备的干预。
注意,单总线并不是指只有一根信号线,系统总线按传送信息的不同可细分为地址总线、数据总线和控制总线。
优点:结构简单,成本低,易于接入新的设备;缺点:带宽低、负载重,多个部件只能争用唯一的总线,且不支持并发传送操作。
图6.1单总线结构
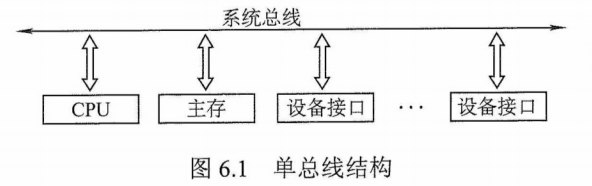
双总线结构
双总线结构有两条总线:一条是 $\color{green}{\text{主存总线}}$ ,用于在CPU、主存和通道之间传送数据;另一条是 $\color{green}{\text{IO总线}}$ ,用于在多个外部设备与通道之间传送数据,如图6.2所示。
优点:将低速IO设备从单总线上分离出来,实现了存储器总线和IO总线分离。缺点:需要增加通道等硬件设备。
三总线结构
三总线结构是在计算机系统各部件之间采用3条各自独立的总线来构成信息通路,这3条总线分别为 $\color{green}{\text{主存总线}}$ 、 $\color{green}{\text{IO总线}}$ 和 $\color{green}{\text{直接内存访问(DMA)总线}}$ ,如图6.3所示。
图片详情
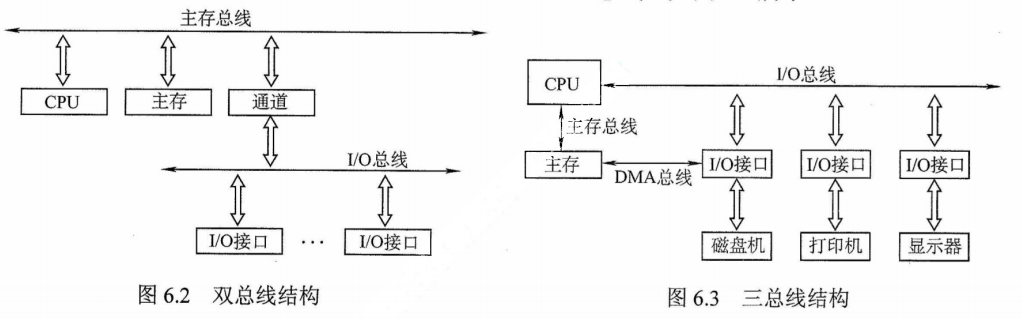
主存总线用于在CPU和内存之间传送地址、数据和控制信息。IO总线用于在CPU和各类外设之间通信。DMA总线用于在内存和高速外设之间直接传送数据。
优点:提高了IO设备的性能,使其更快地响应命令,提高系统吞吐量。缺点:系统工作效率较低。
总线的性能指标
1)总线的 $\color{green}{\text{传输周期}}$ 。指一次总线操作所需的时间(包括申请阶段、寻址阶段、传输阶段和结束阶段),简称总线周期。总线传输周期通常由若干总线时钟周期构成。
2)总线 $\color{green}{\text{时钟周期}}$ 。即机器的时钟周期。计算机有一个统一的时钟,以控制整个计算机的各个部件,总线也要受此时钟的控制。
3)总线的 $\color{green}{\text{工作频率}}$ 。总线上各种操作的频率,为总线周期的倒数。实际上指1秒内传送几次数据。若总线周期=N个时钟周期,则总线的工作频率=时钟频率/N。
4)总线的 $\color{green}{\text{时钟频率}}$ 。即机器的时钟频率,它为时钟周期的倒数。
5)总线 $\color{green}{\text{宽度}}$ 。又称总线位宽,它是总线上同时能够传输的数据位数,通常指 $\color{green}{\text{数据总线}}$ 的根数,如32根称为32位总线。
6)总线 $\color{green}{\text{带宽}}$ 。可理解为总线的 $\color{green}{\text{数据传输率}}$ ,即单位时间内总线上可传输数据的位数,通常用每秒传送信息的字节数来衡量,单位可用字节/秒(B/s)表示。总线带宽=总线工作频率×(总线宽度/8)。
注意:总线带宽和总线宽度应加以区别。
7)总线 $\color{green}{\text{复用}}$ 。总线复用是指一种信号线在不同的时间传输不同的信息,因此可以使用较少的线传输更多的信息,从而节省空间和成本。
8)信号 $\color{red}{\text{线数}}$ 。 $\color{green}{\text{地址总线}}$ 、 $\color{green}{\text{数据总线}}$ 和 $\color{green}{\text{控制总线}}$ 3种总线数的总和称为信号线数。其中,总线的最主要性能指标为总线宽度、总线(工作)频率、总线带宽,总线带宽是指总线本身所能达到的最高传输速率,它是衡量总线性能的重要指标。
三者关系:总线带宽=总线宽度×总线频率。
例如,总线工作频率为22MHz,总线宽度为16位,则总线带宽=22×(16/8)=44MB/s。
*总线仲裁
为解决多个主设备同时竞争总线控制权的问题,应当采用总线仲裁部件,以某种方式选择一个主设备优先获得总线控制权。只有获得了总线控制权的设备,才能开始传送数据。
总线仲裁方式按其仲裁控制机构的设置可分为集中仲裁方式和分布仲裁方式两种。
集中仲裁方式
总线控制逻辑基本上集中于一个设备(如CPU)中。将所有的总线请求集中起来,利用一个特定的裁决算法进行裁决,称为集中仲裁方式。集中仲裁方式有链式查询方式、计数器定时查询方式和独立请求方式三种。
链式查询方式
链式查询方式如图6.4所示。总线上所有的部件共用一根总线请求线,当有部件请求使用总线时,需经此线发总线请求信号到总线控制器。由总线控制器检查总线是否忙,若总线不忙,则立即发总线响应信号,经总线响应线BG串行地从一个部件传送到下一个部件,依次查询。若响应信号到达的部件无总线请求,则该信号立即传送到下一个部件;若响应信号到达的部件有总线请求,则信号被截住,不再传下去。
图6.4 链式查询方式
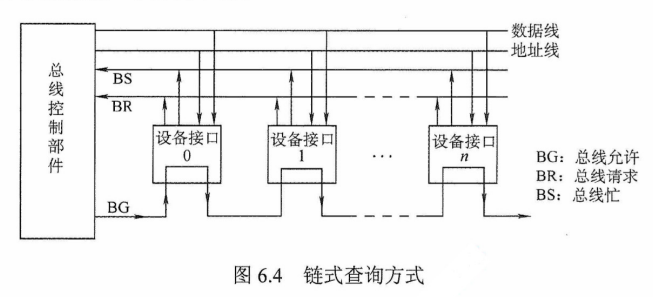
在链式查询中,部件离总线控制器越近,其优先级越高;部件离总线控制器越远,其优先级越低。
优点:链式查询方式优先级固定。此外,只需很少几根控制线就能按一定优先次序实现总线控制,结构简单,扩充容易。
缺点:对硬件电路的故障敏感,且优先级不能改变。当优先级高的部件频繁请求使用总线时,会使优先级较低的部件长期不能使用总线。
计数器定时查询方式
计数器定时查询方式如图6.5所示。它采用一个计数器控制总线使用权,相对链式查询方式多了一组设备地址线,少了一根总线响应线BG。它仍共用一根总线请求线,当总线控制器收到总线请求信号并判断总线空闲时,计数器开始计数,计数值通过设备地址线发向各个部件。当地址线上的计数值与请求使用总线设备的地址一致时,该设备获得总线控制权,同时中止计数器的计数及查询。
图6.5计数器定时查询方式
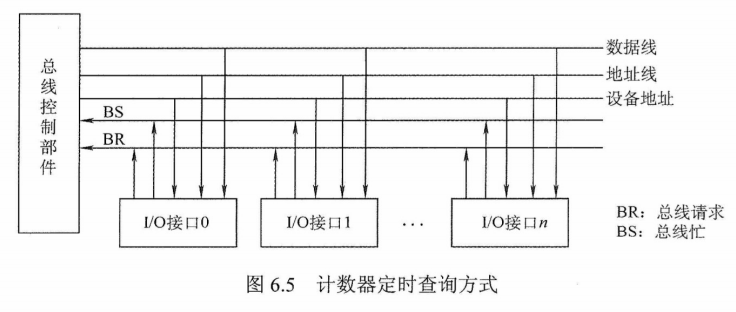
优点:计数可从“0”开始,此时一旦设备的优先次序被固定,设备的优先级就按0,1,$\cdots$,n的顺序降序排列,而且固定不变;计数也可从上一次的终点开始,即采用一种循环方法,此时设备使用总线的优先级相等;计数器的初值还可由程序设置,因此优先次序可以改变,且这种方式对电路的故障没有链式查询方式敏感。
缺点:增加了控制线数(若设备有n个,则大致需要 $\lceil log_2n \rceil$+2条控制线),控制也比相对链式查询要复杂。
独立请求方式
独立请求方式如图6.6所示。每个设备均有一对总线请求线BR,和总线允许线BG;。当总线上的部件需要使用总线时,经各自的总线请求线发送总线请求信号,在总线控制器中排队,当总线控制器按一定的优先次序决定批准某个部件的请求时,给该部件发送总线响应信号,该部件接到此信号后就获得了总线使用权,开始传送数据。
图片详情
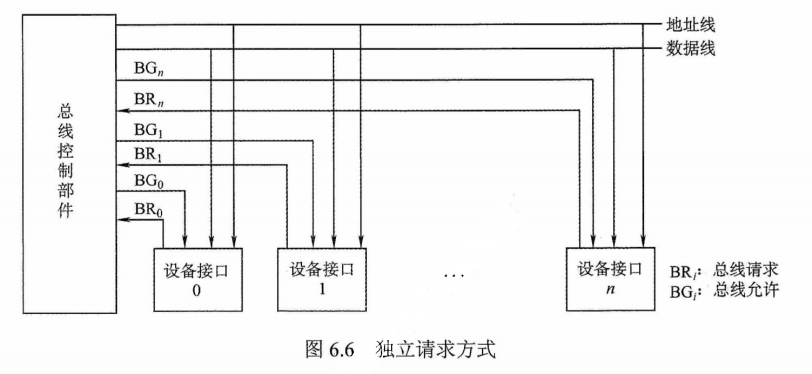
优点:响应速度快,总线允许信号BG直接从控制器发送到有关设备,而不必在设备间传递或查询,而且对优先次序的控制相当灵活。
缺点:控制线数量多(设备有n个,需要2n+1条控制线,其中加的那条控制线为BS线,基作用是让设备向总线控制部件反馈已使用完总线),总线控制逻辑更复杂。
为方便记忆,下面归纳了3种集中仲裁方式的区别与联系(假设设备有n 个),如表6.1所示。
图片详情
分布仲裁方式
分布仲裁方式不需要中央仲裁器,每个潜在的主模块都有自己的仲裁号和仲裁器。当它们有总线请求时,就会把它们各自唯一的仲裁号发送到共享的仲裁总线上,每个仲裁器将从仲裁总线上得到的仲裁号与自己的仲裁号进行比较。若仲裁总线上的仲裁号优先级高,则它的总线请求不予响应,并撤销它的仲裁号。最后,获胜者的仲裁号保留在仲裁总线上。
