XML技术
XML概述
可扩展标记语言(XML)是标准通用标记语言(Standard Generalized Markup Language, SGML)的一个子集:XML包含了很多SGML特性,但是比SGML要简单得多。像SGML一样,可以用XML来开发一种标记语言,它的元素和属性多是为专门行业和产业而定义的。创建这种语言之后,就可以使用XML——就像使用HTML(Hypertext Markup Language)一样——来标记并结构化文档了。
XML和HTML都支持统一字符编码协会(Unicode Consortium)制定的通用字符集(Universal Character Set, UCS),它不仅包括特殊字符、标点和数学符号,还包括了非英语语言的字符和字母表,这使得XML成为了国际标准,这些字符和符号被认为是实体。XML和HTML都支持样式表(style sheet)的使用,样式表有助于你定义整篇复杂的文档的结构和外观。然而,HTML在许多方面都传统地定义了它的输出样式(当然最新版的HTML和由它继承而来的XHTML极力鼓励你使用层叠样式表来编制文档的样式)。而且,XML在支持文档样式符号、规范语言(The Document Style Semantics and Specification Language, DSSSL)和层叠样式表(Cascading Style Sheets, CSS)等性能方面大大超过了HTML。
专为XML“服务”的样式表标准是可扩展样式表语言(Extensible Stylesheet Language, XSL),它是基于在线文档样式符号和规范语言(DSSSL-O)的,DSSSL-O是DSSSL的一个子集,像CSS一样是专门为电子文档而创建的。有关CSS的更多信息,请参考同样由Sandra E.Eddy著IDG Book Worldwide公司出版的《XHTML参考教程》,XSL在本书第2部分的“XSL样式表语法”和第7章的“使用XSL设计文档”中分别都有介绍。XSL现在还只是一个建议,要跟上它的发展,请浏览其最新的建议:http://www.w3.org/TR/xsl/。XSL转换(XSL Transformations, XSLT)是一种新的语言,它可以和XML协同工作。请参阅“XSLT组件”中的有关XSLT的内容。
XML包括如下特点和功能:
(1)XML允许各种各样的文档显示类型,不仅可以显示在许多计算机平台上,而且可以显示蜂窝电话、掌上电脑等其他设备上。程序员可以使用任何编程语言或脚本语言来定义文档。
(2)XML支持但并不需要DTD (Document Type Definition,文档类型定义)。如果你使用DTD,就要通知XML编辑器严格地按照DTD中设定的规则来处理文档。
(3)XML的支持标准(XLink和XPointer)支持比HTML更为复杂的链接。在HTML和XML中你只能链接到一个URL。然而在XML支持标准中可以同时使用几个或者一组链接。
(4)XML标准支持打印文档和电子文档以及其他的为不同用户定义了不同内容和外观的文档。
(5)XML支持客户端或者服务端计算机上的进程,这就允许开发人员分配资源和随时地节省资源。当前,XML 1.0规范已经定义了,而XLink和XPointer语言仍处在开发和候选建议状态,这意味着它们已经被各技术团体评论过了。在成为最后建议之前,两种语言都可能发生改变。
XML基本语法
本节将比较简略地介绍XML的基本语法,通过一个基本文档的例子来了解它的实质内容。希望这部分内容对于初次接触XML技术或者Web服务技术的读者,能有一个简要的知识铺垫。
以下是XML 1.0规范(第2版)的规范文本和该版本的中译本的URL。
● http://www.w3.org/TR/2000/REC-xml-20001006
● http://lightning.prohosting.com/-ggiu/REC-xml-20001006-cn.html
标签语法
XML标签负责提供、描述一个XML文件或数据包(也就是大家所熟知的XML实体)的内容结构。它们由界定内容的不同部分的标签(tag)所组成,负责提供到特殊符号和文本宏的引用,或者将特殊指令传递给应用软件,以及把注释传递给文档编辑器。
XML元素的结构与HTML基本相同,XML也同样使用尖括号来界定标签:以小于号(〈)结尾,但二者的相同点也就仅此而已。
与HTML不同,几乎所有的XML标签都是大小写敏感的,其中包括元素的标签名和属性值,主要是满足XML国际化的设计目标和简化处理过程的需要。大多数非英语的语言并不把字母表分成若干种写法,许多字母可能也没有对应的大写或小写。合并写法会存在许多缺陷,尤其对于非ASCII码更是如此,而XML的设计者们大多选择避免这些问题。
字符
由于XML要在全球范围内使用,所以不能局限于7位的ASCII码字符集。XML指定的字符均在16位的Unicode2.1字符集(参见http://www.unicode.org,它目前与ISO/IEC 10646一致,后者可参见http://www.iso.ch)中定义。这些都是相对较新的标准,而且当今世界还有许多文字没有编入统一码中。但是,由于它被设计为大多数现存字符编码的超集,所以遗留的内容向统一码的转换也是简单直观的,例如,把ASCII码转换成统一码只需要把16位字符的前8位填充为0(而保留后8位)即可。
命名
在XML中使用的结构几乎总是被命名的。所有XML命名都必须以字母、下划线(_)或冒号(:)开头,后面跟着的是有效命名字符。有效命名字符除了前面的这些字符外,还包括数字、连字符(-)、句号(.)。在实际应用中不应该使用冒号,除非是用作命名空间修饰的分隔符(可参见本章后面的关于命名空间的相关描述)。字母并非局限于ASCII码,这一点是非常重要的,因为不说英语的人们可以把自己的语言用在标签中。
下面就是一些合法的命名:
Web、WEB、WebService: Interface、中国软件
注意前两个命名并不等同,因为XML的命名是大小写敏感的,第三个是使用建议的命名空间分隔符(冒号)的典型例子,最后一个例子提醒大家注意汉语同英语一样,都可以用于XML的命名。
下面是一些非法的命名:
-Web、4Web、Web$Service
文档部分
一个格式正规的XML文档由以下三个部分组成。
(1)一个可选的序言(prolog)。
(2)文档的主体(body),由一个或多个元素组成,其形式为层次树状结构,其中可能也包含了一些字符数据(character data)。
(3)可选的“繁杂”的尾声(epilog),其内容包括注释、处理指令(Processing Instruction, PI)和/或紧跟在元素树后面的空白。
元素
元素是XML标签的基本组成部分,它们可以包含其他的元素、字符数据、字符引用、实体引用、PI、注释和(或)CDATA(即Charactor Data缩写)部分——这些合在一起被称为元素内容(element content)(要注意这些元素都是容器)。所有的XML数据(除了注释、PI和空白)都必须包容在其他元素中。
元素使用标签(tag)进行分隔:由一对尖括号(〈 〉)围住元素类型名(一个字符串)。每一个元素都必须由一个起始标签和一个结束标签分隔开,这与要求比较松的HTML不同,后者的结束标签可以省略。这项规则唯一的例外是没有任何内容的元素,即空元素(Empty Element),它既可以使用起始标签/结束标签对,也可以使用短小精悍的混合形式——空元素标签。在后面,我们会看到许多标签的例子。
起始标签
一个元素开始的分隔符被称为起始标签。起始标签是一个包含在尖括号里的元素类型名。我们也可以把起始标签看作是“打开”了一个元素,就像我们打开一个文件或通信链路一样。
下面就是一些合法的命名:
〈Web〉、〈WEB〉、〈WebService: Interface〉、〈中国软件〉
结束标签
一个元素最后的分隔符被称为结束标签。结束标签由一个反斜杠和元素类型名组成,被围在一对尖括号中。每一个结束标签都必须与一个起始标签相匹配,我们可以把结束标签理解为“关闭”了一个由起始标签打开的元素。
下面是一些合法的结束标签,它们与前面列举的起始标签相对应。
〈/Web〉、〈/WEB〉、〈/WebService: Interface〉、〈/中国软件〉
所以,带有完整的起始、结束标签的元素应该是如下形式:
〈某个标签〉包含的内容〈/某个标签〉
空元素标签
空元素可能不包含任何内容。比如说想准确地指明文档中的某些特定位置,我们可以只加入起始标签和结束标签,而不在其中包含任何内容。
〈WebService〉〈/WebService〉
当然,如果你只是想指定一个点,而不是提供一个包容器,节省些空间可能会更好。所以,XML指定空元素可以用缩略形式表示,它是起始和结束标签的混合体。它短小精悍,而且还能明确指出该元素既不会有内容,也不允许有内容。
空元素标签由一个元素类型名称紧跟一个反斜杠组成,并围在一对尖括号中。
〈WebService/〉
一个XML数据对象可能只包含单个文档根元素和一些空元素(可能有属性),这样的文件可以用来描述应用程序的配置信息或者面向对象编程语言中的对象模板。
文档元素
格式正规的XML文档的定义形式是一个简单的层次树,每个文档都有一个,而且只有一个根节点,它被称为文档实体(document entity)或文档根(document root)。这个节点可能包含PI和(或)注释,而且总是包含子元素树,它们的根被称为文档元素(document element)。这个元素是这个树中其他所有元素的父元素,而且它可能不包含在其他任何元素当中。每个XML文档的文档根也是使用DTD (Document Type Definition,文档类型定义)或模式定义的文档描述的附属品(由于本章并不想就DTD展开详细讨论,文章对于XML建模的重点是XML Schema,因此只对XMLSchema进行讨论)。
任何格式正规的XML文档都必须由形成一个简单的层次树的元素所组成,其中有一个被称为“文档根”的单个根节点。它包含第二层的元素树,这个树也存在一个被称为“文档元素”的根节点。
元素嵌套
XML对元素有一种非常重要的要求:它们必须正确地嵌套。对现实世界对象的分析会有助于解释“正确嵌套”的含义。实际上,我们甚至可以说XML元素是任何必须遵守它们的现实来源规则的单词。
让我们来看一看本书传递到读者手中的整个过程。在完成印刷后,本书会和其他23本书打包到一个盒子中。两个盒子会被封装到一个纸箱中,许多纸箱会被装入一辆卡车然后运送到书店中。
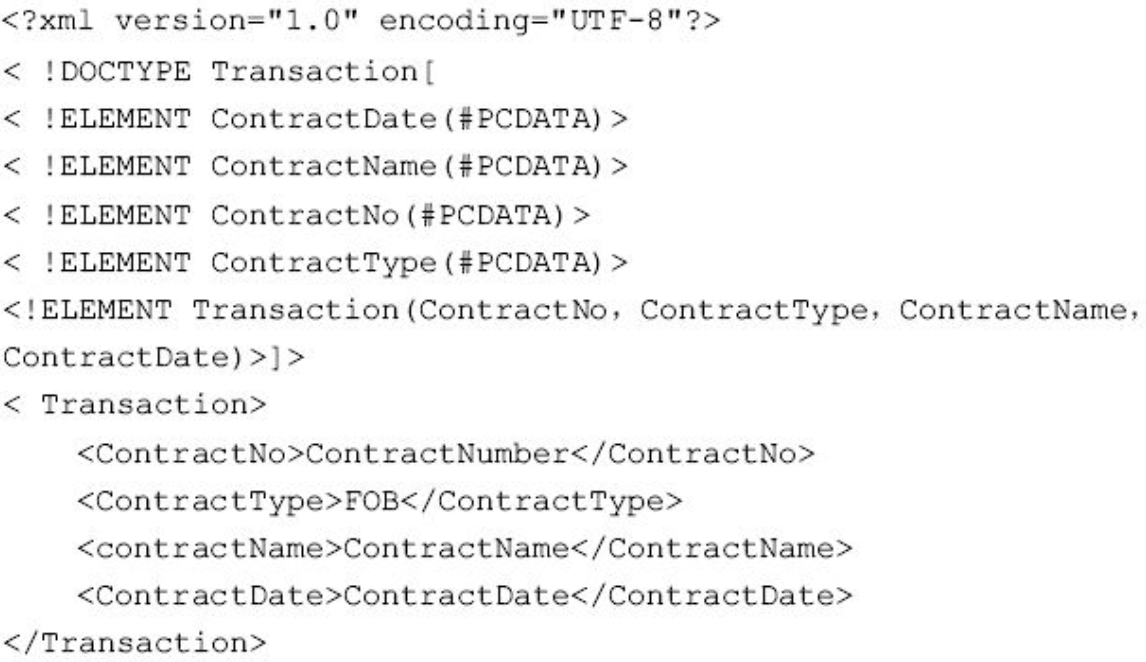
整个过程可以用以下XML元素表示。
图片详情

