UML建模与架构文档化
早在20世纪70年代就陆续出现了面向对象的建模方法,在80年代末到90年代中期,各种建模方法如雨后春笋般从不到10种增加到50多种。但方法种类的膨胀,同时极大地妨碍了用户的使用和交流。UML(统一建模语言)一出现,以融合了多种面向对象建模方法,简洁的图形与符号,直观的表示和强大的表示能力,得到工业界与学术界认可。它通过统一的表示法,使不同知识背景的领域专家、系统分析和开发人员以及用户可以方便地交流。
全称,Unified Modeling Language
zhihu:UML 还有用吗?
zhihu:敏捷开发
zhihu:UML 在业界的使用情况如何?
简书:uml类图(言简意赅)
包含,拓展,泛化关系的区别
类图中的四种类关系:关联、聚合和组合、依赖、泛化
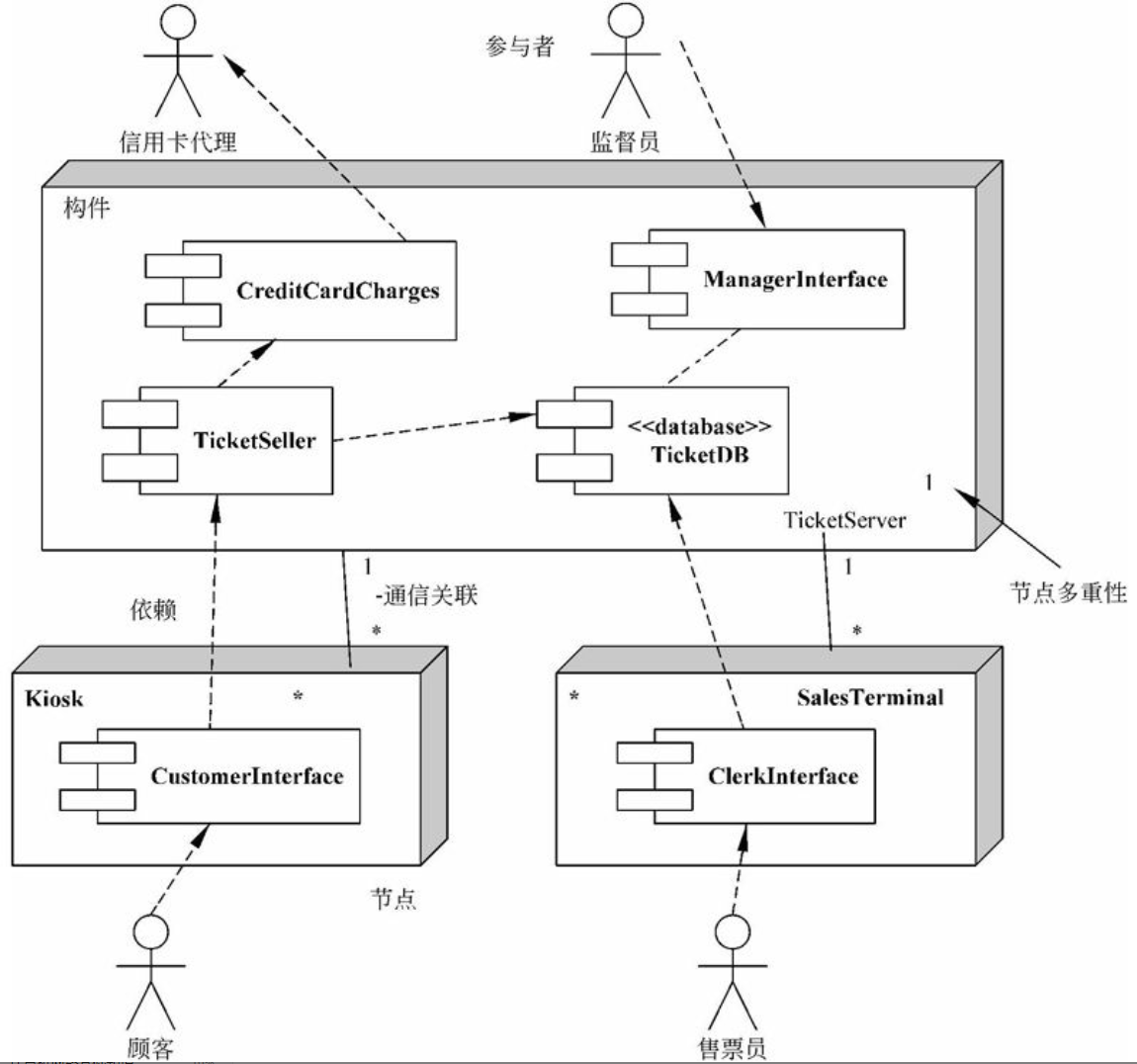
软件架构视图—4+1视图模式,即各视图的对应关系
UML中的图和各视图的对应关系
- 场景视图:用例图
- 逻辑视图:类图和对象图
- 开发视图:类图和组件图
- 进程视图:顺序图、协作图、状态图、活动图、组件图
- 部署视图:部署图
UML现状与发展
UML起源
在1995年,Gray Booch和Janes Rumbaugh将他们的面向对象建模方法统一为Unified Method V0.8。一年之后Ivar Jacobson加入其中,共同将该方法统一为二义性较少的UML0.9。同时,这三位杰出的方法学家被称为“三友(Three Amigos)”。
很快用户也认识到可对软件系统进行可视化、描述、构造和文档化的通用建模语言所带来的益处。他们充满激情地将这种语言的早期草案应用于不同的领域。受用户强烈需求的驱动,建模工具厂商也很快在它们的产品中加入了对UML的支持。
UML成了实际上的工业标准。1996年,一个由建模专家组成的国际性队伍“UML伙伴组织”开始同“三友”一起工作,计划将UML提议作为OMG(Object Management Group)的标准建模语言。
1997年1月,伙伴组织向OMG提交了最初的提案UML 1.0。经过了九个月的紧张修订,于1997年9月提出了最终提案UML 1.1,这个提案在1997年11月被OMG正式采纳为对象建模标准。
在一个规范被采纳后不久,将成立一个修订任务组,负责该规范的修订。1997年9月,OMG采纳UML1.1规范之后不久,特许成立了第一个UML修订任务组(Revision Task Forces, RTF),负责收集有关评论,并且提出修改建议。
该RTF提交的第一个主要产品是一个编辑版本UML 1.2,它改编了规范,使之与其他OMG规范更为一致。尽管这一版本纠正了印刷和语法错误,以及某些明显的逻辑上的不一致,但还是没有涉及对重要技术的改进。