总线操作和定时
总线定时是指总线在双方交换数据的过程中需要时间上配合关系的控制,这种控制称为总线定时,其实质是一种协议或规则,主要有同步和异步两种基本定时方式。
总线传输的4个阶段
一个总线周期通常可分为以下4个阶段:
1) $\color{green}{\text{申请分配阶段}}$ 。由需要使用总线的主模块(或主设备)提出申请,经总线仲裁机构决定将下一传输周期的总线使用权授予某一申请者。也可将此阶段细分为传输请求和总线仲裁两个阶段。
2) $\color{green}{\text{寻址阶段}}$ 。取得使用权的主模块通过总线发出本次要访问的从模块(或从设备)的地址及有关命令,启动参与本次传输的从模块。
3) $\color{green}{\text{传输阶段}}$ 。主模块和从模块进行数据交换,可单向或双向进行数据传送。
4) $\color{green}{\text{结束阶段}}$ 。主模块的有关信息均从系统总线上撤除,让出总线使用权。
同步定时方式
所谓同步定时方式,是指系统采用一个统一的时钟信号来协调发送和接收双方的传送定时关系。时钟产生相等的时间间隔,每个间隔构成一个总线周期。在一个总线周期中,发送方和接收方可以进行一次数据传送。因为采用统一的时钟,每个部件或设备发送或接收信息都在固定的总线传送周期中,一个总线的传送周期结束,下一个总线的传送周期开始。
优点:传送速度快,具有较高的传输速率;总线控制逻辑简单。
缺点:主从设备属于强制性同步;不能及时进行数据通信的有效性检验,可靠性较差。
同步通信适用于总线长度较短及总线所接部件的存取时间比较接近的系统。
异步定时方式
在异步定时方式中,没有统一的时钟,也没有固定的时间间隔,完全依靠传送双方相互制约的“握手”信号来实现定时控制。通常,把交换信息的两个部件或设备分为主设备和从设备,主设备提出交换信息的“请求”信号,经接口传送到从设备;从设备接到主设备的请求后,通过接口向主设备发出“回答”信号。
优点:总线周期长度可变,能保证两个工作速度相差很大的部件或设备之间可靠地进行信息交换,自动适应时间的配合。
缺点:比同步控制方式稍复杂一些,速度比同步定时方式慢。
根据“请求”和“回答”信号的撤销是否互锁,异步定时方式又分为以下3种类型。
- $\color{green}{\text{不互锁方式}}$ 。主设备发出“请求”信号后,不必等到接到从设备的“回答”信号,而是经过一段时间便撤销“请求”信号。而从设备在接到“请求”信号后,发出“回答”信号,并经过一段时间后自动撤销“回答”信号。双方不存在互锁关系,如图6.7(a)所示。
2) $\color{green}{\text{半互锁方式}}$ 。主设备发出“请求”信号后,必须在接到从设备的“回答”信号后,才撤销“请求”信号,有互锁的关系。而从设备在接到“请求”信号后,发出“回答”信号,但不必等待获知主设备的“请求”信号已经撤销,而是隔一段时间后自动撤销“回答”信号,不存在互锁关系。半互锁方式如图6.7(b)所示。
3) $\color{green}{\text{全互锁方式}}$ 。主设备发出“请求”信号后,必须在从设备“回答”后才撤销“请求”信号;从设备发出“回答”信号后,必须在获知主设备“请求”信号已撤销后,再撤销其“回答”信号。双方存在互锁关系,如图6.7(c)所示。
图片详情
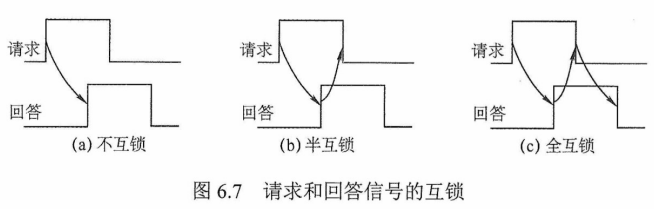
总线标准
总线标准是国际上公布或推荐的互连各个模块的标准,是把各种不同的模块组成计算机系统时必须遵守的规范。按总线标准设计的接口可视为通用接口,在接口的两端,任何一方只需根据总线标准的要求完成自身方面的功能要求,而无须了解对方接口的要求。
常见的总线标准
目前,典型的总线标准有ISA、EISA、VESA、PCI、PCI-Express、AGP、RS-232C、USB等。它们的主要区别是总线宽度、带宽、时钟频率、寻址能力、是否支持突发传送等。
1)ISA。ISA (Industry Standard Architecture,工业标准体系结构)总线是最早出现的微型计算机的系统总线,应用在IBM的AT机上。
2)EISA。EISA (Extended Industry Standard Architecture,扩展的ISA)总线是为配合32位CPU而设计的扩展总线,EISA对ISA完全兼容。
3)VESA。VESA (Video Electronics Standards Association,视频电子标准协会)总线是一个32位标准的计算机局部总线,是针对多媒体PC要求高速传送活动图像的大量数据应运而生的。
- PCI。PCI (Peripheral Component Interconnect,外部设备互连)总线是高性能的32位或64 位总线,是专为高度集成的外围部件、扩充插板和处理器/存储器系统设计的互连机制。目前常用的PCI适配器有显卡、声卡、网卡等。PCI总线支持即插即用。PCI总线是一个与处理器时钟频率无关的高速外围总线,属于局部总线。PCI总线可通过桥连接实现多层PCI总线。
5)PCI-Express (PCI-E)。PCI-Express是最新的总线和接口标准,它将全面取代现行的PCI和AGP,最终统一总线标准。
6)AGP。AGP (Accelerated Graphics Port,加速图形接口)是一种视频接口标准,专用于连接主存和图形存储器,属于局部总线。AGP技术为传输视频和三维图形数据提供了切实可行的解决方案。
- RS-232C。RS-232C (Recommended Standard,RS)是由美国电子工业协会(EIA)推荐的一种串行通信总线,是应用于串行二进制交换的数据终端设备(DTE)和数据通信设备(DCE)之间的标准接口。
8)USB。USB (Universal Serial Bus,通用串行总线)是一种连接外部设备的IO总线,属于设备总线。具有即插即用、热插拔等优点,有很强的连接能力。
9)PCMCIA。PCMCIA (Personal Computer Memory Card International Association)是广泛应用于笔记本电脑的一种接口标准,是一个用于扩展功能的小型插槽。PCMCIA具有即插即用功能。
10)IDE。IDE (Integrated Drive Electronics,集成设备电路),更准确地称为ATA,是一种IDE接口磁盘驱动器接口类型,硬盘和光驱通过IDE接口与主板连接。
11)SCSI。SCSI (Small Computer System Interface,小型计算机系统接口)是一种用于计算机和智能设备之间(硬盘、软驱、光驱、打印机等)系统级接口的独立处理器标准。SCSI是一种智能的通用接口标准。
12)SATA。SATA (Serial Advanced Technology Attachment,串行高级技术附件)是一种基于行业标准的串行硬件驱动器接口,是由Intel、IBM、Dell、APT、Maxtor和 Seagate公司共同提出的硬盘接口规范。
本章小结
引入总线结构有什么好处?
引入总线结构主要有以下优点:
${\textstyle\unicode{x2460}}$ 简化了系统结构,便于系统设计制造。
②大大减少了连线数目,便于布线,减小体积,提高系统的可靠性。
③便于接口设计,所有与总线连接的设备均采用类似的接口。
${\textstyle\unicode{x2463}}$ 便于系统的扩充、更新与灵活配置,易于实现系统的模块化。
⑤便于设备的软件设计,所有接口的软件对不同的接口地址进行操作。
${\textstyle\unicode{x2465}}$ 便于故障诊断和维修,同时也能降低成本。
引入总线会导致什么问题?如何解决?