在上面的例子中,缩排只是为了突出这些嵌套元素的层次结构,为了简单起见也省略了许多对书和纸箱的描述。现实世界中的盒子能够包容整本书,但不可能出现书的某些部分在盒子中,而其他部分在外面的情况;同样,一本书也只能放在一个盒子中,不可能一部分在一个盒子,其他部分在另一个盒子。此外,盒子必须放在纸箱中,而纸箱必须顺序摆放在卡车里。当然,XML元素也必须遵守这些现实世界包容关系的基本法则。
字符串
字符串(string literal)主要用在属性值、内部实体和外部标识符中。XML都使用单引号(’)或双引号(””)作为一对分隔符将其中的字符串包围起来。对于这些字符串的一个限制是用于分隔符的字符不能够出现在字符串中,如果字符串中包含单引号,分隔符就必须使用双引号,反之亦然。如果两个字符都必须出现在字符串中,用在字符串中(同时也用作分隔符)的字符必须用适当的实体引用顶替('或者”)。
下面是一些合法的字符串表述:
‘string’, “string”. ‘this's a “Web Service”‘
而下面则是一些不合法的字符串表述:
“string’. ‘this’s a “Web Service”‘
从技术的角度讲,根据XML规范,字符串分隔符之间的文本是文档字符数据的一部分。在讨论属性之前,我们先看一看它所包含的意义。
字符数据
字符数据就是任何不是标记的文本,它是元素或属性值的文本内容。小于号、大于号和&符号是标记分隔符,因此它们绝不能以字符串的形式出现在字符数据中(CDATA部分除外,这一点我们将在后面提到)。如果这些字符是字符数据所必需的,它们必须使用实体引用“&It;”、“>”以及“&”来代替。这几个替代物是XML规范定义的5个类似字符串中的一部分,而且在所有兼容XML的解析器中都得到实现。
这里,需要再次提醒大家,由于XML的目的是在全球范围使用,所以文本是指统一代码,而不仅仅是ASCII码。现在,我们就来讨论属性的问题。
属性
如果说元素是XML中的名词,那么属性就是这种语言的形容词。在很多情况下,我们会希望将某些信息附着在元素上,它们与元素本身包含的信息内容有所不同。我们利用属性(attribute)来做到这一点,它们都包括一个名称/值对组合,使用的格式有如下两种形式:
图片详情
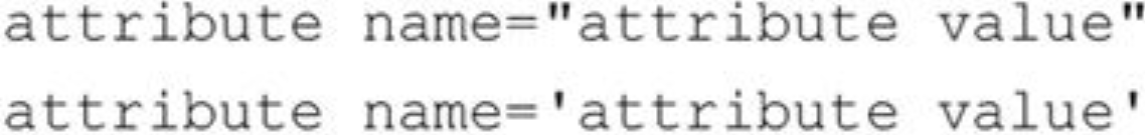
属性值必须是分隔开的字符串(字符串规则的要求),其中可能包含实体引用、字符引用以及(/或)文本字符。但是,正如我们刚才解释的那样,任何一个受保护的标记字符(“〉”、“〈”和“&”)都不能简单地在属性值中当作字符使用,它们必须用“&It; ”、“>”或“&”实体引用来替代。
HTML允许数字化的属性,例如〈IMGWIDTH=300〉;或者不分隔的属性,比如〈PALIGN=LEFT〉;但这两种情况在XML中都不允许存在。
在起始标记或空标记中属性只允许有一个实例存在。例如,下面的例子在XML中就是非法的,因为src在一个标记中出现了两次:
图片详情
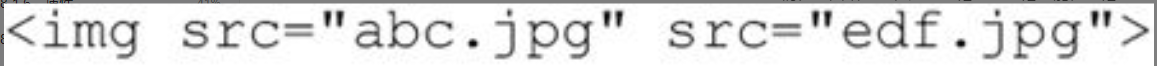
这种限制极大地简化了XML的处理。正如我们在前面暗示的,起始标记和空标记可能在标记中包含属性。例如,回到我们前面提到的关于书本、盒子、纸箱和卡车的例子,如果我们希望给每个运送书本的纸箱编上一个号码的话,可以使用如下属性:
图片详情

在这个例子中,属性名称是number,相应元素起始标签中的值为”0-232-93-1’”及’0-232-93-2’。注意两个合法的字符串分隔符”和’在本例中都被使用了。
空白
管是对于人类语言还是计算机语言来说,空白确实是一个非常重要的语言概念。在XML数据中,只有4个字符可以作为空白使用,如表8-1所示。
表8-1 4个字符的描述

无论如何,制表位占用的位置都不会只超过一个字符,所以它们中的每一个都可以简单地看作是一个字符。同样,任何由LF和(/或)CR隐含的格式也是交给应用程序和(/或)样式表处理;同时,Unicode定义了许多不同种类的空格,但其中没有一个能够成为XML中的空白。XML处理空白的规则非常简单:解析器会保留内容中所有的空白字符并不加修改地传递给应用程序,但元素标记和属性值中的空白会被删除。
现在,让我们看一看XML是如何处理文档中的行尾的。
行尾的处理
XML数据对象经常存储在离散的计算机文件中,它们被分割为若干个文本“行”。在4个XML空白字符中有两个是标准的ASCII码行尾控制字符。正如我们前面提到的,在用来表示行尾时,会有这两个字符的三种常见组合:CR/LF、只有LF以及只有CR。
为了简化XML应用程序的编码,XML解析器需要将所有的行尾字符串转换为单个LF(换行)字符。很自然,这会让Unix编程者感到非常高兴,而让许多MS-Windows的开发人员怨声载道(Mac OS用户已经适应了处理多种行尾字符串)。Tim Bray曾经提出过一些折衷办法(主要是考虑到MS-Windows的市场份额),但结果是XML仍然要求使用Unix风格的行尾字符。
注释
这种机制对于在文档当中插入提示,或者叫注释(comment)来说是相当有帮助的。这些注释可能提供修订记录、历史信息或者其他类型的可能,这对创建者或者文档编辑者来说有着特殊意义,但又不是真正的文档内容的元数据。注释可能出现在文档中除其他标记部分以外的任何地方。
XML注释的基本语法如下。
图片详情
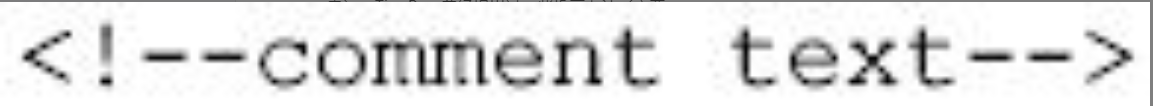
CDATA部分
CDATA部分是一种用来包含文本的方法,其对象是那些其中的字符如果不如此处理就会被识别为标记的文本。这项特性对于希望在自己的文档中包含XML标记的使用举例的作者来说是最有用的,就像本书中的举例。但这可能是在文档中包含CDATA部分的唯一说得过去的理由,因为在使用这些部分时XML几乎所有的优势都丧失殆尽。
只要有字符数据出现的地方就可能出现CDATA部分,但它们不能够嵌套。CDATA部分的基本语法如下:
图片详情