该RTF的第二个主要的产品是其技术版本UML 1.3,它修正和改善了UML 1.1的遗留问题,并矫正了在此之后发现的许多小错误。该RTF一致推荐OMG批准其UML 1.3最终草案,并于1999年6月提交了一份最终报告。被推荐的规范随后被提交给组织委员会和平台技术委员会以获得批准。
UML体系结构演变
UML是用元模型来描述的,元模型是4层元模型体系结构模式中的一层。此模式的其他层次分别是元—元模型层、模型层和用户对象层。其中元模型层由元—元模型层导出,UML的元—元模型层在OMG MOF的元—元模型中定义,而UML元模型中的元类是MOF元—元类的实例。
元模型的体系结构模式已被证明可以用来定义复杂模型所要求的精确语义,这种复杂模型通常需要被可靠地保存、共享、操作以及在工具之间进行交换。它的特点如下:
(1)它在每一层都递归地定义语义结构,从而使语义更精确、更正规。
(2)它可用来定义重量级和轻量级扩展机制,如定义新的元类和构造型。
(3)它在体系结构上将UML元模型与其他基于4层元模型体系结构的标准(比如MOF和用于模型交换的XMI Facility)统一起来。
在元模型层,UML元模型又被分解为三个逻辑子包:基础包、行为元素包和模型管理包。其中基础包由核心、扩展机制和数据类型三个子包构成,它是描述模型静态结构的语言底层结构,支持类图、对象图和构件图和部署图等结构图。行为元素包是描述模型动态行为的语言上层结构,支持不同的行为图,包括Use Case(用况)图、顺序图、协作图、状态图和活动图。模型管理包则定义了对模型元素进行分组和管理的语义,它描述了几种分组结构,包括包、模型和子系统。行为元素包和模型管理包都依赖于基础包。
UML 1.3是建模语言规范第一个成熟的发布。它纠正或调整了从UML 1.1中继承下来的遗留问题,并且修正了最终提交后的一年来所发现的大多数错误。从建模者的角度看,从UML 1.1到UML 1.3并没有很大变化,对语言的大部分改进是在底层对UML元模型语义的调整,只有很少量的变化是针对表示法的细枝末节的修改。底层结构上的变化对大多数用户来说是看不到的,但这使得UML在将来更容易实现和扩展。
解决UML 1.1的遗留问题
1)完善活动图的语义和表示法增加了状态的动态激发语义,定义了执行条件线程的语义和表示法,而且增加了对象流功能。为了做这些修订,还需要对活动图所依赖的状态机语义做以下修改:为同步并发的活动加入“同步状态”、精化信号的语义、为合并状态转换定义附加的伪状态。
(2)清理关系的标准元素。引入关系元类来组织各种类型的关系,并且把依赖构造型改造为依赖和流。此外,精练了泛化,不再需要以前的许多构造型(如继承、私有、子类、子类型等)。依赖和其他关系名称的一致性也有所改进。