引入总线后,总线上的各个设备分时共享同一总线,当总线上多个设备同时要求使用总线时就会导致总线的冲突。为解决多个主设备同时竞争总线控制权的问题,应当采用总线仲裁部件,以某种方式选择一个主设备优先获得总线控制权,只有获得了总线控制权的设备才能开始数据传送。
输入/输出系统
【考纲内容】
(一)1O系统基本概念
(二)外部设备
输入设备:键盘、鼠标
输出设备:显示器、打印机
外存储器:硬盘存储器、磁盘阵列
(三)I/O接口(I/O控制器)
I/O接口的功能和基本结构;I/O端口及其编址
(四)I/O方式
程序查询方式
程序中断方式
中断的基本概念,中断响应过程,中断处理过程,多重中断和中断屏蔽的概念
DMA方式
DMA控制器的组成,DMA传送过程
【复习提示】
I/O方式是本章的重点和难点,每年不仅会以选择题的形式考查基本概念和原理,而且可能会以综合题的形式考查,特别是各种I/O方式效率的相关计算,中断方式的各种原理、特点、处理过程、中断屏蔽,DMA方式的特点、传输过程、与中断方式的区别等。
在学习本章时,请读者思考以下问题:
1)I/O设备有哪些编址方式?各有何特点?
2)CPU响应中断应具备哪些条件?
请读者在学习本章的过程中寻找答案,本章末尾会给出参考答案。
I/O系统基本概念
输入/输出系统
输入/输出是以主机为中心而言的,将信息从外部设备传送到主机称为输入,反之称为输出。输入/输出系统解决的主要问题是对各种形式的信息进行输入和输出的控制。
I/O 系统中的几个基本概念如下:
1) $\color{green}{\text{外部设备}}$ 。包括输入/输出设备及通过输入/输出接口才能访问的外存储设备。
2) $\color{green}{\text{接口}}$ 。在各个外设与主机之间传输数据时进行各种协调工作的逻辑部件。协调包括传输过程中速度的匹配、电平和格式转换等。
3) $\color{green}{\text{输入设备}}$ 。用于向计算机系统输入命令和文本、数据等信息的部件。键盘和鼠标是最基本的输入设备。
4) $\color{green}{\text{输出设备}}$ 。用于将计算机系统中的信息输出到计算机外部进行显示、交换等的部件。显示器和打印机是最基本的输出设备。
5) $\color{green}{\text{外存设备}}$ 。指除计算机内存及CPU 缓存等外的存储器。硬磁盘、光盘等是最基本的外存设备。
一般来说,I/O系统由I/O软件和I/O硬件两部分构成:
1)I/O $\color{green}{\text{软件}}$ 。包括驱动程序、用户程序、管理程序、升级补丁等。通常采用I/O 指令和通道指令实现CPU与I/O设备的信息交换。
2)I/O $\color{green}{\text{硬件}}$ 。包括外部设备、设备控制器和接口、I/O总线等。通过设备控制器来控制I/O设备的具体动作;通过I/O接口与主机(总线)相连。
I/O控制方式
在输入/输出系统中,经常需要进行大量的数据传输,而传输过程中有各种不同的I/O 控制方式,基本的控制方式主要有以下4种:
1) $\color{green}{\text{程序查询方式}}$ 。由CPU通过程序不断查询I/O设备是否已做好准备,从而控制I/O设备与主机交换信息。
2) $\color{green}{\text{程序中断方式}}$ 。只在I/O设备准备就绪并向CPU发出中断请求时才予以响应。
3) $\color{green}{\text{DMA方式}}$ 。主存和I/O设备之间有一条直接数据通路,当主存和I/O设备交换信息时,无须调用中断服务程序。
4) $\color{green}{\text{通道方式}}$ 。在系统中设有通道控制部件,每个通道都挂接若干外设,主机在执行I/O命令时,只需启动有关通道,通道将执行通道程序,从而完成I/O操作。
其中,方式1)和方式2)主要用于数据传输率较低的外部设备,方式3)和方式4)主要用于数据传输率较高的设备。
外部设备
外部设备也称外围设备,是除主机外的能直接或间接与计算机交换信息的装置。最基本的外部设备主要有键盘、鼠标、显示器、打印机、磁盘存储器和光盘存储器等。
输入设备
键盘
键盘是最常用的输入设备,通过它可发出命令或输入数据。
键盘通常以矩阵的形式排列按键,每个键用符号标明其含义和作用。每个键相当于一个开关,按下键时,电信号连通;松开键时,弹簧弹起键,电信号断开。
键盘输入信息可分为3个步骤:①查出按下的是哪个键;②将该键翻译成能被主机接收的编码,如ASCII码;③将编码传送给主机。
鼠标
鼠标是常用的定位输入设备,它把用户的操作与计算机屏幕上的位置信息相联系。常用的鼠标有 $\color{green}{\text{机械式}}$ 和 $\color{green}{\text{光电式}}$ 两种。
工作原理:鼠标在平面上移动时,其底部传感器把运动的方向和距离检测出来,从而控制光标做相应的运动。
输出设备
显示器
显示设备种类繁多,按显示设备所用的显示器件分类,有阴极射线管(CRT)显示器、液晶显示器(LCD)、发光二极管(LED)显示器等。按所显示的信息内容分类,有字符显示器、图形显示器和图像显示器3大类。显示器属于用点阵方式运行的设备,有以下主要参数。
$\color{green}{\text{屏幕大小}}$ :以对角线长度表示,常用的有12~29英寸等。
$\color{green}{\text{分辨率}}$ :所能表示的像素个数,屏幕上的每个光点就是一个像素,以宽和高的像素数的乘积表示,如800×600、1024×768和1280×1024等。
$\color{green}{\text{灰度级}}$ :灰度级是指黑白显示器中所显示的像素点的亮暗差别,在彩色显示器中则表现为颜色的不同,灰度级越多,图像层次越清楚、逼真,典型的有8位(256级)、16位等。
$\color{green}{\text{刷新}}$ :光点只能保持极短的时间便会消失,为此必须在光点消失之前再重新扫描显示一遍,这个过程称为刷新。
$\color{green}{\text{刷新频率}}$ :指单位时间内扫描整个屏幕内容的次数。按照人的视觉生理,刷新频率大于30Hz时才不会感到闪烁,通常显示器的刷新频率为60~120Hz。
$\color{green}{\text{显示存储器}}$ (VRAM):也称刷新存储器,为了不断提高刷新图像的信号,必须把一帧图像信息存储在刷新存储器中。其存储容量由图像分辨率和灰度级决定,分辨率越高,灰度级越多,刷新存储器容量越大。
$$
\text{VRAM容量} = \text{分辨率} \times \text{灰度级位数}
$$
$$
\text{VRAM容量} = \text{分辨率} \times \text{灰度级位数}
$$
(1)阴极射线管(CRT)显示器
CRT 显示器主要由电子枪、偏转线圈、荫罩、高压石墨电极、荧光粉涂层和玻璃外壳5部分组成,具有可视角度大、无坏点、色彩还原度高、色度均匀、可调节的多分辨率模式、响应时间极短等目前LCD难以超过的优点。
按显示信息内容不同,可分为字符显示器、图形显示器和图像显示器;按扫描方式不同,可分为光栅扫描和随机扫描两种显示器。下面简要介绍字符显示器和图形显示器。
${\textstyle\unicode{x2460}}$ 字符显示器。显示字符的方法以点阵为基础。点阵是指由m×n个点组成的阵列。点阵的多少取决于显示字符的质量和字符窗口的大小。字符窗口是指每个字符在屏幕上所占的点数,它包括字符显示点阵和字符间隔。
将点阵存入由ROM构成的字符发生器中,在CRT进行光栅扫描的过程中,从字符发生器中依次读出某个字符的点阵,按照点阵中О和1代码的不同控制扫描电子束的开或关,从而在屏幕上显示字符。对应于每个字符窗口,所需显示字符的ASCII 代码被存放在视频存储器VRAM中,以备刷新。
${\textstyle\unicode{x2461}}$ 图形显示器。将所显示图形的一组坐标点和绘图命令组成显示文件存放在缓冲存储器中,缓存中的显示文件传送给矢量(线段)产生器,产生相应的模拟电压,直接控制电子束在屏幕上的移动。为在屏幕上保留持久稳定的图像,需按一定的频率对屏幕反复刷新。这种显示器的优点是分辨率高且显示的曲线平滑。目前高质量的图形显示器采用这种随机扫描方式。缺点是当显示复杂图形时,会有闪烁感。
(2)液晶显示器(LCD)
原理:利用液晶的电光效应,由图像信号电压直接控制薄膜晶体管,再间接控制液晶分子的光学特性来实现图像的显示。
特点:体积小、重量轻、省电、无辐射、绿色环保、画面柔和、不伤眼等。
(3)LED(发光二极管)显示器
原理:通过控制半导体发光二极管来显示文字、图形、图像等各种信息。
LCD与LED是两种不同的显示技术。LCD是由液态晶体组成的显示屏,而LED 则是由发光二极管组成的显示屏。与LCD相比,LED 显示器在亮度、功耗、可视角度和刷新速率等方面都更具优势。