在这里,”…。.”部分可以是任何字符串,只要不包含字符串”]]〉”。
由于在Web服务系列技术中,CDATA同样不是常用技术,因此在这里也不加以详细讨论。
格式正规的文档
所有遵守XML语法规范的数据对象(文档)都是格式正规的XML文档。这类文档在使用时可以不使用DTD或模式来描述它们的结构,它们也被称作独立的(standalone)XML文档。这些文档不能够依靠外部的声明,属性值只能是没有经过特殊处理的值或默认值。
一个格式正规(well-formed)的XML文档包含一个或多个元素(用起始和结束标记分隔开),它们相互之间正确地嵌套。其中有一个元素,即文档元素,包含了文档中其他所有的元素。所有的元素构成一个简单的层次树,所以元素和元素之间唯一的直接关系就是父子关系。兄弟关系经常能够通过XML应用程序内部的数据结构推断出来,但这些既不直接,也不可靠(因为元素可能被插入到某个元素和它的一个或多个子元素之间)。文档内容可能包括标签和(/或)字符数据。
数据对象如果满足下列条件就是格式正规的文档。
(1)语法合乎XML规范。
(2)元素构成一个层次树,只有一个根节点。
(3)没有对外部实体的引用,除非提供了DTD。
任何XML解析器如果发现在XML数据中存在并不是格式正规的结构,就必须向应用程序报告一个“致命”错误。致命错误不一定导致解析器终止操作,它可以继续处理,试图找出其他错误,但它不再会以正常的方式向应用程序传递字符数据和(或)XML结构。之所以采用这类错误处理方式,一是因为XML简洁的设计风格,二是因为XML更多的不是用于显示,因为这不太容易使得XML数据对象做到格式正规。
对于HTML/SGML来说,它们的工具都要比XML宽容许多。HTML浏览器通常会显示出大多数支离破碎的Web页面,这为HTML的快速流行做出了巨大贡献。此外,真正的显示会因浏览器而异。同样,SGML(Standard Generalized Markup Language)工具即使遇到错误,通常也会尽力继续处理文档。
格式正规的文档的存在使得可以使用XML数据而不必承担构建和引用外部描述的重任。术语“格式正规”与正式的数学逻辑有着相似之处,一个命题如果满足语法规则就是格式正规,而不在于它的正确与否。
XML命名空间
我们知道,XML是一种元语言,我们可以使用XML来定义各种各样的应用。在上一节中,我们就已经看到了如此多的基于XML的规范,它们都是使用XML定义的XML Application(XML应用语言)。一般来说,我们可以使用DTD或者XML Schema来规范化定义每种特别的XML。本书将不再介绍DTD,如果有兴趣的话,可以阅读XML规范或者相关材料去了解其细节;对于XML Schema,本书将在下一节结合实例进行描述。
无论是使用DTD还是XML Schema,都是去定义一个专用XML词汇集以及使用这些词汇的规则,这样我们就不可避免地面对这样一些问题:
(1)如何知道我们在一个XML实例文档使用的XML词汇是在哪个XML Application中定义的?
(2)当我们混合使用两个XML Application的词汇集时,如果两个词汇集中有相同名字的元素名(当然它们表示的是不同的含义),如何区分它们?
同样,这些问题也会发生在我们自己来定义XML标签的场合中。比如说,如果你考虑使用monitor这样的元素,那么它在不同的环境将有几种不同的意思。如果你在计算机外围设备描述中使用,monitor可能指的是计算机屏幕,同时在音乐制作间里扬声器通常也叫做monitor。如果这里有一个专用于描述学校信息的数据模式,monitor可能指的是一个被赋予几种职责的学生,然而在原子核电站,monitor可能放在报警的地方。即便意思相同,在两种不同的定义中,其内容也会发生改变。
面对元素的这些潜在的不同用途,我们需要一种方法去区分元素的特定用途,特别是我们在同一个XML文档里混用不同的词汇。为了解决这个问题,W3C提出了称为XML命名空间的规范,它允许我们在一个命名空间定义元素的前后联系,同时可以使用不同的命名空间来区分不同的XML词汇集中的元素名。
1999年1月14日,XML命名空间成为了W3C的推荐标准的程度。这一节将主要介绍XML命名空间。命名空间帮助XML词汇表设计者去将复杂的问题分解成细小的问题,以及根据需要混合多义词来描述单一XML文档里的问题。模式允许词汇表设计者去建立更多而准确的词汇定义。
命名空间
XML命名空间是解决多义性和名字冲突问题的方案。根据W3C组织的推荐标准XML Namespace (1999年1月14日)中的描述,XML命名空间是一种名称的集合,通过一种URI (Uniform Resource Identifier)引用来标识,作为元素类型和属性名称,它应用于XML文档。
命名空间是一组具有结构的名称的集合,这听起来像一个DTD,的确,一个DTD可以是一种命名空间(因为一个DTD定义了一个XML词汇集)。在这种情况下,URI可以是在你的服务器上的地址,如http://www.uddi-china.org/schema/PubCatalog.dtd。
DTD规定了一个文档的整体结构(并且是那么的准确),我们正好以一个命名空间为资源,规划所需要的定义。说到这里,一个命名空间不需要是一个像DTD那样的有固定结构的定义,而这个有限的定义领域使命名空间广泛应用于XML。如果命名空间是DTD或者XML Schema,我们使用的定义就必须在所描述的结构和语法上保持连续性。但是我们可以自由地使用需要的名称,并且使用命名空间来区分元素的使用。
于是,为了在文档里有效地使用命名空间,而文档中连接着来自不同地方的元素,我们需要两部分:
(1)URI引用,定义了元素的使用方法。
(2)一个别名,我们可以用此来标识元素来自哪个命名空间,这将采用元素前缀的形式(例如在〈中,catalog是模糊的contact元素的命名空间别名)。
定义和声明命名空间
看到了命名空间在XML里所带来的优点,我们需要仔细看一下如何真正地使用它们。首先看一下在文档里怎样声明一个命名空间,然后看一下在文档里怎样使用命名空间,最后给出了几个例子。
通常,简单描述的特性作为属性来建模,并且这就说明了命名空间是怎样在XML中声明的。但这里有几个变形与转化,于是我们需要一步一步地去学习当在一个XML文档里声明一个命名空间时所能描述的东西。
声明一个命名空间
如果每个人在他们打算去识别一个命名空间声明的时候,我们需要在XML表示中提供一个保留的词汇给他们,命名空间推荐标准为我们提供了xmlns属性。属性值就是URI,其唯一地定义了当前使用的命名空间。URI经常是一个指向模式定义描述的URL(可能是DTD,也可能是XML Schema文档,甚至是其他)。用这种方式管理一个URI,以唯一区分命名空间已经足够了。
这里有几个简单的命名空间声明:
图片详情

关于Web资源的术语可能令人混淆。统一资源标识符(URI)是一些资源的唯一名称,它根据协议和网络位置定位资源。第一个例子是URL,因为它允许一个浏览器利用HTTP(Hypertext Transfer Protocolv)从一个特定的位置得到资源。第二个例子给资源命名但没提供位置,字面上的urn来自于URI。
最初使用命名空间的动机之一是能够从不同的来源混合名称。基于这个考虑,为命名空间提供别名就成为非常有用的机制。而你能在一个涉及到相关声明的文档里通篇使用这个别名,可以靠加个冒号和你的别名到xmlns属性而实现该功能。因此上面的例子就变成了:
图片详情

通过这样的命名空间声明之后,文档中的元素如果使用了uddi前缀(形如uddi:businessEntity),那么表示这个元素使用了http://www.uddi-china.org/schema/uddiv2.xsd 中描述的定义。而如果使用了catalog这个前缀(元素形如),那么则表明使用了urn:catalog-specification所标识的定义。使用这些声明和它们的别名为我们提供了更多的元素信息。当然如果没有前缀那就等同于使用了xmlns=”…”的命名空间约束。’
修饰名
如果不能和一个我们想要使用的特定的名称绑定在一起,声明一个命名空间是没有什么用处的。这些已经通过利用修饰名(或成为命名空间修饰名,也就是使用命名空间前缀进行修饰的元素名或属性名)做到了。这就可能是你所希望的,一个从命名空间勾画出来并经其限定了的名称。通过别名创建一个确认过的名称,确切地说称作命名空间前缀,并把它放在名称的开始。下面是一个命名空间的例子:
图片详情
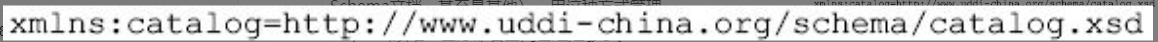
此后我们就能够使用前缀catalog来进一步修饰每个元素名,使元素更加明确地表示出是来自哪个命名空间。于是,将要告诉我们contact名来自catalog命名空间声明;同样可能来自其他的命名空间,比如某个Order命名空间也有contact名称,但经过修饰的名称避免了多义性和冲突的可能性。
命名空间前缀经常被提及为前缀,而名称本身是基本名。修饰名可被应用于元素和属性名称。这里有一个混合一些命名空间的例子:
图片详情