(3)体系结构的一致性。通过加入物理元模型和XMI (XML metadata Interchange)、DTD (Document Type Definition)定义,提高了UML 1.3元模型的体系结构跟MOF和XMI Facility的一致性。从UML语义逻辑元模型导出的物理元模型包含了一些支持产生IDL (Interface Definition Language)和XMI DTD的修改(例如将关联类转化为类)。尽管这样做与严格的元模型方法相左,但它为未来UML的修订达到这一目标提供了桥梁。
其他变化
(1)静态结构图。放宽了限制,使类和接口之间可以关联,并且在类中可以声明信号。信号被定义为一个类元,可以操作。另外,还重新定义了模板和强类型的语义。
(2)用例图。用例之间的关系被重新定义为三种主要类型: $\color{green}{\text{泛化}}$ 、 $\color{green}{\text{包含}}$ 和 $\color{green}{\text{延伸}}$ 。
(3)交互图。放宽了限制,使用户可以描述角色或实例。而且协作也可以泛化。
(4)模型管理图。改进了模型和子系统的语义和表示法,将它们从包中分离出来,并使之更容易使用。澄清了对包的访问和引入权限的区别。
尽管UML规范的核心是语法和语义定义,但它还包括模型交换、语言扩展以及约束等方面的定义。UML 1.3对这些相关规范都进行了错误纠正,并使之与核心语言的改进保持一致。
为UML 2.0确立路标
该RTF在最终报告中明确了因为超出其范围或时间不允许而不能做的各种改进。他们建议下一个RTF应特别注意扩展性和文档管理方面的问题。对目前的扩展机制,用户和工具开发商已经发现了一些重要问题,而涌入新UML外围的提案可能会加剧这些困难。在文档管理方面,物理元模型和XMI DTD规范的加入大幅度地增加了UML规范的长度,并使它变得笨拙难用(它现在已有800多页了)。下一次UML修订将会把物理建模规范拆分为单独的文档。
该RTF还进一步建议负责起草UML 2.0 RFP的工作组考虑以下问题。
- 体系结构:使用严格的元模型方法定义一个与MOF元—元模型严格一致的物理元模型。给出改进的指导方针,以决定哪些部分应该定义在核心语言中,哪些部分应定义在UML的外围或标准模型库中。
- 扩展性:提供同4层元模型体系结构一致的扩展机制。提高外围规范的严密程度,使其支持用户对语言定制能力不断增加的要求。
- 构件:增强基于构件的软件开发的语义和表示法。
- 关系:提供“精化”和“追踪”依赖关系的基本语义。在多个抽象层次上定义关联的语义。
- 状态图和活动图:定义独立于状态图语义的活动图语义。在活动图和状态图中提供更随意的并发。详细说明状态机的泛化。
- 模型管理:重新定义模型和子系统的表示法和语义,以增强对企业体系结构视图的支持。
- 总体机制:定义一种模型版本管理的机制。详细说明图的互换机制。
UML的应用与未来