打印机
打印机是计算机的输出设备之一,用于将计算机的处理结果打印在相关介质上。
按工作原理,打印机分为击打式和非击打式两大类;按工作方式,打印机分为点阵打印机、针式打印机、喷墨式打印机、激光打印机等。
(1)针式打印机
原理:在联机状态下,主机发出打印命令,经接口、检测和控制电路,间歇驱动纵向送纸和打印头横向移动,同时驱动打印机间歇冲击色带,在纸上打印出所需的内容。
特点:针式打印机擅长“多层复写打印”,实现各种票据或蜡纸等的打印。其工作原理简单,造价低廉,耗材(色带)便宜,但打印分辨率和打印速度不够高。
(2)喷墨式打印机
原理:带电的喷墨雾点经过电极偏转后,直接在纸上形成所需字形。彩色喷墨打印机基于三基色原理,即分别喷射3种颜色的墨滴,按一定的比例混合出所要求的颜色。
特点:打印噪声小,可实现高质量彩色打印,通常打印速度比针式打印机快;但防水性差,高质量打印需要专用打印纸。
(3)激光打印机
原理:计算机输出的二进制信息,经过调制后的激光束扫描,在感光鼓上形成潜像,再经过显影、转印和定影,在纸上得到所需的字符或图像。
特点:打印质量高、速度快、噪声小、处理能力强;但耗材多、价格较贵、不能复写打印多份,且对纸张的要求高。
激光打印机是将激光技术和电子显像技术相结合的产物。感光鼓(也称硒鼓)是激光打印机的核心部件。
外存储器
计算机的外存储器又称辅助存储器,目前主要使用磁表面存储器。
所谓“磁表面存储”,是指把某些磁性材料薄薄地涂在金属铝或塑料表面上作为载磁体来存储信息。磁盘存储器、磁带存储器和磁鼓存储器均属于磁表面存储器。
磁表面存储器的优点:①存储容量大,位价格低;②记录介质可重复使用;记录信息可长期保存而不丢失,甚至可脱机存档;④非破坏性读出,读出时不需要再生。缺点:存取速度慢,机械结构复杂,对工作环境要求较高。
(1)磁盘设备的组成
${\textstyle\unicode{x2460}}$ 存储区域。一块硬盘含有若干记录面,每个记录面划分为若干磁道,而每条磁道又划分为若干扇区,扇区(也称块)是磁盘读写的最小单位,即磁盘按块存取。
- $\color{green}{\text{磁头数}}$ (Heads):即记录 $\color{green}{\text{面数}}$ ,表示硬盘共有多少个磁头,磁头用于读取/写入盘片上记录面的信息,一个记录面对应一个磁头。
- $\color{green}{\text{柱面数}}$ (Cylinders):表示硬盘每面盘片上有多少条 $\color{green}{\text{磁道}}$ 。在一个盘组中,不同记录面的相同编号(位置)的诸磁道构成一个圆柱面。
- $\color{green}{\text{扇区数}}$ (Sectors):表示每条磁道上有多少个 $\color{green}{\text{扇区}}$ 。
${\textstyle\unicode{x2461}}$ 硬盘存储器的组成。 $\color{red}{\text{硬盘存储器}}$ 由 $\color{green}{\text{磁盘驱动器}}$ 、 $\color{green}{\text{磁盘控制器}}$ 和 $\color{green}{\text{盘片}}$ 组成。
- 磁盘 $\color{green}{\text{驱动器}}$ 。核心部件是磁头组件和盘片组件,温彻斯特盘是一种可移动磁头固定盘片的硬盘存储器。
- 磁盘 $\color{green}{\text{控制器}}$ 。硬盘存储器和主机的接口,主流的标准有IDE、SCSI、SATA等。
(2)磁记录原理
原理:磁头和磁性记录介质相对运动时,通过电磁转换完成读/写操作。
编码方法:按某种方案(规律),把一连串的二进制信息变换成存储介质磁层中一个磁化翻转状态的序列,并使读/写控制电路容易、可靠地实现转换。
磁记录方式:通常采用 $\color{green}{\text{调频制}}$ (FM)和 $\color{green}{\text{改进型调频制}}$ (MFM)的记录方式。
(3)磁盘的性能指标
① $\color{red}{\text{磁盘的容量}}$ 。磁盘容量有 $\color{green}{\text{非格式化}}$ 容量和 $\color{green}{\text{格式化}}$ 容量之分。非格式化容量是指磁记录表面可利用的磁化单元总数,它由道密度和位密度计算而来;格式化容量是指按照某种特定的记录格式所能存储信息的总量。格式化后的容量比非格式化容量要小。
${\textstyle\unicode{x2461}}$ $\color{red}{\text{记录密度}}$ 。记录密度是指盘片单位面积上记录的二进制信息量,通常以 $\color{green}{\text{道密度}}$ 、 $\color{green}{\text{位密度}}$ 和 $\color{green}{\text{面密度}}$ 表示。道密度是沿磁盘半径方向单位长度上的磁道数,位密度是磁道单位长度上能记录的二进制代码位数,面密度是位密度和道密度的乘积。
${\textstyle\unicode{x2462}}$ $\color{red}{\text{平均存取时间}}$ 。 $\color{green}{\text{平均存取时间由寻道时间}}$ (磁头移动到目的磁道的时间)、 $\color{green}{\text{旋转延迟时间}}$ (磁头定位到要读写扇区的时间,取旋转一周时间的一半)和 $\color{green}{\text{传输时间}}$ (传输数据所花费的时间)三部分构成。由于寻道和找扇区的距离远近不一,因此前两部分通常取平均值。
④ $\color{red}{\text{数据传输率}}$ 。磁盘存储器在单位时间内向主机传送数据的字节数,称为数据传输率。假设磁盘转数为r转/秒,每条磁道容量为N字节,则数据传输率为
$$
D_r=rN
$$
(4)磁盘地址
主机向磁盘控制器发送寻址信息,磁盘的地址一般如图7.1所示。
图片详情

若系统中有4个驱动器,每个驱动器带一个磁盘,每个磁盘256个磁道、16个盘面,每个盘面划分为16个扇区,则每个扇区地址要18位二进制代码,其格式如图7.2所示。
图片详情

(5)硬盘的工作过程
硬盘的主要操作是寻址、读盘、写盘。每个操作都对应一个控制字,硬盘工作时,第一步是取控制字,第二步是执行控制字。
硬盘属于机械式部件,其读写操作是串行的,不可能在同一时刻既读又写,也不可能在同一时刻读两组数据或写两组数据。
磁盘阵列
RAID(廉价冗余磁盘阵列)是指将多个独立的物理磁盘组成一个独立的逻辑盘,数据在多个物理盘上分割交叉存储、并行访问,具有更好的存储性能、可靠性和安全性。
RAID 的分级如下所示。在 RAID1~RAID5几种方案中,无论何时有磁盘损坏,都可随时拔出受损的磁盘再插入好的磁盘,而数据不会损坏,提升了系统的可靠性。
- RAID0:无冗余和无校验的磁盘阵列。
- RAID1:镜像磁盘阵列。
- RAID2:采用纠错的海明码的磁盘阵列。
- RAID3:位交叉奇偶校验的磁盘阵列
- RAID4:块交叉奇偶校验的磁盘阵列。·
- RAID5:无独立校验的奇偶校验磁盘阵列。
RAID0把连续多个数据块交替地存放在不同物理磁盘的扇区中,几个磁盘交叉并行读写,不仅扩大了存储容量,而且提高了磁盘数据存取速度,但RAID0没有容错能力。
为了提高可靠性,RAID1使两个磁盘同时进行读写,互为备份,若一个磁盘出现故障,可从另一磁盘中读出数据。两个磁盘当一个磁盘使用,意味着容量减少一半。
总之,RAID通过同时使用多个磁盘,提高了传输率;通过在多个磁盘上并行存取来大幅提高存储系统的数据吞吐量;通过镜像功能,提高安全可靠性;通过数据校验,提供容错能力。
*光盘存储器
光盘存储器是利用光学原理读/写信息的存储装置,它采用聚焦激光束对盘式介质以非接触方式记录信息。
完整的光盘存储系统由光盘片、光盘驱动器、光盘控制器和光盘驱动软件组成。光盘片由透明的聚合物基片、铝合金反射层、漆膜保护层的固盘构成。
特点:具有存储密度高、携带方便、成本低、容量大、存储期限长和容易保存等优点。光盘的类型如下:
光盘的类型如下:
- CD-ROM:只读型光盘,只能读出其中的内容,不能写入或修改。
- CD-R:只可写入一次信息,之后不可修改。
- CD-RW:可读可写光盘,可以重复读写。
- DVD-ROM:高容量的CD-ROM,DVD表示通用数字化多功能光盘。
固态硬盘
微小型高档笔记本计算机采用高性能Flash Memory作为硬盘来记录数据,这种“硬盘”称固态硬盘。固态硬盘除需要Flash Memory外,还需要其他硬件和软件的支持。
I/O接口
I/O接口(I/O控制器)是主机和外设之间的交接界面,通过接口可以实现主机和外设之间的信息交换。主机和外设具有各自的工作特点,它们在信息形式和工作速度上具有很大的差异,接口正是为了解决这些差异而设置的。