这个元素从我们在上面看到的第一个命名空间那里产生,而属性id则从identifier命名空间产生。
作用范围
命名空间声明就像变量在程序语言里那样有它的作用范围。这非常重要,这是因为命名空间并不总是定义在XML文档开始,它们能够被包含在文档的较后部分。一个命名空间声明因此也应用于有声明出现的元素,尽管与此同时子元素并没有清清楚楚地描述出来。只要被用在命名空间声明的范围之内,就能够访问到命名空间。
但是我们也需要去混合命名空间,元素可能会回去另外地继承命名空间的作用域,于是这里有两种可以声明作用域的办法,即默认和修饰。
默认
如你所想象的,在一个文档里,在每一个名称前加一个前缀非常令人厌烦。实际上,通过在工具集里引入名称作用域的概念,能够分配很多前缀。如果定义了默认的命名空间(没有声明别名的,形式为xmlns=”…”),在声明作用域里所有没有经命名空间前缀修饰的名称被假定属于默认的命名空间。于是如果在根元素声明了一个默认的命名空间,它将被看作整个文档将默认的命名空间,并只能被在文档内部声明的其他的默认命名空间所覆盖。
通常省略前缀可以将一个命名空间声明为某范围内默认的。当一个前缀被定义并被一个名称引用时,明确地声明了命名空间。而对于那个带有命名空间声明但又不包含命名空间前缀修饰(使用默认命名空间)的元素,它们同样是属于其自身所带的命名空间声明所指定的命名空间的。
修饰
如果你能够清楚地区分命名空间,那当然非常好。但有些时候可能想要在一篇文档里从某个元素之外的命名空间来修饰名称,你就需要一个更精细的划分尺度。除了在整个空间声明命名空间,还可以利用带命名空间修饰的名称。在文档开头声明将需要的命名空间,然后在使用地点使用命名空间来修饰那些需要的元素和属性。
命名空间的存在主要是用来将名称组织成特有的集合以及回避名称冲突。W3C命名空间推荐标准没有描述任何有关验证的使用方法。确实,XML 1.0规范中没有说任何有关命名空间的东西。XML Schema则将充分利用命名空间的功能。我们将在后面的章节中结合实例来阐述XML Schema的使用方法。
DTD
一个XML文档是有效的,则它必须满足:文档和一个文档类型定义或者模式相关联,这样XML处理器才能够理解并解析。那么怎样定义并利用这样一个文档类型定义呢?本节会具体讲述文档类型定义(DTD)。
什么是DTD
DTD即文档类型定义,是SGML、标准经XML的简化继承而来的,顾名思义,它主要是用来查看XML文档的格式,正如第7章所提到的,有关DTD的声明如果存在,则应出现在XML文档的序言中,以便XML校验器一开始就可以得到DTD所定义的该份XML文档的格式定义。另外,已经介绍过良构的XML文档和有效的XML文档的区别,所以可以知道DTD声明不是必须出现的。
在DTD中主要定义以下几个方面的内容:
(1)元素声明,包括元素的内容和元素的排列组合方式。
(2)实体声明。
(3)属性的种类
为什么引入DTD
首先考虑一下DTD的作用问题。事实上,DTD也好,XML Schema也好,它们都是提供一种验证的手段。验证对于XML来说是一大贡献,正是有了验证才可以确保XML文件确实地遵守了指定的格式,而这个格式可能是一个标准,或是数据交换双方所共同制定的协议,也正是如此,XML在电子商务领域掀起了轩然大波。
DTD的使用实现了文件格式的统一化,促进了行业或系统内部的文件的标准化,同时也提高了文件的重用性。DTD定义了文件的格式,这种统一的格式可能为某一领域的大量文件所共用,减少了文件制作的时间。也正是由于DTD(和XML Schema)的存在才突出了XML文档的数据的结构性。
但是也应该看到,并不是所有的文件都强调结构性。对于本身的结构性很强,或是在实际应用中不强调它的结构性的文档,使用DTD进行验证,增加了操作时间,得不偿失,可以考虑不使用DTD,只建立良构的XMI文档就行了
DTD的声明
内部DTD声明
DTD的声明分为内部DTD声明和外部DTD声明。在本节通过如下例子介绍内部DTD声明。
图片详情

从上面的例子中可以看到内部DTD声明的语法是:
可以看出内部DTD声明是内嵌于相应的XML文档当中的,这种方式虽然简单,但是从引入DTD的原因考虑,很容易想到,这种做法并不利于文档结构的重用。为此XML还提供了另一种DTD声明——外部DTD声明。
外部DTD声明
外部DTD声明的语法规则可以描述为如下形式。
或者
可以看出,外部DTD声明是依照两种方式进行的,分别把它们叫做SYSTEM方式和PUBLIC方式。下面分别说明两种方式的使用方法。
SYSTEM方式的外部DTD声明
与PUBLIC相对,使用SYSTEM模式的DTD一般在未公开、私人或小团体内使用,可以根据有关URL的规定设置该DTD与用它的XML文档之间的路径关系。
● “..”代表到该文档所在目录的上层目录。
● “/”代表子目录。
● 默认情况代表当前目录。
下面是一个XML文档,它使用的是SYSTEM方式的外部DTD声明。
图片详情

这个XML文档引用的DTD文件dtd1.dtd内容如下:
图片详情

关于这个例子,需要说明的是,在处理指令)<?xml version="1.0"encoding="UTF-8"standalone="no"?)>时,属性standalone应该设置为no,因为此时不是单个的XML文件,还需要读取它的DTD文件。
PUBLIC方式的外部DTD声明
在很多情况下,可能与其他合作伙伴共同制定为一个行业或某个工作领域共同遵守的XML文档格式,这时所使用的DTD就不是小团体或个人所属的,而具有公共性质,就如本书下半部分将要介绍的电子商务领域的XML标准。这时作为一种公用的DTD,它可能存放在某个Web网站上,用PUBLIC方式的外部DTD声明指明这种公用的DTD。
图片详情

关于这个例子,需要说明的是,DTD的URL必须是绝对路径,另外可能注意到了增加了一个参数”TransactionDTD”,这个参数是DTD的名称,如果公用DTD的原作者没有指明它的名称,可以自行定义一个名称。
事实上,XML的验证器在验证XML文档是否符合它所声明的PUBLIC方式的外部DTD声明时,首先将外部DTD从指定的URI.处下载,然后做与SYSTEM方式下同样的验证。
内部DTD和外部DTD同时使用
DTD的使用方式相当的灵活,它不仅提供了内部DTD和外部DTD两种方式,而且还支持内部DTD和外部DTD的同时使用以及和多个外部DTD的同时使用,那么很自然想到一个问题,当两种DTD有一部分声明是重复的,该怎么办呢?事实上,在两种声明存在重复的情况下,处理重复部分的方式和面向对象概念中的重载很类似,把内部声明看作对外部声明中重复部分的再一次说明,重复的部分以内部声明为主。这样就大大提高了外部声明的重用率,使得取用外部DTD的机会增加。
元素的声明
元素是XML文档中相当重要的组成部分,通过介绍在DTD中元素的声明方式进一步了解元素。
元素声明的基本语法可以写作:
其中ELEMENT是XML中预留的关键字。可以看出在元素声明中比较复杂的是元素定义部分。下面分不同的情况介绍元素的定义。
空元素的声明
空元素应该说是最简单的元素,它通过预留关键字EMPTY来实现。下面是一个空元素的声明:
文本元素的声明
这里主要指元素的内容完全是文本形式的元素类型,XML中用(#PCDATA)来描述,意思是可解析数据。下面是一个文本元素的声明:
无限制元素的声明
这里所指的无限制元素是XML为某些结构性比较差的元素提供的说明方法,它对该元素不作限制。这里的不作限制可以理解为:
(1)可以包含任何在该DTD中声明过的子元素。
(2)这些子元素的出现次数与次序不作限制。
(3)可以包含文本数据,即(#PCDATA)型数据。
(4)数据内容与子元素可以交错出现。
XML通过关键字ANY实现对无限制元素的声明。这类无限制元素的声明语法如下:
包含子元素的元素声明
第7章就介绍过了关于根元素、父元素和子元素的概念。事实上,XML文档本身通过元素之间的嵌套关系描述了数据(元素)之间树状结构关系,正因如此DOM等应用程序接口才能十分方便地将XML文档转化为许多应用程序习惯处理的树状结构或其变种。
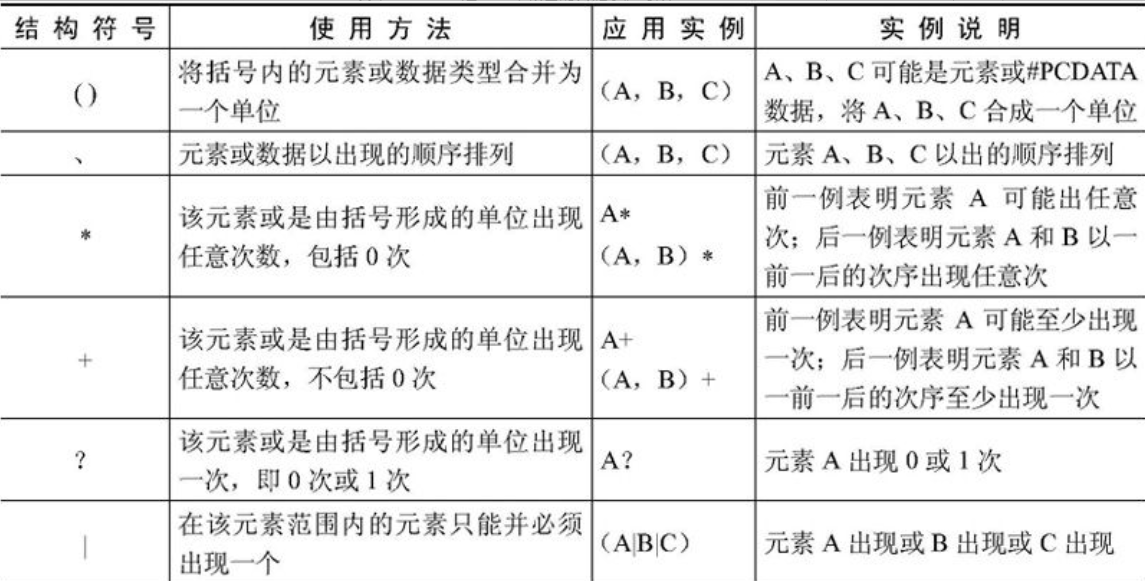
所以,考虑包含子元素的元素声明时,应该注意不只要定义包含的子元素是什么,而且要定义这些子元素出现的次数和次序,在XML中通过一些结构符号描述这些信息,这些符号的描述如表8-2所示。
表8-2 结构符号的具体描述
实体的声明
什么是实体
简单地说,实体(entity)是一些预先定义好的数据,在需要使用这些数据的时候通过引用的方法将它放入特定的位置。使用实体的好处在于对于一些重用率很高的数据,通过将它们定义成实体,减少对这类数据进行修改是必须做的重复工作。另外,通过实体可以把一些特殊的数据,如声音文件、图片文件等引入XML文档。
根据不同的角度可以对实体进行多种不同的分类:按照实体存储的部位的不同,实体可以分为内部实体和外部实体;按照实体的组成内容的不同,实体可以分为可分解实体和不可分解实体两种;按照实体引用方式的不同,可以分为一般型实体和参数型实体。不同类型的实体的声明和使用方法略有不同,下面进行详细的介绍。
内部实体和外部实体
内部实体在声明的时候就被完整地定义,因此应该想到,内部实体只能是文本型的数据。内部实体的声明方法如下:
实体的引用方法是:
&实体名称;
如下例子说明如何声明并引用实体。
图片详情
外部实体的声明虽然在DTD文档中,但是实体代表的数据本身存储于DTD文档之外。外部实体的声明方法如下:
有关属性SYSTEM和PUBLIC的意义和DTD声明中介绍的一样,这里不再重复。外部实体的引用方法和内部实体是一样的。
最后要说明的是特殊字符的使用问题。在XML中,一些字符被赋予了特殊的意义,当不想使用这些字符的特殊意义而引用它们时,就使用实体引用的方式。表8-3是常见特殊字符的实体引用方式。
表8-3 常见特殊字符的实体引用方式