UML是在多种面向对象建模方法的基础上发展起来的建模语言,主要用于软件密集型系统的建模。它的演化,可以按其性质划分为以下几个阶段:最初的阶段是专家的联合行动,由三位Object-Oriented(面向对象)方法学家将他们各自的方法结合在一起,形成UML 0.9。第二阶段是公司的联合行动,由十几家公司组成的“UML伙伴组织”将各自的意见加入UML,形成UML 1.0和1.1,并作为向OMG申请成为建模语言规范的提案。第三阶段是在OMG控制下的修订与改进,OMG于1997年11月正式采纳UML 1.1作为建模语言规范,然后成立任务组进行不断的修订,并产生了UML 1.2、1.3和1.4版本,其中UML 1.3是较为重要的修订版。目前正处于UML的重大修订阶段,目标是推出UML 2.0,作为向ISO提交的标准提案。
从UML的早期版本开始,便受到了计算机产业界的重视,OMG的采纳和大公司的支持把它推上了实际上的工业标准的地位,使它拥有越来越多的用户。它被广泛地用于应用领域和多种类型的系统建模,如管理信息系统、通信与控制系统、嵌入式实时系统、分布式系统和系统软件等。近几年还被运用于软件再工程、质量管理、过程管理和配置管理等方面。而且它的应用不仅仅限于计算机软件,还可用于非软件系统,例如硬件设计、业务处理流程、企业或事业单位的结构与行为建模。
对UML的讨论和评价,无论是Internet上的意见交流,或是每年一次的UML研讨会,还是学术期刊上发表的文章,都是既肯定其成绩,又指出其缺点和错误,并且以积极的态度提出建设性意见。总的来说:
- UML已经取得重要成功,它已成为在软件工业中占支配地位的建模语言,并在许多领域的软件开发中得到应用。
- UML还存在许多问题,自它产生之日起就从未离开过批评:用户和教师抱怨它内容庞大、难学难教而且太过复杂;学者认为它缺少一个精练的核心和定义良好的外围,有些语义定义得不够精确而且带有二义性;建模实践者认为它缺少支持自己领域建模要求的机制;工具开发商则因为规范本身的不确定性而产生理解上的偏差,它们对UML的自行诠释有可能误导用户。
- UML的关键问题是过于庞大和复杂,以及在语言体系结构、语义等方面存在理论缺陷。产生这些问题的一个重要原因是,在形成规范的过程中不得不照顾多种方法流派的观点和多家公司的利益。
UML基础
概述
UML通过图形化的表示机制从多个侧面对系统的分析和设计模型进行刻画。它共定义了10种视图,并将其分为如下4类。
(1)用例图(use case diagram)。从外部用户的角度描述系统的功能,并指出功能的执行者。
(2)静态图。包括类图(class diagram)、对象图(object diagram)和包图(package diagram)。类图描述系统的静态结构,类图的节点表示系统中的类及其属性和操作,类图的边表示类之间的联系,包括 $\color{green}{\text{继承}}$ 、 $\color{green}{\text{关联}}$ 、 $\color{green}{\text{依赖}}$ 和 $\color{green}{\text{聚合}}$ 等。对象图是类图的一个实例,它描述在某种状态下或在某一时间段,系统中活跃的对象及其关系。包图描述系统的分解结构,它表示包(package)以及包之间的关系。包由子包及类组成。包之间的关系包括继承、构成与依赖关系。