I/O接口的功能
I/O接口的主要功能如下:
1)实现主机和外设的 $\color{green}{\text{通信联络控制}}$ 。解决主机与外设时序配合问题,协调不同工作速度的外设和主机之间交换信息,以保证整个计算机系统能统一、协调地工作。
2)进行 $\color{green}{\text{地址译码}}$ 和 $\color{green}{\text{设备选择}}$ 。CPU送来选择外设的地址码后,接口必须对地址进行译码以产生设备选择信息,使主机能和指定外设交换信息。
3)实现 $\color{green}{\text{数据缓冲}}$ 。CPU与外设之间的速度往往不匹配,为消除速度差异,接口必须设置数据缓冲寄存器,用于数据的暂存,以避免因速度不一致而丢失数据。
4)信号 $\color{green}{\text{格式的转换}}$ 。外设与主机两者的电平、数据格式都可能存在差异,接口应提供计算机与外设的信号格式的转换功能,如电平转换、并/串或串/并转换、模/数或数/模转换等。
5)传送 $\color{green}{\text{控制命令}}$ 和 $\color{green}{\text{状态信息}}$ 。CPU要启动某一外设时,通过接口中的命令寄存器向外设发出启动命令;外设准备就绪时,则将“准备好”状态信息送回接口中的状态寄存器,并反馈给CPU。外设向CPU提出中断请求时,CPU也应有相应的响应信号反馈给外设。
I/O接口的基本结构
如图7.3所示,I/O接口在主机侧通过I/O总线与内存、CPU相连。通过 $\color{green}{\text{数据总线}}$ ,在 $\color{green}{\text{数据缓冲寄存器}}$ 与内存或CPU的寄存器之间进行数据传送。同时接口和设备的状态信息被记录在 $\color{green}{\text{状态寄存器}}$ 中,通过数据线将状态信息送到CPU。CPU对外设的控制命令也通过数据线传送,一般将其送到I/O接口的控制寄存器。状态寄存器和控制寄存器在传送方向上是相反的。
图片详情
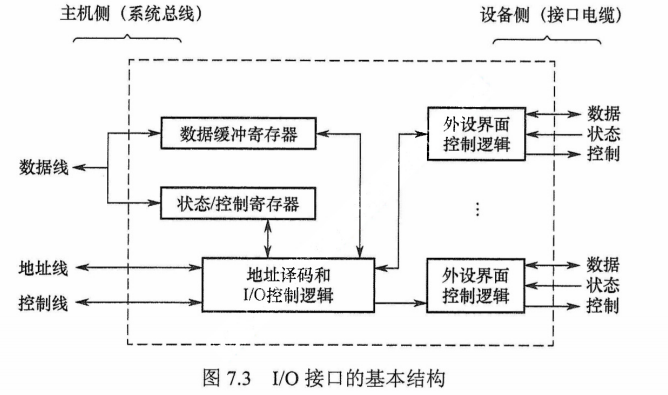
接口中的地址线用于给出要访问的I/O接口中的寄存器的地址,它和读/写控制信号一起被送到I/O接口的控制逻辑部件,其中地址信息用以选择和主机交换信息的寄存器,通过控制线传送来的读/写信号确认是读寄存器还是写寄存器,此外控制线还会传送一些仲裁信号和握手信号。
接口中的I/O控制逻辑还要能对控制寄存器中的命令字进行译码,并将译码得到的控制信号通过外设界面控制逻辑送到外设,同时将数据缓冲寄存器的数据发送到外设或从外设接收数据到数据缓冲寄存器。另外,它还要具有收集外设状态到状态寄存器的功能。
对数据缓冲寄存器、状态/控制寄存器的访问操作是通过相应的指令来完成的,通常称这类指令为I/O指令,I/O指令只能在操作系统内核的底层I/O软件中使用,它们是一种 $\color{green}{\text{特权指令}}$ 。
注意:接口和端口是两个不同的概念。端口是指接口电路中可以进行读/写的寄存器,若干端口加上相应的控制逻辑才可以组成接口。
I/O接口的类型
从不同的角度看,I/O接口可以分为不同的类型。
1)按数据传送方式可分为 $\color{green}{\text{并行接口}}$ (一字节或一个字的所有位同时传送)和 $\color{green}{\text{串行接口}}$ (一位一位地传送),接口要完成数据格式的转换。
注意:这里所说的数据传送方式指的是外设和接口一侧的传送方式,而在主机和接口一侧,数据总是并行传送的。
2)按主机访问I/O设备的控制方式可分为 $\color{green}{\text{程序查询接口}}$ 、 $\color{green}{\text{中断接口}}$ 和 $\color{green}{\text{DMA接口}}$ 等。
3)按功能选择的灵活性可分为 $\color{green}{\text{可编程接口}}$ 和 $\color{green}{\text{不可编程接口}}$ 。
I/O端口及其编址
I/O端口是指接口电路中可被CPU直接访问的寄存器,主要有 $\color{green}{\text{数据端口}}$ 、 $\color{green}{\text{状态端口}}$ 和 $\color{green}{\text{控制端口}}$ ,若干端口加上相应的控制逻辑电路组成接口。通常,CPU能对数据端口执行读写操作,但对状态端口只能执行读操作,对控制端口只能执行写操作。
I/O端口要想能够被CPU访问,就必须要对各个端口进行编号,每个端口对应一个端口地址。而对I/O端口的编址方式有与存储器统一编址和独立编址两种。
1) $\color{green}{\text{统一编址}}$ ,又称存储器映射方式,是指把I/O端口当作存储器的单元进行地址分配,这种方式CPU不需要设置专门的I/O指令,用统一的 $\color{green}{\text{访存指令}}$ 就可以访问I/O端口。优点:不需要专门的输入/输出指令,可使CPU访问UO 的操作更灵活、更方便,还可使端口有较大的编址空间。缺点:端口占用存储器地址,使内存容量变小,而且利用存储器编址的VO设备进行数据输入/输出操作,执行速度较慢。
2) $\color{green}{\text{独立编址}}$ ,又称I/O映射方式,I/O端口的地址空间与主存地址空间是两个独立的地址空间,因而无法从地址码的形式上区分,需要设置专门的 $\color{green}{\text{I/O指令}}$ 来访问I/O端口。优点:输入/输出指令与存储器指令有明显区别,程序编制清晰,便于理解。缺点:输入/输出指令少,一般只能对端口进行传送操作,尤其需要CPU提供存储器读/写、I/O设备读/写两组控制信号,增加了控制的复杂性。
I/O 方式
输入/输出系统实现主机与I/O设备之间的数据传送,可以采用不同的控制方式,各种方式在代价、性能、解决问题的着重点等方面各不相同,常用的I/O方式有 $\color{green}{\text{程序查询}}$ 、 $\color{green}{\text{程序中断}}$ 、 $\color{green}{\text{DMA}}$ 和 $\color{green}{\text{通道}}$ 等,其中前两种方式更依赖于CPU中程序指令的执行。
程序查询方式
信息交换的控制完全由主机执行程序实现,程序查询方式接口中设置一个数据缓冲寄存器(数据端口)和一个设备状态寄存器(状态端口)。主机进行I/O操作时,先发出询问信号,读取设备的状态并根据设备状态决定下一步操作究竟是进行数据传送还是等待。
程序查询方式的工作流程如下(见图7.4)
${\textstyle\unicode{x2460}}$ CPU执行初始化程序,并预置传送参数。
②向I/O接口发出命令字,启动I/O设备。
${\textstyle\unicode{x2462}}$ 从外设接口读取其状态信息。
${\textstyle\unicode{x2463}}$ CPU 不断查询I/O设备状态,直到外设准备就绪。
${\textstyle\unicode{x2464}}$ 传送一次数据。
⑥修改地址和计数器参数。
${\textstyle\unicode{x2466}}$ 判断传送是否结束,若未结束转第 ${\textstyle\unicode{x2462}}$ 步,直到计数器为0。
图7.4 程序查询方式流程图
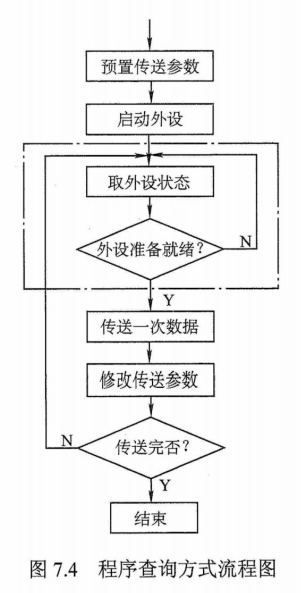
在这种控制方式下,CPU一旦启动I/O,就必须停止现行程序的运行,并在现行程序中插入一段程序。程序查询方式的主要特点是CPU有“踏步”等待现象,CPU与I/O串行工作。这种方式的接口设计简单、设备量少,但CPU 在信息传送过程中要花费很多时间来查询和等待,而且在 $\color{green}{\text{一段时间}}$ 内只能和 $\color{green}{\text{一台}}$ 外设交换信息,效率大大降低。
程序中断方式
现代计算机系统中都配有完善的异常和中断处理系统,CPU的数据通路中有相应的异常和中断的检测和响应逻辑,在外设接口中有相应的中断请求和控制逻辑,操作系统中有相应的中断服务程序。这些中断硬件线路和中断服务程序有机结合,共同完成异常和中断的处理过程。
异常和中断
(1)异常