可分解实体和不可分解实体
可分解实体又称为文本实体。所谓可分解是指可以被XML验证器所解读,并且在解读后将实体的内容放入引用该实体的位置上去,例如相对于可分解实体,不可分解实体就是不能直接被XML验证器所解读的实体,例如图片、声音文件等。由于XML校验器本身不能解读这种实体,所以在声明这类实体时应该声明它的格式以及处理该实体的应用程序的位置。下面是不可分解实体的声明方法:
实体的引用方式没有变化。
图片详情

一般型实体和参数型实体
到现在为止,所介绍的实体都是一般型实体。这种类型的实体不仅可以在XML文件本体中引用,而且可以在它所在的DTD中使用。在所在DTD中使用应该注意的是,一般只用于对另外的实体的声明,不用于对元素的声明中,同时应该避免实体中引用实体时产生循环引用的现象。
一般型实体在引用时都采用如下方式:&实体名称;而将要介绍的参数型实体则有很大不同,这类实体只在外部DTD声明中使用,而且不同于一般型实体,它可以用于元素的声明中。它的声明语法如下:
引用语法如下:
%实体名称
可见,参数型实体和一般型实体有着很大的不同。事实上,可以把参数型实体看作在声明外部DTD时为避免重复工作提供的一种方法。如果有机会读到一些用作行业标准的DTD文档,会发现其中存在着大量的参数型实体的引用。
对一般型实体和参数型实体的区别总结如表8-4所示。
表8-4 一般型实体和参数型实体的区别

续表

属性的声明
属性是XML提供的描述元素某些性质的信息,XML本身提供了一些默认属性,如最早在处理语句<?xml version="1.0"encoding="UTF-8"standalone="no"?>就接触到默认属性version、encoding和standalone。当然除了默认属性以外,还可以根据需要自行设计属性,在一个良构XML文档中,属性只要满足命名规则就可以了,但是在一个有效的XML文档中,属性要经过DTD的属性声明,这是DTD声明中比较复杂的一部分。
在DTD声明中,属性的声明语法可以归纳为如下形式。
这里需要说明的是,元素名称指的是属性所属的元素名称,关于属性类型和属性默认值类型是属性中比较复杂的内容,下面详细地进行介绍。
属性类型
属性类型是对属性取值的约束,属性值类型共有7种选择,下面一一介绍。
(1)CDATA类型:CDATA类型是最简单的属性类型,也是约束最少的属性类型,代表该属性值为一般的文字,除此没有其他限制。声明语法如下:
(2)枚举型:枚举型列举了该属性所能取得的全部值。声明语法如下:
(3)NMTOKEN和NMTOKENS类型:使用NMTOKEN属性类型时,表明该属性的属性值只能由字母、数字、“_”等字符所构成的字符串,即属性值满足命名规则,且不能出现空格。NMTOKENS属性则表明属性值可能由若干个满足NMTOKEN属性要求结合在一起形成的,即多个NMTOKEN之间可能存在空格,声明语法如下:
(4)ENTITY和ENTITIES类型:当属性值是一个外部实体的引用时,用ENTITY来说明属性类型;一般来说,当属性值是一个内部实体引用时,将属性类型声明为CDATA即可。
(5)NOTATION类型:在介绍不可分解实体类型时已经提到过NOTATION的声明,当属性只是一个声明过NOTATION格式时,将属性声明为NOTATION类型。由此也可以看出,在把一个属性声明为NOTATION类型时,首先应该确定存在相应的NOTATION声明。下面把NOTATION声明和NOTATION类型属性声明的语法写在一起。
<NOTATION格式SYSTEM I PUBLIC处理程序的URI>
<ATTLIST元素名称属性名称NOTATION属性默认值类型>
(6)ID类型:CDATA类型对于属性的限制是比较少的,ID类型是在CDATA类型的属性类型上加入一点更强的约束条件,那就是作为此类型值的名字只能在XML文件中出现一次。此即,ID类型的值必须能唯一标识元素。
(7)IDREF和IDREFS类型与ID类型相对,IDREF就是ID REFERENCE的意思,表明该属性的取值是对声明过的一个ID型属性值的引用,也就是说,IDREF类型的值必须匹配某些ID属性的值。同样道理,IDREFS类型表明该属性的取值是对声明过的多个ID型属性值的引用。
属性默认值类型
属性默认值类型有4种可选情况,下面一一介绍它们的使用时机和使用方法。
(1)#IMPLIED表明该属性可出现可不出现,声明语法:
(2)#REQUIRED表明该属性一定要出现,声明语法:
(3)#FIXED表明该属性一定要出现,且固定为特定值,不许用其他值,声明语法:
(4)特定属性值表明该属性的默认值,当XML文档中没有显式给出该属性的取值时,取此值。当该属性的取值已经显式地给出时,则为给出值:
<–!ATTLIST元素名称 属性名称 属性默认值>
XML Schema
DTD在制定标记语言方面历史悠久,早在XML正式标准出现以前就已经存在,当时它配合SGML来制定标记语言,是专门为SGML服务的DTD。当XML出现之后,DTD尽管进行了很大的简化,但还是一门风格和XML完全不同的语言,不经过细致学习,根本不可能应用这种语言制定标记语言。而schema文档是一种特殊的XML文档,它遵循XML的语法要求,避免用户再去另外学习一套语法,同时schema语法结构简单,容易学习和使用。因而在发展势头上schema远高于DTD。
DTD的另一个缺点是数据类型相当有限。在DTD中根本不提供数值数据类型,例如整数、浮点数、布尔数等,所有的文档内容都是字符数据。而schema则提供了丰富的数值类型,不但有整数、浮点数等常用的类型,还提供了自定义数据类型的机制。
一个XML文档只能使用一个DTD文档,尽管DTD可以通过多数实体机制来部分改变这种缺点,但还是严重地导致了DTD的继承和使用的有限性。schema则采用了名域空间的机制,使得一个XML文档可以调用多种schema文档。在代码的重用性和可扩展性方面要远远优于DTD。
逻辑XML Schema的文档结构
XML Schema则是一类特殊的XML文档,除了具有XML文档的语法要求外,还要有一些特殊的要求。下面给出了这种文档的一个模板程序1,任何的XML Schema文档只要在该文档的基础上进行继续编写即可。
程序1
文件l.xml
图片详情