(3)行为图。包括交互图(interactive diagram)、状态图(statechart diagram)与活动图(active diagram),它们从不同的侧面刻画系统的动态行为。交互图描述对象之间的消息传递,它又可分为顺序图(sequence diagram)与合作图(collaboration diagram)两种形式。顺序图强调对象之间消息发送的时间序。合作图更强调对象间的动态协作关系。合作图也可通过消息序号来表示消息传递的时间序,只不过这种表示不如顺序图那样直观。状态图描述类的对象的动态行为,它包含对象所有可能的状态、在每个状态下能够响应的事件以及事件发生时的状态迁移与响应动作。活动图描述系统为完成某项功能而执行的操作序列,这些操作序列可以并发和同步。活动图中包含控制流和信息流。
4)实现图(implementation diagram)。包括构件图(component diagram)与部署图(deployment diagram),它们描述软件实现系统的组成和分布状况。构件图描述软件实现系统中各组成部件以及它们之间的依赖关系。部署图描述作为软件系统运行环境的硬件及网络的物理体系结构,其节点表示实际的计算机和设备,边表示节点之间的物理连接关系,也可显示连接的类型及节点之间的依赖性。
用例和用例图
用例(use case)国内也翻译为用况、用案等,在UML中,用例用一个椭圆表示,用例名往往用动宾结构或主谓结构命名。它有两个比较有代表性的定义如下。
定义1:用例是对一个 $\color{green}{\text{活动者}}$ (actor)使用系统的一项功能时所进行的交互过程的一个文字描述序列。
定义2:用例是系统、子系统或类和外部的参与者(actor) $\color{green}{\text{交互的动作序列}}$ 的说明,包括可选的动作序列和会出现异常的动作序列。
用例是代表系统中各相关人员之间就系统的行为所达成的契约。软件的开发过程可以分为$\color{green}{\text{需求分析}}$、$\color{green}{\text{设计}}$、$\color{green}{\text{实现等阶段}}$,在需求阶段用例是分析人员与客户沟通的工具和项目规模估算的依据;设计阶段用例是系统功能设计的主要输入;在实现阶段用例是检测类行为正确性的文档。因此,面向对象的软件开发过程是用例驱动的。
用例分析可以支持领域建模(domain modeling),以确保定义正确的需求(right requirements),是保证OO软件开发成功的基础。但要在具体的项目中灵活使用用例来捕获用户的需求并不是一件容易的事情,往往需要用户的经验、沟通能力、丰富的领域知识等。