异常是指由 $\color{green}{\text{CPU内部}}$ 异常引起的意外事件,分为 $\color{green}{\text{硬故障中断}}$ 和 $\color{green}{\text{程序性异常}}$ 。 $\color{red}{\text{硬故障中断}}$ 是由硬连线出现异常引起的,如 $\color{green}{\text{电源掉电}}$ 、 $\color{green}{\text{存储器线路错}}$ 等。 $\color{red}{\text{程序性异常}}$ 也称 $\color{red}{\text{软中断}}$ ,是指在CPU内部因执行指令而引起的异常事件。如 $\color{green}{\text{整除0}}$ 、 $\color{green}{\text{溢出}}$ 、 $\color{green}{\text{断点}}$ 、 $\color{green}{\text{单步跟踪}}$ 、 $\color{green}{\text{非法指令}}$ 、 $\color{green}{\text{栈溢出}}$ 、 $\color{green}{\text{地址越界}}$ 、 $\color{green}{\text{缺页}}$ 、分时系统中的 $\color{green}{\text{时间片中断}}$ 及用户态到核心态的 $\color{green}{\text{切换}}$ 等。按发生异常的报告方式和返回方式不同, $\color{red}{\text{内部异常}}$ 可分为 $\color{green}{\text{故障}}$ (Fault)、 $\color{green}{\text{自陷}}$ (Trap)和 $\color{green}{\text{终止}}$ (Abort)三类。
${\textstyle\unicode{x2460}}$ 故障(Fault)
指在引起故障等指令启动后、执行结束前被检测到的异常事件。例如,指令译码时,出现“非法操作码”;取数据时,发生“缺段”或“缺页”;执行整数除法指令时,发现“除数为0”等。对于“缺段”“缺页”等异常处理后,已将所需的段或页面从磁盘调入主存,可回到发生故障的指令继续执行,断点为当前发生故障的指令;对于“非法操作码”“除数为0”等, 因为无法通过异常处理程序恢复故障 ,因此不能回到原断点执行,必须终止进程的执行。
${\textstyle\unicode{x2461}}$ 自陷(Trap)
自陷也称陷阱或陷入,它是预先安排的一种“异常”事件,就像预先设定的“陷阱”一样。通常的做法是:事先在程序中用一条特殊指令或通过某种方式设定特殊控制标志来人为设置一个“陷阱”,当执行到被设置了“陷阱”的指令时,CPU在执行完自陷指令后,自动根据不同“陷阱”类型进行相应的处理,然后返回到自陷指令的下一条指令执行。注意,当自陷指令是转移指令时,并不是返回到下一条指令执行,而是返回到转移目标指令执行。
在80x86中,用于程序调试的“ $\color{green}{\text{断点设置}}$ ”功能就是通过 $\color{green}{\text{自陷}}$ 方式实现的。此外,系统调用指令、条件自陷指令(如MIPS 中 teq、teqi、tne、tnei等一组按条件进入陷阱的指令)等都属于陷阱指令,执行到这些指令时,无条件或有条件地自动调出操作系统内核程序进行执行。
③终止(Abort)
如果在执行指令的过程中发生了使计算机无法继续执行的硬件故障,如电源掉电、线路故障等,那么程序将无法继续执行,只能终止,此时,调出中断服务程序来重启系统。这种异常与故障和自陷不同,不是由特定指令产生的,而是 $\color{green}{\text{随机}}$ 发生的。
(2)外部中断
$\color{red}{\text{外中断}}$ 是指来自CPU外部、与CPU执行指令无关的事件引起的中断,包括 $\color{green}{\text{I/O设备}}$ 发出的I/O 中断(如键盘输入、打印机缺纸等)、 $\color{green}{\text{外部信号中断}}$ (如用户按Esc键),以及各种定时器引起的时钟中断等。外中断在狭义上一般称为中断(书中若未说明,一般是指外中断)。
外中断和内部异常在本质上是一样的,但它们之间有以下两个重要的不同点:
1)“缺页”或“溢出”等异常事件是由特定指令在执行过程中产生的,而中断不和任何指令相关联,也不阻止任何指令的完成。
2)异常的检测是由CPU自身完成的,不必通过外部的某个信号通知CPU。对于中断,CPU必须通过总线获取中断源的标识信息,才能获知哪个设备发生了何种中断。
有些教材也将异常和中断统称为中断,将由CPU内部产生的异常称为内中断,将通过中断请求线INTR和 NMI 从 CPU 外部发出的中断请求称为外中断。
中断的基本概念
程序中断是指在计算机执行现行程序的过程中,出现某些急需处理的异常情况或特殊请求,CPU 暂时中止现行程序,而转去对这些异常情况或特殊请求进行处理,在处理完毕后CPU又自动返回到现行程序的断点处,继续执行原程序。
程序中断的作用如下:
${\textstyle\unicode{x2460}}$ 实现CPU与I/O设备的并行工作。
② $\color{green}{\text{处理}}$ 硬件故障和软件错误。
③实现人机交互,用户 $\color{green}{\text{干预}}$ 机器需要用到中断系统。
④实现多道程序、 $\color{green}{\text{分时操作}}$ , $\color{green}{\text{多道程序}}$ 的切换需借助于中断系统。
⑤实时处理需要借助中断系统来实现 $\color{green}{\text{快速响应}}$ 。
⑥实现应用程序和操作系统(管态程序)的切换,称为“ $\color{green}{\text{软中断}}$ ”。
⑦多处理器系统中各处理器之间的 $\color{green}{\text{信息交流}}$ 和 $\color{green}{\text{任务切换}}$ 。
程序中断方式的思想:CPU在程序中安排好于某个时刻启动某台外设,然后CPU继续执行原来的程序,不需要像查询方式那样一直等待外设准备就绪。一旦外设完成数据传送的准备工作,就主动向CPU发出中断请求,请求CPU为自己服务。在可以响应中断的条件下,CPU暂时中止正在执行的程序,转去执行中断服务程序为外设服务,在中断服务程序中完成一次主机与外设之间的数据传送,传送完成后,CPU返回原来的程序,如图7.5所示。
图片详情
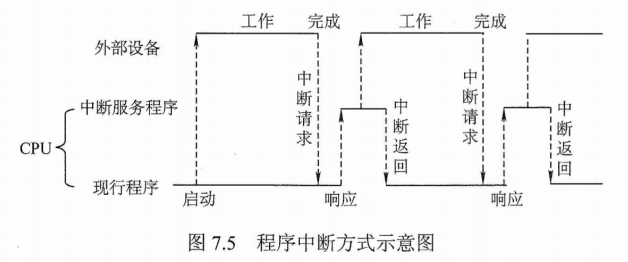
程序中断方式工作流程
(1)中断请求
中断源是请求CPU中断的设备或事件,一台计算机允许有多个中断源。每个中断源向CPU发出中断请求的时间是随机的。为记录中断事件并区分不同的中断源,中断系统需对每个中断源设置中断请求标记触发器INTR,当其状态为“1”时,表示中断源有请求。这些触发器可组成中断请求标记寄存器,该寄存器可集中在CPU中,也可分散在各个中断源中。
内中断皆为 $\color{green}{\text{不可屏蔽中断}}$ 。通过INTR信号线发出的外中断是 $\color{green}{\text{可屏蔽中断}}$ ,在关中断(IF =1)的情况下不会被响应;而通过NMI信号发出的是不可屏蔽中断,即使在关中断(IF=0)的情况下也会被响应。不可屏蔽中断的处理优先级最高,任何时候只要发生不可屏蔽中断,都要中止现行程序的执行,转到不可屏蔽中断处理程序执行。
(2)中断判优
中断系统在任一瞬间只能响应一个中断源的请求。由于许多中断源提出中断请求的时间都是随机的,因此当多个中断源同时提出请求时,需通过中断判优逻辑确定响应哪个中断源的请求,例如故障中断的优先级别较高,然后是I/O中断。
中断判优既可以用硬件实现,又可用软件实现。硬件实现是通过 $\color{green}{\text{硬件排队器}}$ 实现的,它既可以设置在CPU中,又可以分散在各个中断源中,软件实现是通过 $\color{green}{\text{查询程序}}$ 实现的。
一般来说,硬件故障中断属于最高级,其次是软件中断,不可屏蔽中断优于可屏蔽中断,DMA 请求优于I/O 设备传送的中断请求,高速设备优于低速设备,输入设备优于输出设备,实时设备优于普通设备等。
(3 )CPU 响应中断的条件
CPU在满足一定的条件下响应中断源发出的中断请求,并经过一些特定的操作,转去执行中断服务程序。CPU响应中断必须满足以下3个条件:
①中断源有中断请求。
${\textstyle\unicode{x2461}}$ CPU允许中断及开中断。
${\textstyle\unicode{x2462}}$ 一条指令执行完毕,且没有更紧迫的任务。
注意:I/O设备的就绪时间是随机的,而CPU在统一的时刻即每条指令执行阶段结束前向接口发出中断查询信号,以获取I/O 的中断请求,也就是说,CPU响应中断的时间是在每条指令执行阶段的结束时刻。这里说的中断仅指外中断,内中断不属于此类情况。
(4)中断响应