所有的内容都添加在<Schema></Schema>当中,该程序可以作为所有schema文档的模板。关于schema的模板在语法方面总结几点:
(1)根标记必须为<Schema></Schema>。
(2)xmlns是一个名域声明,表示Schema文档中使用的标记都是内标识为urn:schemas-microsoft-com:xml-data规范所定义的,前面字符串可以当作是该规范的名字。
(3)xmtns:dt指定了文档中有关数据类型定义的标识都来自下面规范:
图片详情
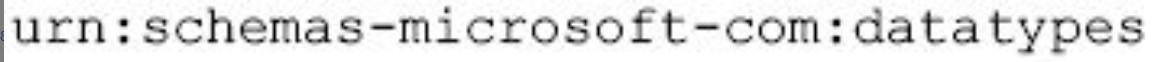
上面的模板是一切schema文档都要遵守的一般性语法要求,下面我们将分别的从各个方面来介绍XML Schema的一些细节知识。
元素的定义
schema中元素的定义使用标记<ElementType>来完成,具体的语法如下面的例子所示。
图片详情
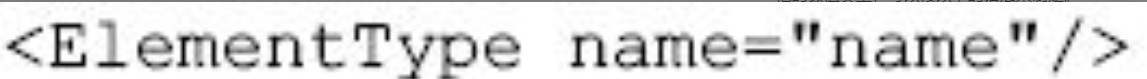
上面一条语句声明了一个<name>标记,该标记内容的类型是一般的文字,如果想指定为其他的数值类型,可以按以下的语法来制定。
图片详情
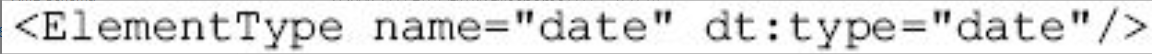
上面语句声明了一个<date>标记,它内容的数据类型是日期型的,其他数据类请参考表8-5。
表8-5 XML Schema所提供的常用数据类型
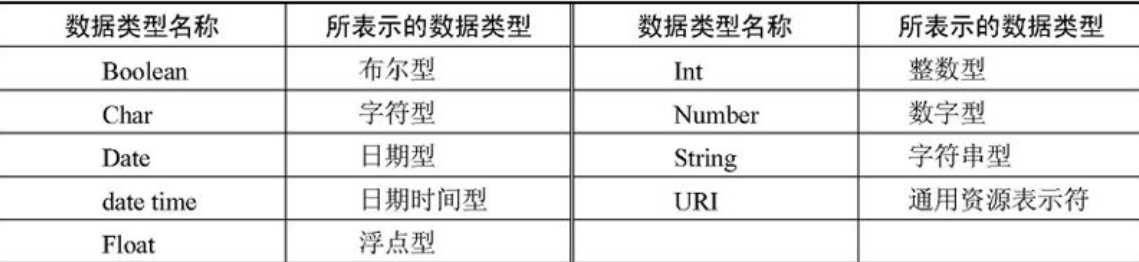
此外还有entity、entities、enumerationn、id、idref、idrefs、nmtoken、nmtokens、notation等数据类型。
如果一个标记中含有子标记,则子标记的定义采用下面的语法:
图片详情

上面程序段定义了一个标记<books>,它有一个子标记。下面我们通过一个完整的程序2来说明标记的定义方法。
程序2
文件2.XML
图片详情

下面是使用该schema的XML文档程序3。
程序3
文件3.xml
图片详情

程序3中有一点需要注意:<books xmlns="x-schema:2.xml">该语句的作用是指定标记<books></books>之间的所有标记都是在文件2中定义的。这也是XML调用一个schema文件的方法。
上面程序的错误在于,标记<book>的内容定义的是整数型,而实际的XML文档中使用的却是一个字符串,因而是一个不合法的文档。只要将<book></book>标记的内容改成整数型的就成为合法的文档,例如下面的程序:
图片详情
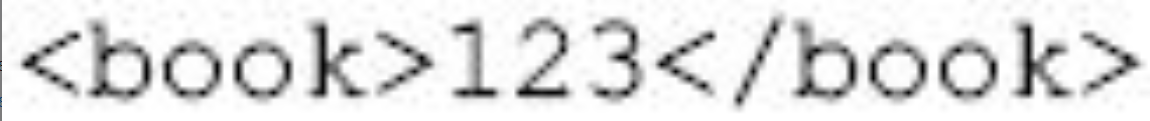
元素内容类型的指定
有的标记只能自己独立使用,有的标记必须包含其他标记作为自己的子标记,决定一个标记语言的该方面的技术是元素的内容类型。这里可以通过关键字content指定这种属性。
Content属性可以有下面的几种取值。
(1)textOnly:表示该标记只包含文本型的内容。
(2)eltOnly:表示该标记只包含元素类型的内容。
(3)empty:表示是一个空元素。
(4)mixed:表示上面的各种情况。
标记的子标记的出现次数
一个标记子标记的出现次数有minOccurs、maxOccurs两个属性来设置,它有如下的几种设置情况。
(1)子标记可以出现不止一次,即可以出现一次或多次,如:
图片详情
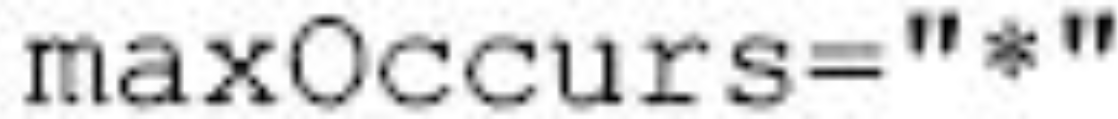
如果一个标记的子标记可以出现一次或多次时,只要指定该标记的maxOccurs的属性值为“*”即可。
(2)只能出现一个,如:
图片详情
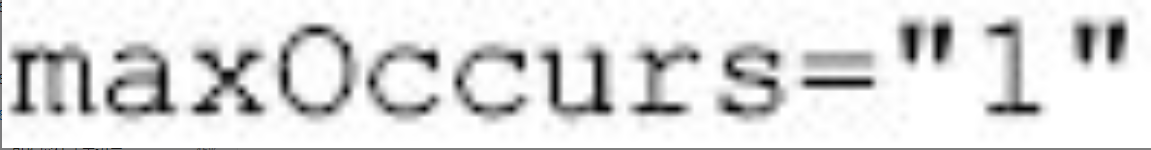
在默认情况之下maxOccurs的属性值为1,除非content的属性设置为mixed,如果content的属性被设置成了mixed,那么maxOccuu默认位为“*”。
(3)子标记可有可无,如:
图片详情
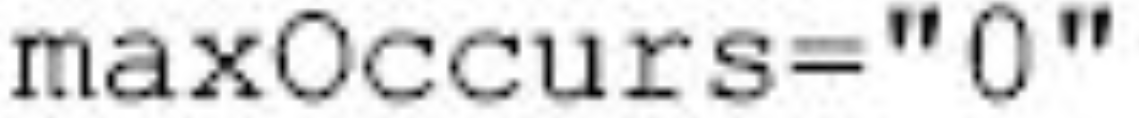
如果一个标记的子标记指定了上面的属性,表示该子标记是可选的。
(4)子标记最少出现的次数,该次数通常是0或1。如果minOccurs的值设置为1就表示该标记必须出现。
图片详情
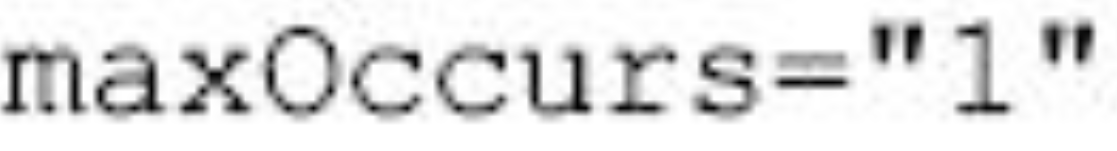
标记的子标记出现的次序
一个标记的子标记出现次序由一个属性order来控制,通常情况下该属性有三种取值。
(1)order=”one”
如果一个标记设置了该属性,则表示此标记的子标记是它子标记列表中的任一个。
(2)order=”many”
如果一个标记设置了该属性,则表示该标记的所有子标记可以按任意的顺序出现任意的次数。
(3)order=”seq”
如果一个标记设置了该属性,则表示该标记的所有子标记必须按照定义好的次序出现。
4.元素的开放性和封闭性
元素的开放性和封闭性指的是元素能否包含定义以外子元素的问题,该方面的功能由属性model来描述,当该属件的值是open时,该元素是开放的,除了可以包含自己定义的子标记外,还可以包含其他的标记。当该属性的值为close时,元素除了包含自己定义时定义的子标记外,不能再包含别的标记。下面通过一个例子程序来演示该属性的应用。
图片详情