本质上,用例分析是一种功能分解(functional decomposition)的技术,并未使用到面向对象思想。但用例是UML的重要部分,确定一个系统的用例是开发OO系统的第一步,用例分析这步做得好,接着的交互图分析、类图分析等才有可能做得好,整个系统的开发才能顺利进行。
编写用例必须识别以下元素。
参与者
角色(actor)是指系统以外的、需要使用系统或与系统交互的东西,包括人、设备、外部系统等。actor有很多不同的译名,包括参与者、活动者、执行者和行动者等。
一个参与者可以执行多个用例,一个用例也可以由多个参与者使用。但需要注意的是,参与者实际上并不是系统的一部分,尽管在模型中会使用参与者。
参与者实际上是一个版型化的类,其版型是〈〈Actor〉〉。图6-1是参与者的三种表示形式。
图6-1 参与者的表示形式
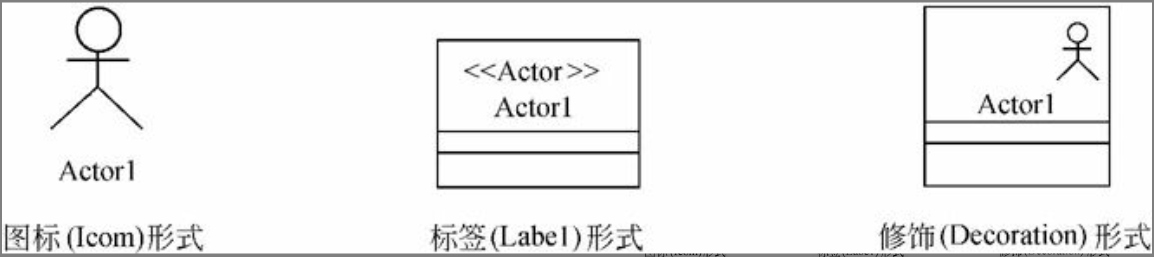
$\color{red}{\text{版型}}$化是什么意思。
用例间的关系
用例除了与参与者有 $\color{green}{\text{关联}}$ (association)关系外,用例之间也存在着一定的关系(relationship),如 $\color{green}{\text{泛化}}$ (generalization)关系、 $\color{green}{\text{包含}}$ (include)关系、 $\color{green}{\text{扩展}}$ (extend)关系等。
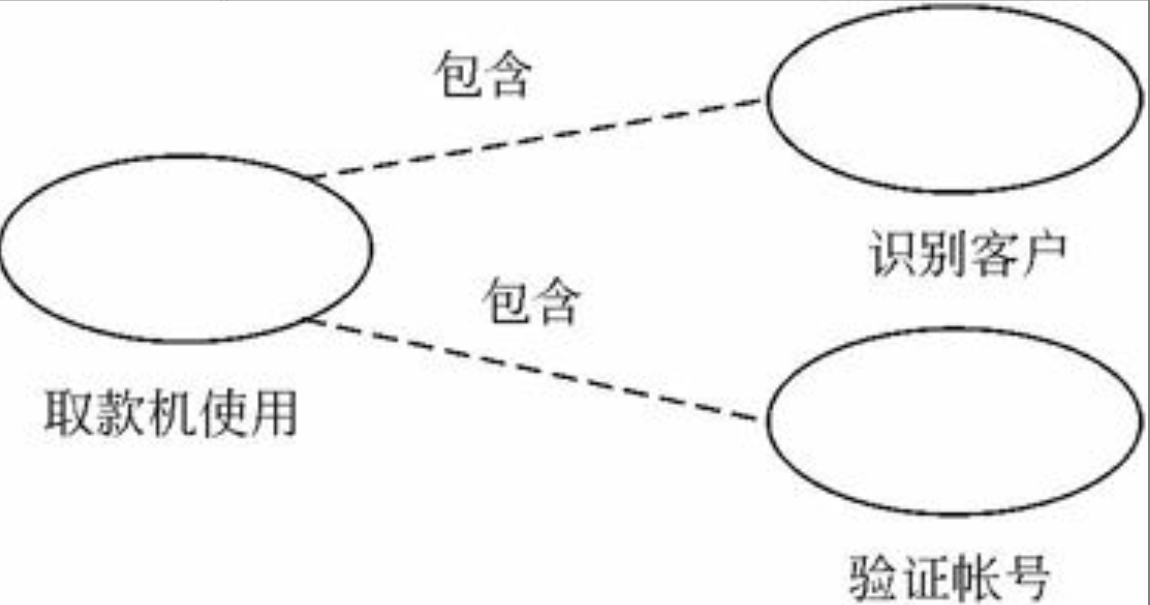
包含(include)关系指的是两个用例之间的关系,其中一个用例(称作基本用例,base use case)的行为包含了另一个用例(称作包含用例,inclusion use case)的行为。包含关系是依赖关系的版型,也就是说包含关系是比较特殊的依赖关系,它们比一般的依赖关系多一些语义。如图6-2所示是包含关系的例子,其中用例取款机专用(ATM Session)是基本用例,用例识别客户(Identify Customer)和验证账号(Validate Account)是包含用例。
图6-2 用例的包含关系
扩展(extend)关系的基本含义与泛化关系类似。但在扩展关系中,对于扩展用例(extension use case)有更多的规则限制,即基本用例必须声明若干“扩展点”(extension point),而扩展用例只能在这些扩展点上增加新的行为和含义。图6-3所示是同时具有扩展关系和包含关系的例子,在这个例子中,可以看到基本用例、包含用例、扩展用例等概念间的联系和区别。
图6-3 包含用例和扩展用例
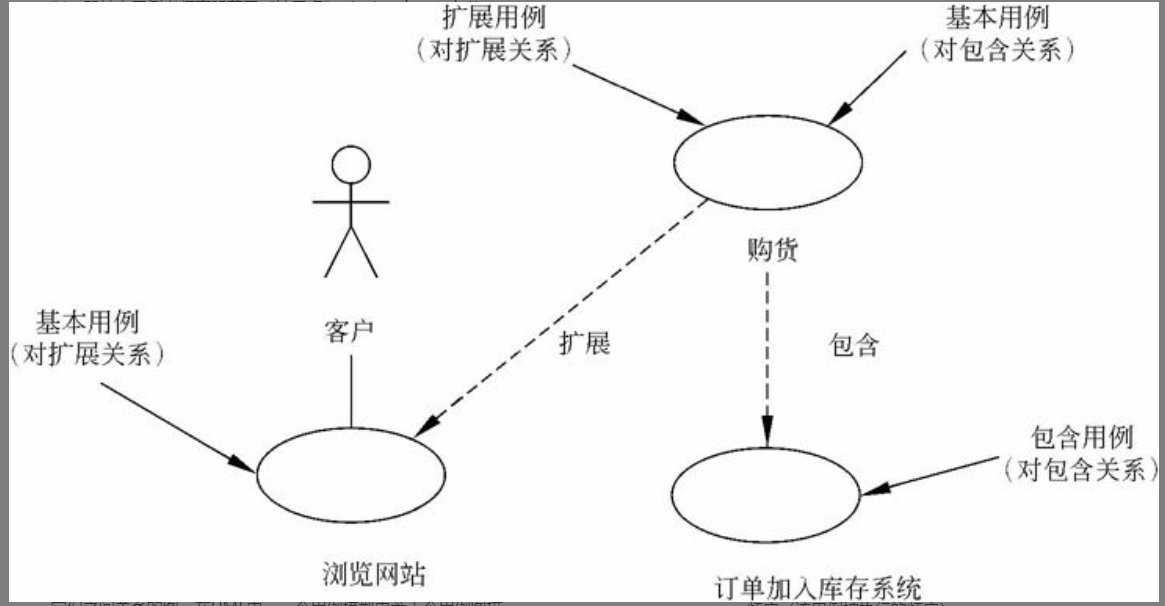