CPU 响应中断后,经过某些操作,转去执行中断服务程序。这些操作是由硬件直接实现的,我们将它称为 $\color{red}{\text{中断隐指令}}$ 。中断隐指令并不是指令系统中的一条真正的指令,它没有操作码,所以中断隐指令是一种不允许也不可能为用户使用的特殊指令。它所完成的操作如下:
${\textstyle\unicode{x2460}}$ $\color{green}{\text{关中断}}$ 。CPU响应中断后,首先要保护程序的断点和现场信息,在保护断点和现场的过程中,CPU不能响应更高级中断源的中断请求。
② $\color{green}{\text{保存断点}}$ 。为保证在中断服务程序执行完毕后能正确地返回到原来的程序,必须将原来程序的断点(指令无法直接读取的 $\color{green}{\text{PC}}$ 和PSWR $\color{green}{\text{等的内容)保存起来。
}}$
${\textstyle\unicode{x2462}}$ $\color{green}{\text{引出中断服务程序}}$ 。实质是取出中断服务程序的入口地址并传送给程序计数器(PC)。
(5)中断向量
每个中断都有一个类型号,每个中断类型号都对应一个中断服务程序,每个中断服务程序都有一个入口地址,CPU必须找到入口地址,即中断向量,把系统中的全部中断向量集中存放到存储器的某个区域内,这个存放中断向量的存储区就称为中断向量表。
CPU 响应中断后,中断硬件会自动将中断向量地址传送到CPU,由 CPU实现程序的切换,这种方法称为中断向量法,采用中断向量法的中断称为向量中断。
注意: $\color{red}{\text{中断向量}}$ 是 $\color{green}{\text{中断服务程序的入口地址}}$ , $\color{red}{\text{中断向量地址}}$ 是指 $\color{green}{\text{中断服务程序的入口地址的地址}}$ 。
(6)中断处理过程
不同计算机的中断处理过程各具特色,就其多数而论,中断处理流程如图7.6所示。
中断处理流程如下:
${\textstyle\unicode{x2460}}$ $\color{green}{\text{关中断}}$ 。在保护断点和现场期间不能被新的中断所打断,必须关中断。否则,若断点或现场保存不完整,在中断服务程序结束后,就不能正确地恢复并继续执行现行程序。
${\textstyle\unicode{x2461}}$ $\color{green}{\text{保存断点}}$ 。断点可以压入堆栈,也可以存入主存的特定单元中。
${\textstyle\unicode{x2462}}$ $\color{green}{\text{引出中断服务程序}}$ 。通常有两种方法寻址中断服务程序的入口地址: $\color{green}{\text{硬件向量法}}$ 和 $\color{green}{\text{软件查询法}}$ 。硬件向量法通过硬件产生中断向量地址,再由中断向量地址找到中断服务程序的入口地址。软件查询法用软件编程的办法寻找入口地址。
注意:硬件产生的实际上是中断类型号,而中断类型号指出了中断向量存放的地址,因此能产生中断向量地址。
${\textstyle\unicode{x2463}}$ $\color{green}{\text{保存现场和屏蔽字}}$ 。进入中断服务程序后首先要保存现场和中断屏蔽字,现场信息是指用户可见的工作寄存器的内容,它存放着程序执行到断点处的现行值。
注意:现场和断点,这两类信息都不能被中断服务程序破坏。现场信息因为用指令可直接访问,所以通常在中断服务程序中通过指令把它们保存到栈中,即由软件实现;而断点信息由CPU在中断响应开始时自动保存到栈或专门的寄存器中,即由硬件实现。
⑤ $\color{green}{\text{开中断}}$ 。允许更高级中断请求得到响应,实现中断嵌套。
⑥ $\color{green}{\text{执行中断服务程序}}$ 。这是中断请求的目的。
⑦ $\color{green}{\text{关中断}}$ 。保证在恢复现场和屏蔽字时不被中断。
⑧ $\color{green}{\text{恢复现场和屏蔽字}}$ 。将现场和屏蔽字恢复到原来的状态。
${\textstyle\unicode{x2468}}$ $\color{green}{\text{开中断、中断返回}}$ 。中断服务程序的最后一条指令通常是一条中断返回指令,使其返回到原程序的断点处,以便继续执行原程序。
其中,①③在CPU进入中断周期后,由中断隐指令(硬件自动)完成;④⑨由中断服务程序完成。
注意:恢复现场是指在中断返回前,必须将寄存器的内容恢复到中断处理前的状态,这部分工作由中断服务程序完成。中断返回由中断服务程序的最后一条中断返回指令完成。
图片详情
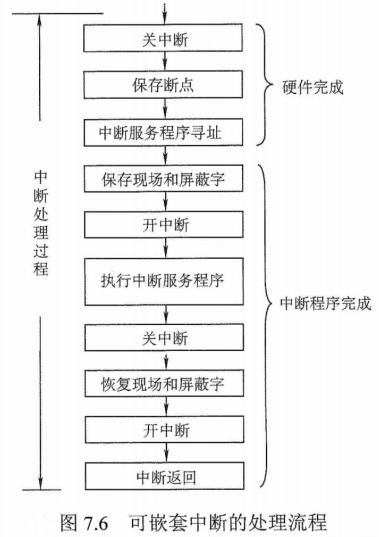
多重中断和中断屏蔽技术
若CPU在执行中断服务程序的过程中,又出现了新的更高优先级的中断请求,而CPU对新的中断请求不予响应,则这种中断称为 $\color{green}{\text{单重中断}}$ ,如图7.7(a)所示。若CPU 暂停现行的中断服务程序,转去处理新的中断请求,则这种中断称为 $\color{green}{\text{多重中断}}$ ,又称 $\color{green}{\text{中断嵌套}}$ ,如图7.7(b)所示。
中断屏蔽技术主要用于多重中断。CPU要具备多重中断的功能,必须满足下列条件:
①在中断服务程序中提前设置开中断指令。
②优先级别高的中断源有权中断优先级别低的中断源。
每个中断源都有一个 $\color{red}{\text{屏蔽触发器}}$ , $\color{green}{\text{1}}$ 表示 $\color{green}{\text{屏蔽该中断源}}$ 的请求, $\color{green}{\text{0}}$ 表示可以 $\color{green}{\text{正常申请}}$ ,所有屏蔽触发器组合在一起便构成一个屏蔽字寄存器,屏蔽字寄存器的内容称为屏蔽字。
关于中断屏蔽字的设置及多重中断程序执行的轨迹,下面通过实例说明。
图片详情
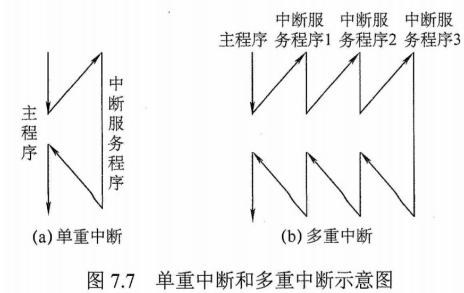
例题

- 中断屏蔽字为什么是这样求
DMA方式
DMA方式是一种 $\color{green}{\text{完全由硬件}}$ 进行成组信息传送的控制方式,它具有程序中断方式的优点,即在数据准备阶段,CPU与外设并行工作。DMA方式在外设与内存之间开辟一条“直接数据通道”,信息传送不再经过CPU,降低了CPU 在传送数据时的开销,因此称为 $\color{green}{\text{直接存储器存取}}$ 方式。由于数据传送不经过CPU,也就不需要保护、恢复CPU现场等烦琐操作。
这种方式适用于磁盘机、磁带机等高速设备大批量数据的传送,它的硬件开销比较大。在DMA方式中,中断的作用仅限于 $\color{green}{\text{故障}}$ 和 $\color{green}{\text{正常传送结束时的处理}}$ 。
DMA方式的特点
主存和 DMA接口之间有一条直接数据通路。由于 DMA方式传送数据不需要经过CPU,因此不必中断现行程序,I/O与主机并行工作,程序和传送并行工作。
DMA方式具有下列特点:
①它使主存与CPU的固定联系脱钩,主存既可被CPU访问,又可被外设访问。
${\textstyle\unicode{x2461}}$ 在数据块传送时,主存地址的确定、传送数据的计数等都由硬件电路直接实现。
③主存中要开辟专用缓冲区,及时供给和接收外设的数据。
${\textstyle\unicode{x2463}}$ DMA传送速度快,CPU和外设并行工作,提高了系统效率。
${\textstyle\unicode{x2464}}$ DMA在传送开始前要通过程序进行预处理,结束后要通过中断方式进行后处理。
DMA控制器的组成
在DMA方式中,对数据传送过程进行控制的硬件称为DMA控制器(DMA接口)。当I/O 设备需要进行数据传送时,通过DMA控制器向CPU提出DMA传送请求,CPU响应之后将让出系统总线,由DMA控制器接管总线进行数据传送。其主要功能如下:
1)接受外设发出的DMA请求,并向CPU发出总线请求。
2) CPU响应此总线请求,发出总线响应信号,接管总线控制权,进入DMA操作周期。
3)确定传送数据的主存单元地址及长度,并自动修改主存地址计数和传送长度计数。
4)规定数据在主存和外设间的传送方向,发出读写等控制信号,执行数据传送操作。
5)向CPU报告DMA操作的结束。
图7.10给出了一个简单的DMA控制器。
图片详情
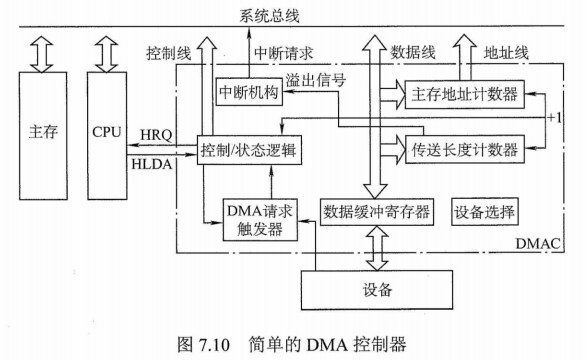
- 主存地址计数器:存放要交换数据的主存地址。
- 传送长度计数器:记录传送数据的长度,计数溢出时,数据即传送完毕,自动发中断请求信号。