可扩展样式表语言
可扩展样式表语言概述
eXtensible Stylesheet Language, XSL)是描述XML文档样式信息的一种语言,是由W3C制定的。
前面已经讲过,XML的一个优点就是形式与内容相分离,这使得XML文档具有简洁、易读的特点。它的样式信息都包含在称为样式单的样式文件中。而XSL就是它的两种样式单的其中之一。另一种是上一节介绍过的已经运用在HTML中的层叠样式单(CSS),是一种静态的样式描述格式,其本身不遵从XML的语法规范。而XSL不同,它本身就是一个XML文档,系统可以使用同一个XML分析器对XML文档及其相关的XSL文档进行分析处理。
XSL是通过XML进行定义的,遵从XML语法规范,是XML的一种具体应用。它由两大部分组成:第一部分描述了如何将一个XML文档进行转换、转换为可浏览或可输出的格式;第二部分则定义了格式对象(Fomatted Object, FO)。在输出时,首先根据XML文档构造源树,然后根据给定的XSL将这个源树转换为可以显示的结果树,这个过程称为树转换,最后再按照FO分析结果树,产生一个可以在屏幕上、纸上、语音设备或其他媒体中输出的结果,这个过程称为格式化。
到目前为止,W3C还未能出台一个得到多方认可的FO,但是描述树转换的这一部分协议却日趋成熟,已从XSL中分离出来,另取名为XSLT(XSL Transformations),其正式推荐标准于1999年11月16日推出,现在一般所说的XSL大多指的是XSLT。与XSLT—同推出的还有其配套标准Xpath(XML Path Language, XML路径语言),这个标准用来描述如何识别、选择、匹配XML文档中的各个构成元件,包括元素、属性和文字内容等。
使用XSL显示XML的基本思想是通过定义模板将XML源文档转换为带样式信息的可浏览文档。最终的可浏览文档可以是HTML格式、带CSS的XML格式及FO格式。
XSL最初是由Microsoft公司提出来的,因此它对XSL的支持也比较好,Microsoft IE 5已经部分支持XSL。
在XML中使用如下语句声明XSL样式单:
图片详情
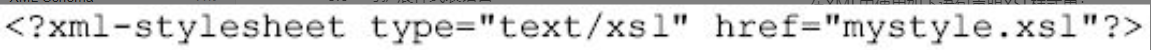
如前所述,XSLT主要的功能就是转换,它将一个没有形式表现的XML内容文档作为一个源树,将其转换为一个有样式信息的结果树。在XSLT文档中定义了与XML文档中各个逻辑成分相匹配的模板,以及模板匹配和转换方式。值得一提的是,尽管制定XSLT规范的初衷只是利用它来进行XML文档与可格式化对象之间的转换,但它的巨大潜力却表现在它可以很好地描述从XML文档向任何一个其他格式的文档作转换的方法,例如转换为另一个逻辑结构的XML文档、HTML文档、XHTML(The Extensible HyperText Markup Language)文档、VRML(Virtual Reality Modeling Language)文档甚至SVG(Scalable Vector Graphics)文档。
XSL在网络中的应用大体分为两种模式。
服务器端转换模式
在这种模式下,XML文件下载到浏览器前先转换成HTML,然后再将HTML文件送往客户端进行浏览。有两种方式:
(1)动态方式。即当服务器接到转换请求时再进行实时转换.这种方式无疑对服务器要求较高。
(2)批量方式。事先用XSL将一批XML文档转换为HTML文件,接到转换请求后直接调用转换好的HTML文件即可。
客户端转换模式
这种方式将XML和XSL文件都传送到客户端,需要浏览时由浏览器实时进行转换,前提是浏览器必须支持XML+XSL的工作方式。
本节将着重介绍XSLT对XML文档的显示转换功能,并将XPath作为XSLT的基础予以介绍。对于FO,在此只用少量的篇幅介绍一下,使读者对其有一个概括性的了解。
XSLT的常用句法和函数
文档结构
前面说过,XSLT文档本身是XML文档,因此文档的第一句自然是:
图片详情
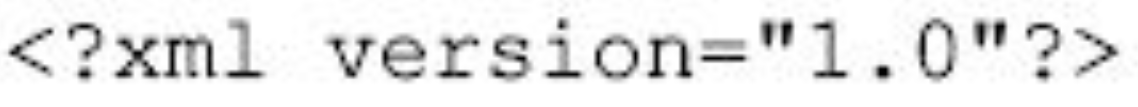
接下来是样式单部分:
图片详情

也可以写作:
图片详情

xsl:transform与xsl:stylesheet具有相同的含义,都表示元素所包含的内容为样式单。xsl:stylesheet元素必须包含有version属性,用以指示该XSL文档遵从哪一个版本的XSL标准。另外,xmlns:xsl指示了XSL的命名空间,在XSLT标准中,定义了XSLT的命名空间为http://www.w3.org/1999/XSL/Transform。
xsl:stylesheet又可包含以下几种元素:
xsl:import xsl:output xsl:attribute-set xsl:include xsl:key
xsl:variable xsl:strip-space xsl:decimal-format xsl:param xsl:preserve-space
xsl:namcspace-alias xsl:template
由此,一个样式单可以写成如下形式:
图片详情

通常把xsl:stylesheet的子元总称为顶级元素(top-level),顶级元素在xsl:stylesheet元素中出现的次序可以是任意的,没有固定的先后次序。每个样式单都包含有零个或多个顶级元素,有关各顶级元素的具体含义我们将在以后的小节中逐步介绍。
XSLT在进行转换时,首先遍历XML源文档树,找到要处理的节点,然后将定义好的模板信息施加到该节点中。
模板与应用
xsl:template是模板元素,通常每个xsl:template有一个节点匹配属性,由“match=”指定。在对模板进行匹配时使用xsl:apply templates,选择要匹配的模板,相当于一个调用的过程。对节点的匹配规则遵照XPath的标准定义。
XSLT对文档树的匹配总是从根节点“/”开始。<xsl:template match="/">就是匹配根节点,然后把定义好的包含HTML文档的开始部分的模板施加给根节点。
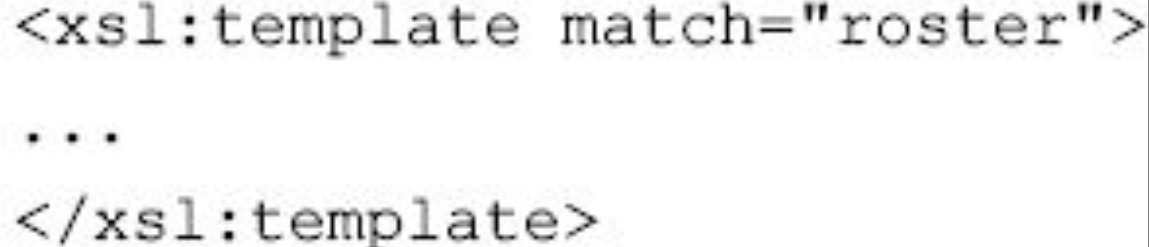
在该例子中,定义了一个roster模板:
图片详情
并在根节点的模板中调用了该模板:
图片详情
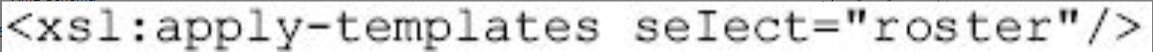
不向的模板的设计,可以导致同一个文档有不同的输出效果的输出样式主要有以下两种方法。
1)定义不同的样式
例如,CAPTION (font-size:l5pt;font-weight:bold:co1or:red)
2)利用mode属性
xsl:template元素还有一个mode属性,利用这个属性可以根据需要去匹配不同模式的模板。
图片详情

那么,如果要将表格标题输出为蓝色字,要用下面语句匹配:
图片详情
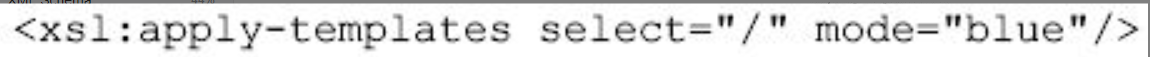
如果要将表格标题输出为红色字,则应写为:
图片详情
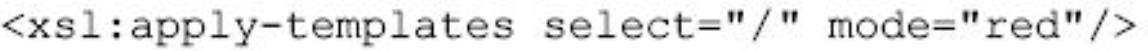
以上介绍了利用模板达到不同输出效果的两种方法,第一种方法采取的是直接修改模板中内容,从而达到得到另外一种输出效果的目的。而第二种方法则是利用了xsl:template元素本身的mode属性,相对于第一种方法而言,具有更强的灵活性。
模板总是与节点相对应的,一个节点可能对应于不同的模板,那么在进行模板匹配时如何确定各模板匹配的先后次序呢?
在XSLT中,允许为xsl:template设置优先级,写法是:
图片详情

n为优先级数。
计算节点值
在使用XSLT进行转换时,常常需要获取节点值,使用xsl:value-of元素可达到这个目的,如:
图片详情
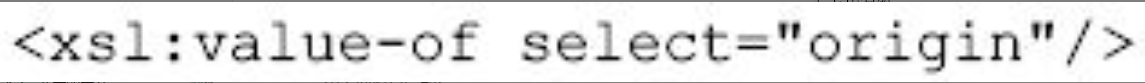
得到的是学生原籍的值,select属性指定要获取的是哪一个节点的节点值。
元素与属性创建
XSLT是一个动态的样式单,在处理过程中可产生新的元素或元素属性。
创建元素
xsl:element元素可在XSLT对文档转换时动态地生成新元素,如下例子中的CAPTION标记就可以用动态生成的方法来生成。
图片详情

XSLT处理此句时,将生成下面的元素:
图片详情
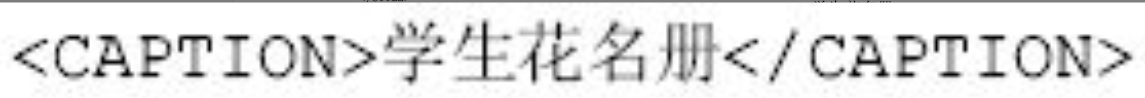
创建属性
xsl:attribute元素可在XSLT对文档转换时动态地生成元素属性,如下面的例中CAPTION标记可以用动态生成的方法加入属性。
图片详情