对于“购货”这个用例,它扩展了“浏览网站”这个用例,同时也包含了“订单加入库存系统”这个用例。因此对于“浏览网站”这个用例来说是扩展用例,但对于“订单加入库存系统”这个用例来说是基本用例。
用例图
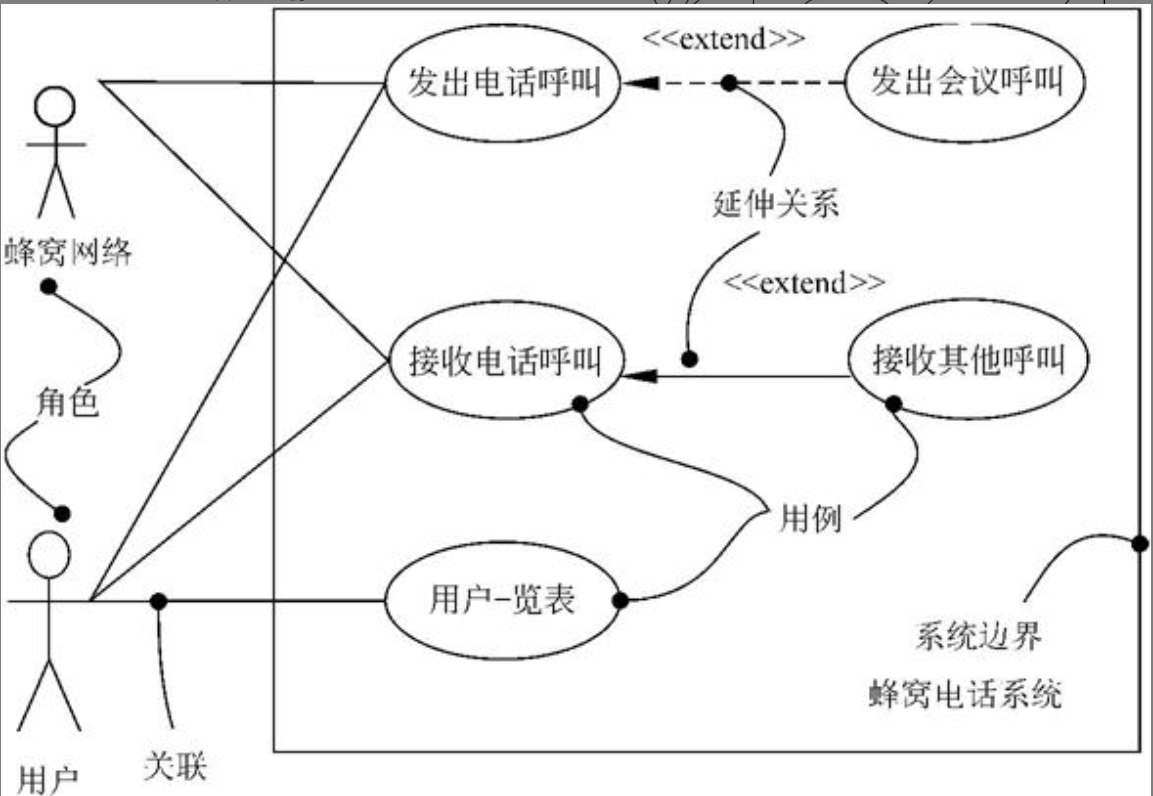
用例图(use case diagram)是显示一组用例、参与者以及它们之间关系的图。在UML中,一个用例模型由若干个用例图描述。如图6-4显示了电话系统的使用用例图。
UML规范说明中并不使用颜色作为图形语义的区分标记,但建模人员可以在图中给某些图符加上填充颜色,以强调某一部分的模型,或希望引起使用者的特别注意。但在语义上,使用填充颜色和不使用填充颜色的模型是一样的。
用例的描述
用例的描述才是用例的核心部分,用例采用自然语言描述参与者与系统进行交互时双方的行为,不追求形式化的语言表达。以下是一个典型描述多方式。
图6-4 电话系统的使用用例图
用例:〈编号〉〈名称〉
用途及特征:
用例在系统中的目标(用例目标描述)
范围(当前考虑的是哪个系统)
级别(概要任务/首要任务/子功能)
当前条件(用例执行前系统应具有的状态)
成功后续条件(用例成功执行后应具有的状态)
失效后续条件(用例没有完成目标的状态)
触发(启动该用例执行的系列动作)
角色:首要角色(与该用例关联的首要角色)
主场景:动作序列
〈步骤编号〉〈动作描述〉〈系统响应〉
扩展场景:动作序列
〈步骤编号〉〈条件〉:〈动作或另一个用例〉
异常场景:
〈步骤编号〉〈条件〉:〈异常动作〉
相关信息(可选):
优先级(该用例对于系统/组织的关键程度)
性能目标(该用例的执行时间耗费)
频度(该用例被执行的频度)
与首要角色的联系渠道(包括交互式、静态文件、数据库等)
存在问题:
列出关于该用例的未解决问题
交互图
交互图(interaction diagram)是用来描述对象之间以及对象与参与者(actor)之间的动态协作关系以及协作过程中行为次序的图形文档。它通常用来描述一个用例的行为,显示该用例中所涉及的对象和这些对象之间的消息传递。交互图包括顺序图
(sequence diagram)和协作图(collaboration diagram)两种形式。顺序图着重描述对象按照时间顺序的消息交换,协作图着重描述系统成分如何协同工作。顺序图和协作图从不同的角度表达了系统中的交互和系统的行为,它们之间可以相互转化。一个用例需要多个顺序图或协作图,除非特别简单的用例。
交互图可以帮助分析人员对照检查每个用例中所描述的用户需求,如这些需求是否已经落实到能够完成这些功能的类中去实现,提醒分析人员去补充遗漏的类或方法。
顺序图
顺序图也称时序图。Rumbaugh对顺序图的定义是:顺序图是显示对象之间交互的图,这些对象是按时间顺序排列的。特别地,顺序图中显示的是参与交互的对象及对象之间消息交互的顺序。图6-5所示是一个简单的顺序图例子。