- 数据缓冲寄存器:暂存每次传送的数据。
- DMA请求触发器:每当I/O设备准备好数据后,给出一个控制信号,使 DMA请求触发器置位。
- “控制/状态”逻辑:由控制和时序电路及状态标志组成,用于指定传送方向,修改传送参数,并对 DMA请求信号和CPU响应信号进行协调和同步。
- 中断机构:当一个数据块传送完毕后触发中断机构,向CPU提出中断请求。
在 DMA传送过程中,DMA 控制器将接管CPU的地址总线、数据总线和控制总线,CPU的主存控制信号被禁止使用。而当DMA传送结束后,将恢复CPU的一切权利并开始执行其操作。由此可见,DMA控制器必须具有控制系统总线的能力。
DMA的传送方式
主存和I/O设备之间交换信息时,不通过CPU。但当I/O设备和CPU同时访问主存时,可能发生冲突,为了有效地使用主存,DMA控制器与CPU通常采用以下3种方式使用主存:
1)停止CPU访存。当I/O设备有DMA请求时,由DMA 控制器向CPU发送一个停止信号,使 CPU 脱离总线,停止访问主存,直到 DMA传送一块数据结束。数据传送结束后,DMA控制器通知CPU可以使用主存,并把总线控制权交还给CPU。
2)周期挪用(或周期窃取)。当I/O设备有 DMA请求时,会遇到3种情况:①是此时CPU 不在访存(如CPU正在执行乘法指令),因此 I/O 的访存请求与CPU未发生冲突;②是CPU正在访存,此时必须待存取周期结束后,CPU 再将总线占有权让出;③是I/O和 CPU同时请求访存,出现访存冲突,此时CPU 要暂时放弃总线占有权。I/O访存优先级高于CPU访存,因为I/O不立即访存就可能丢失数据,此时由I/O设备挪用一个或几个存取周期,传送完一个数据后立即释放总线,是一种单字传送方式。
3)DMA与CPU交替访存。这种方式适用于CPU 的工作周期比主存存取周期长的情况。例如,若CPU的工作周期是 1.2$\mu$s,主存的存取周期小于0.6$\mu$s,则可将一个CPU周期分为$C_1$和$C_2$,两个周期,其中 $C_1$专供 DMA 访存,$C_2$专供 CPU访存。这种方式不需要总线使用权的申请、建立和归还过程,总线使用权是通过$C_1$和$C_2$分时控制的。
DMA的传送过程
DMA的数据传送过程分为预处理、数据传送和后处理3个阶段:
1) $\color{green}{\text{预处理}}$ 。由CPU 完成一些必要的准备工作。首先,CPU执行几条I/O 指令,用以测试I/O设备状态,向 DMA 控制器的有关寄存器置初值、设置传送方向、启动该设备等。然后,CPU继续执行原来的程序,直到I/O设备准备好发送的数据(输入情况)或接收的数据(输出情况)时,I/O设备向DMA控制器发送DMA请求,再由DMA控制器向CPU 发送总线请求(有时将这两个过程统称为DMA请求),用以传输数据。
2) $\color{green}{\text{数据传送}}$ 。DMA的数据传输可以以单字节(或字)为基本单位,也可以以数据块为基本单位。对于以数据块为单位的传送(如硬盘),DMA占用总线后的数据输入和输出操作都是通过循环来实现的。需要指出的是,这一循环也是由 DMA 控制器(而非通过CPU执行程序)实现的,即数据传送阶段完全由DMA(硬件)控制。
3) $\color{green}{\text{后处理}}$ 。DMA控制器向CPU发送中断请求,CPU执行中断服务程序做DMA结束处理,包括校验送入主存的数据是否正确、测试传送过程中是否出错(错误则转入诊断程序)及决定是否继续使用DMA传送其他数据块等。DMA 的传送流程如图7.11所示。
图片详情
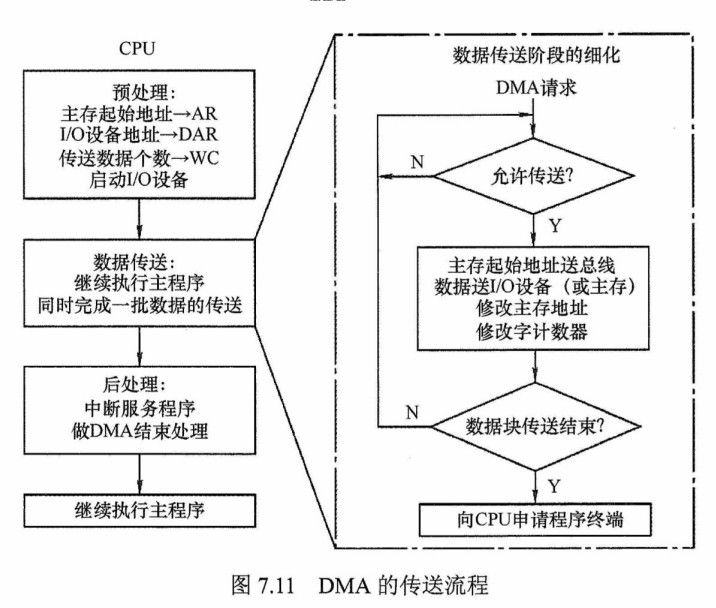
DMA方式和中断方式的区别
DMA方式和中断方式的重要区别如下:
${\textstyle\unicode{x2460}}$ 中断方式是程序的切换,需要保护和恢复现场;而DMA方式除了预处理和后处理,其他时候不占用CPU的任何资源。
${\textstyle\unicode{x2461}}$ 对中断请求的响应只能发生在每条指令执行完毕时(即指令的执行周期后);而对DMA请求的响应可以发生在每个机器周期结束时(在取指周期、间址周期、执行周期后均可),只要CPU不占用总线就可被响应。
${\textstyle\unicode{x2462}}$ 中断传送过程需要CPU的干预;而 DMA传送过程不需要CPU 的干预,因此数据传输率非常高,适合于高速外设的成组数据传送。
${\textstyle\unicode{x2463}}$ DMA请求的优先级高于中断请求。
${\textstyle\unicode{x2464}}$ 中断方式具有对异常事件的处理能力,而DMA方式仅局限于传送数据块的I/O操作。
${\textstyle\unicode{x2465}}$ 从数据传送来看,中断方式靠程序传送,DMA方式靠硬件传送。
本章小结
I/O设备有哪些编址方式?各有何特点?
$\color{green}{\text{统一编址}}$ 和 $\color{green}{\text{独立编址}}$ 。统一编址是在主存地址中划出一定的范围作为I/O地址,以便通过访存指令即可实现对I/O 的访问,但主存的容量相应减少。独立编址是指I/O 地址和主存是分开的,I/O地址不占主存空间,但访存需专门的I/O指令。
CPU响应中断应具备哪些条件?
在CPU内部设置的中断屏蔽触发器必须是开放的。
${\textstyle\unicode{x2460}}$ 外设有中断请求时,中断请求触发器必须处于“1”状态,保持中断请求信号。
${\textstyle\unicode{x2461}}$ 外设(接口)中断允许触发器必须为“1”,这样才能把外设中断请求送至CPU.
${\textstyle\unicode{x2462}}$ 具备上述三个条件时,CPU在现行指令结束的最后一个状态周期响应中断。
常见问题和易混淆知识点
中断响应优先级和中断处理优先级分别指什么?
中断响应优先级是由硬件排队线路或中断查询程序的查询顺序决定的,不可动态改变;而中断处理优先级可以由中断屏蔽字来改变,反映的是正在处理的中断是否比新发生的中断的处理优先级低(屏蔽位为“0”,对新中断开放),若是,则中止正在处理的中断,转到新中断去处理,处理完后再回到刚才被中止的中断继续处理。
向量中断、中断向量、向量地址三个概念是什么关系?
中断向量:每个中断源都有对应的处理程序,这个处理程序称为 $\color{green}{\text{中断服务程序}}$ ,其入口地址称为 $\color{green}{\text{中断向量}}$ 。所有中断的中断服务程序入口地址构成一个表,称为 $\color{green}{\text{中断向量表}}$ ;也有的机器把中断服务程序入口的跳转指令构成一张表,称为中断向量跳转表。
$\color{green}{\text{向量地址}}$ :中断向量表或中断向量跳转表中每个表项所在的内存地址或表项的索引值,称为向量地址或中断类型号。
$\color{green}{\text{向量中断}}$ :指一种识别中断源的技术或方式。识别中断源的目的是找到中断源对应的中断服务程序的入口地址的地址,即获得向量地址。
程序中断和调用子程序有何区别?
两者的根本区别主要表现在服务时间和服务对象上不一样。
1)调用子程序过程发生的时间是已知的和固定的,即在主程序中的调用指令(CALL)执行时发生主程序调用子程序过程,调用指令所在位置是已知的和固定的。而中断过程发生的时间一般是随机的,CPU在执行某个主程序时收到中断源提出的中断申请,就发生中断过程,而中断申请一般由硬件电路产生,申请提出时间是随机的。也可以说,调用子程序是程序设计者事先 $\color{green}{\text{安排}}$ 的,而执行中断服务程序是由系统工作环境 $\color{green}{\text{随机}}$ 决定的。
2)子程序完全为主程序服务,两者属于 $\color{green}{\text{主从关系}}$ 。主程序需要子程序时就去调用子程序,并把调用结果带回主程序继续执行。而中断服务程序与主程序二者一般是无关的,不存在谁为谁服务的问题,两者是 $\color{green}{\text{平行关系}}$ 。
3)主程序调用子程序的过程完全属于 $\color{green}{\text{软件}}$ 处理过程,不需要专门的硬件电路;而中断处理系统是一个 $\color{green}{\text{软/硬件}}$ 结合的系统,需要专门的硬件电路才能完成中断处理的过程。
4)子程序嵌套可实现 $\color{green}{\text{若干级}}$ ,嵌套的最多级数受计算机内存开辟的堆栈大小限制;而中断嵌套级数主要由中断优先级来决定,一般优先级数不会很大。