经XSLT转换后,将生成下面的元素:
图片详情

创建文本
xsl:text元素可实现在样式单转换时动态创建文本,例如:
图片详情

在XSLT进行转换时,匹配到roster节点后,将输出文字:
这是学生花名册
从上面的例子中似乎看不出使用xsl:text的必要性,事实上xsl:text的优势在于它可以保护文本中的空白字符。对于处理特殊类型的文本是很有用处的。
创建处理指令
xsl:processing-instruction元素可以实现在XSLT进行转换时自动生成处理指令,例如:
图片详情

将创建如下处理指令:
图片详情

创建注释
xsl:comment元素可在XSLT结果树中创建一个注释节点,例如:
图片详情

经XSLT转换后生成注释:
图片详情
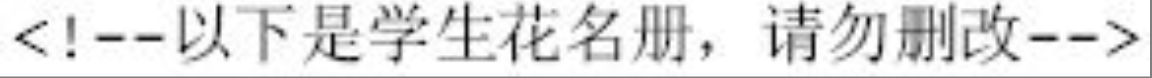
节点拷贝
在对XML文档进行处理时,XSLT还可以通过拷贝的方式复制节点,方法是利用xsl:copy和xsl:copy-of。
xsl:copy只拷贝当前节点,不包括子节点和属性。而xsl:copy-of的拷贝内容则包括当前节点、子节点和属性。
循环处理
使用xsl:for-each可对所选节点依次进行处理,如在生成表格处理中利用循环将各个学生的信息取出放入表格中的,写法如下。
图片详情

图片详情

排序
用xsl:for-each或xsl:apply-templates匹配的节点可使用xsl:sort将所选节点内容进行排序,如下所示。
1)按大小写排序
图片详情
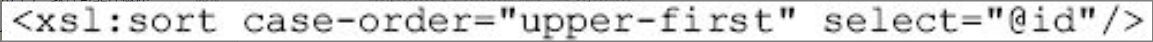
将以id为关键字按大写优先排序,而
图片详情
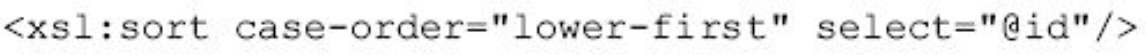
将以id为关键字按小写优先排序。
按字母顺序排序
图片详情
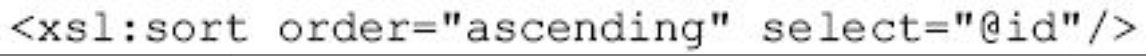
将以id为关键字按字母升序排序,而
图片详情

将以id为关键字按字母降序排序。
按数据类型排序
在有文本和数字混合的内容排序时,可指定按哪种数据类型排序。
对于一组id数据101, 2, 44, 305来说,如果写为
图片详情
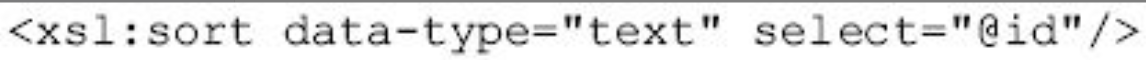
排序结果是101, 2, 305, 44。而写成
图片详情

排序结果是2, 44, 101, 305。
另外,还有一种排序方式,就是在前面学生花名册例中所使用的order-by:
图片详情

也可使得输出学生时按名字排序。
输出格式
XSLT是一个转换语言,它的目的是将XML源文档转换为另一种格式文档,它的输出结果可以是HTML文档,也可以是带css的XML文档。具体的输出格式由xsl:output指定。如果要输出为HTML文档,则写为
图片详情
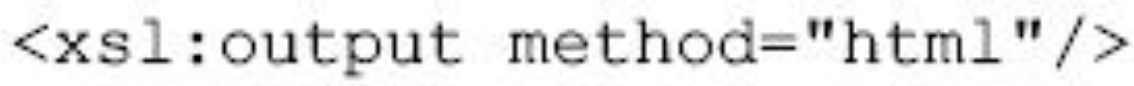
同样,要输出XML文档写为
图片详情
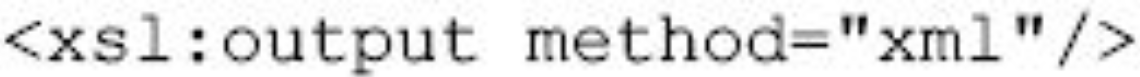
另外method”text”用来输出文本节点的内容,例如:
图片详情

如果文档中不出现xsl:output,将默认输出为XML文档,但如果在匹配模板时使用了
标记,则输出为HTML文档。输出为HTML文档时系统都会自动加上下面语句:图片详情

其他相关规范
XPath
当W3C首次开始开发一种XML查询语言时,他们意识到XPointer和XSLT组正在尝试完成访问一个XML文档的特定段的功能。因此,Xpointer,XSLT和XPath组进行了合作,指定为XML使用一种查询语言。XPath给XSLT和XPointer提供一个共同、整合的定位语法,用来定位XML文档中各个部位。在XSLT和XPointer之间,使用一种通用的语法——XPath来实现功能的共享。
XPath采用简洁的、非XML的语法,它基于XML文档的逻辑结构,在该结构中进行导航。XPath表达式通常出现在URL和XML属性值里。除了用于定位,XPath自身还有一个子集能用于进行匹配,它能验证一个节点是否匹配某个模式。XPath将XML文档描绘为树或节点的模型,节点的类型有根节点、元素节点、属性节点、文本节点、注释节点、名称空间节点和处理指令节点7种。
XPath规范定义了两个主要部分:一部分是表达式语法,另一部分是一组名为XPath核心库的基本函数。
指向某个XML文档中一个特定节点的路径由三部分信息构成:一个轴类型、一个节点测试和谓词。轴类型有多种,用来指定所选节点和环境之间的关系。节点测试用来指定根据上下文节点要查找什么类型的节点,除元素和属性节点外,可能使用的其他节点测试包括通配符“*”、text()、node()、comment()、processing-instruction()等。谓词以“[”开始,以“]”结束。谓词可以通过使用内置的函数来过滤不需要的节点,从而到达所需节点。将轴、节点测试和谓词信息类型放到一起,会生成下面的位置步语法结构。
<轴>::<节点测试>[<谓词表达式>]
例如,child::sibling[position()=3],这个XPath语句使用一个谓词来选择上下文节点的第3个sibling子节点。
位置步首先利用轴和节点测试计算,得到初始结果集,然后依次利用谓词进行过滤;初始结果集中满足所有谓词的就是返回结果。
位置步总结了XPath语言实际上是如何工作的。要到达一个特定节点的位置,必须使用一个XPath表达式或模式来列出到达那步骤,这个过程的每一步都被一个“/”字符分开,这些位置步和“/”字符组成位置路径。位置路径是XPath中最普通的表达式类型。
XPath是用作XSLT和XPointer的对XML文档各部分进行定位的语言。但是,XPath不是作为一种独立语言设计的,它只在与另一种语言(例如XPointer或XSLT)一起使用时才有用。
XLink和XPointer
XLink指定一个文档如何链接到另一个文档,XPointer指定文档内部的位置,它们都是基于XPath推荐标准。现在对它们进行一下简要的介绍。
XLink规范是W3C在2000年2月21日发布的工作草案。在www.w3.org/TR/xlink可以找到这个规范的最新版本。XLink用于从一个文档链接到另一文档。下面是W3C在工作草案中描述的:
此规范定义了3CML链接语言(XML Linking Language, XLink),它允许为创建和描述资源间的链接而在XML文档中插入元素。它使用XML语法创建结构对象,能够描述现在的HTML简单的单向超链接,也能描述更复杂的链接。
这里有一个例子用来了解一下XLink大概是什么样子。不像HTML超链接,在XML中任何元素都可以是一个链接。用xlink:type属性来指定一个元素成为链接,在这里创建了一个简单的Xlink。
图片详情

在本例中,通过设置xlink:type属性为simple创建了一个简单的XLink,很像HTML中的超链接。将xlink:show属性设置为new,这意味着兼容XLink的软件应当在新的窗口或其他显示上下文中打开链接到的文档。另外,将xlink:href属性设置为新文档的URIURI更为通用,并且链接不一定使用在这里使用的URL形式。
出于熟悉的缘故,以一个简单的XLink开始,因为它与HTML链接非常相似。除了基本的单向链接,也就是在这里创建的简单链接,也可以创建双向链接和多文档间的链接,甚至是文档集间的链接。另外,还可以做更多的事情,包括在被称为链接库的链接数据库中对的链接排序。
XLink使能链接到一个指定的文档,但是经常需要更为精确的定位。XPointer允许在文档内部定位,而不必改变文档嵌入特殊的标记。
在文档内部指定位置,XPointer规范是基于XPath规范的。
它允许识别文档中指定结点,举例如下。
图片详情
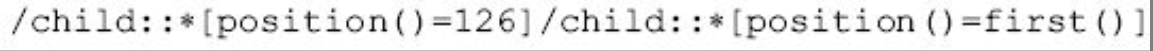
下面是W3C关于XPointer的描述:
此规范定义了XML指针语言(XML Pointer Language, XPointer),为任何URI引用用作段标识符,URI引用是用于定位Internet媒体类型text/xml或application/xml资源的。基于XML路径语言的XPointer支持在XML文档内部结构中寻址。它允许遍历文档树和选择其中的一部分,并且是基于各种特性的,例如元素类型、属性值、字符内容、相对位置等。
尽管XPointer基于xPath规范,但是XPointer规范在许多方面扩展了XPath。
如何将XPointer加入文档的URI来识别文档中的指定位置?只需加上符号“#”,(遵从HTML对URL的用法,URL指明链接的目标),然后是xpointer(),并将想使用的表达式放入圆括号中。举例如下:
图片详情