图6-5 顺序图
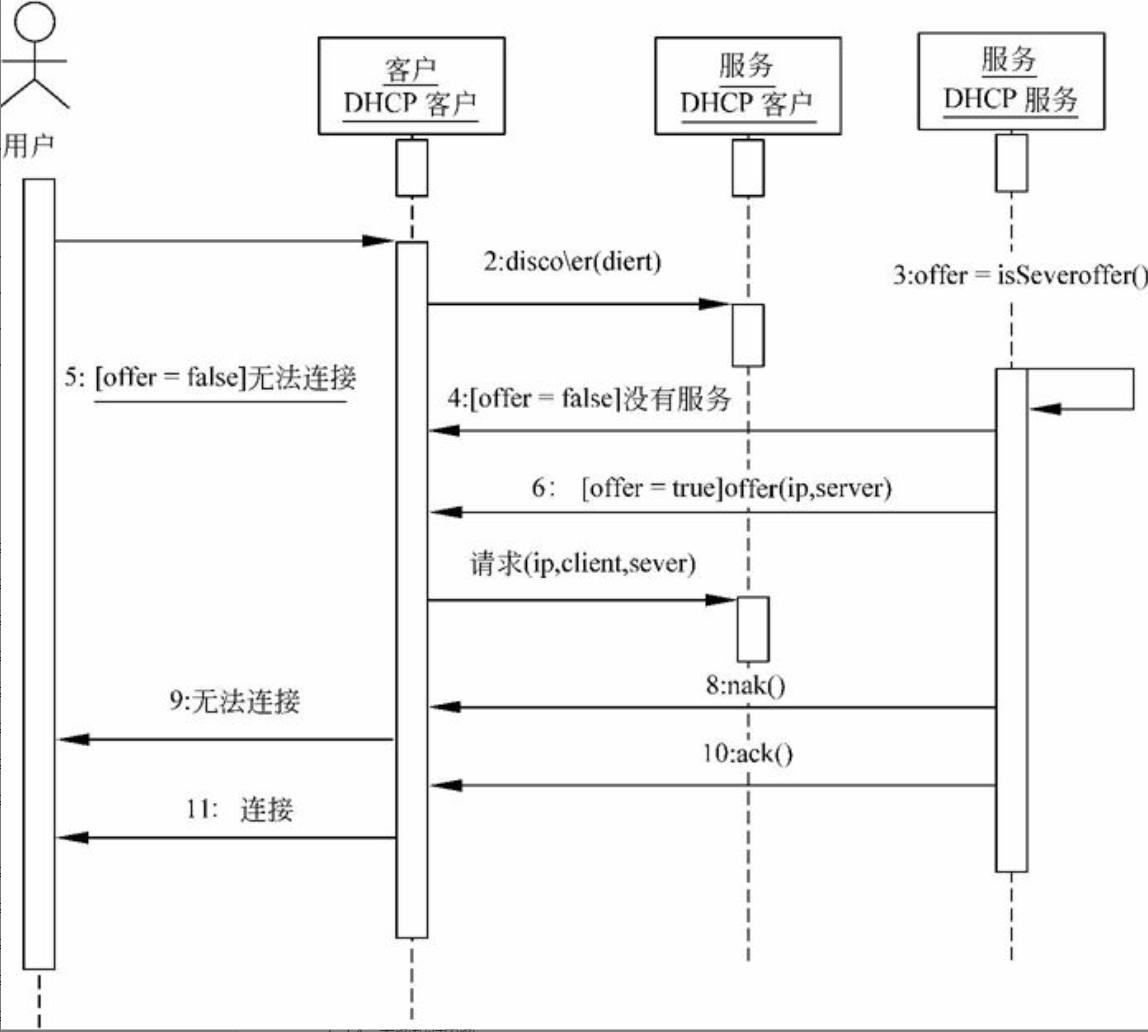
顺序图是一个二维图形。在顺序图中水平方向为$\color{green}{\text{对象维}}$,沿水平方向排列的是参与交互的对象。其中对象间的排列顺序并不重要,但一般把表示参与者的对象放在图的两侧,主要参与者放在最左边,次要参与者放在最右边(或表示人的参与者放在最左边,表示系统的参与者放在最右边)。顺序图中的垂直方向为$\color{green}{\text{时间维}}$,沿垂直向下方向按时间递增顺序列出各对象所发出和接收的消息。
协作图
协作图是用于描述系统的行为是如何由系统的成分协作实现的图,协作图中包括的建模元素有对象(包括参与者实例、多对象、主动对象等)、消息、链等。
类图和对象图
类是具有相似结构、行为和关系的一组对象的抽象。在UML中,类表示为划分成三个格子的长方形,如图6-6所示。
图6-6 UML中类的表示图
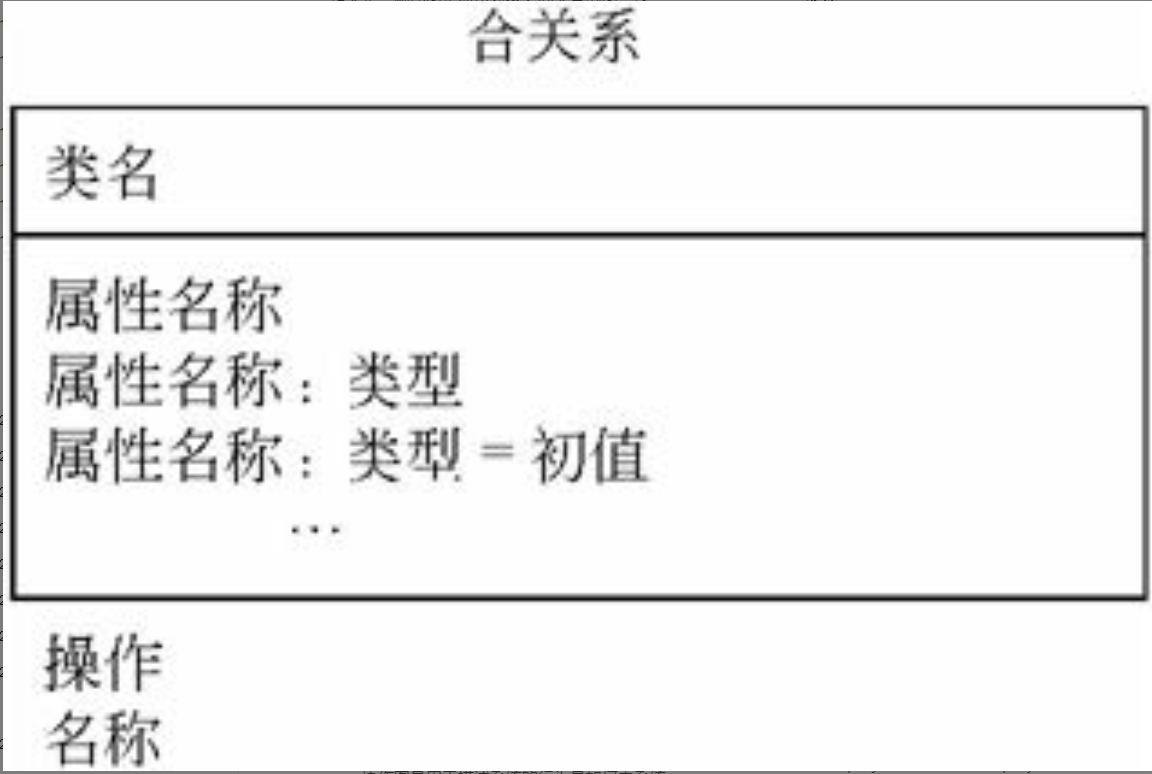
在定义类的时候,类的命名应尽量用应用领域中的术语,应明确、无歧义,以利于开发人员与用户之间的相互理解和交流。一般而言,类的名字是名词。
一般说来,类之间的关系有关联、聚集、组合、泛化和依赖等,下面将对这些关系进行详细说明。
关联
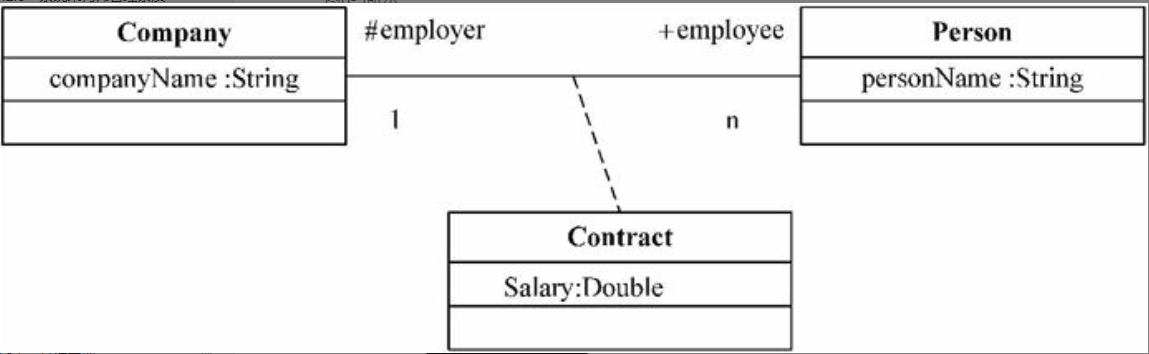
关联(association)是模型元素间的一种语义联系,它是对具有共同的结构特性、行为特性、关系和语义的链(link)的描述。在上面的定义中,需要注意链这个概念,$\color{green}{\text{链}}$是一个实例,就像对象是类的实例一样,链是关联的实例,关联表示的是类与类之间的关系,而链表示的是对象与对象之间的关系。
在类图中,关联用一条把类连接在一起的实线表示。关联两端的类可以某种角色参与关联。例如在图6-7中,Company类以employer的角色、Person类以employee的角色参与关联,employer和employee称为角色名。如果在关联上没有标出角色名,则隐含地用类的名称作为角色名。角色还具有多重性(multiplicity),表示可以有多少个对象参与该关联。在图6-7中,employer可以雇佣多个employee,表示为0..n;employee只能被一家employer雇佣,表示为1。
图6-7 关联的角色

通过关联类(association class)可以进一步描述关联的属性、操作以及其他信息。关联类通过一条虚线与关联连接。图6-8中的Contract类是一个关联类,Contract类中有属性salary,这个属性描述的是Company类和Person类之间的关联的属性,而不是描述Company类或Person类的属性。
图片详情
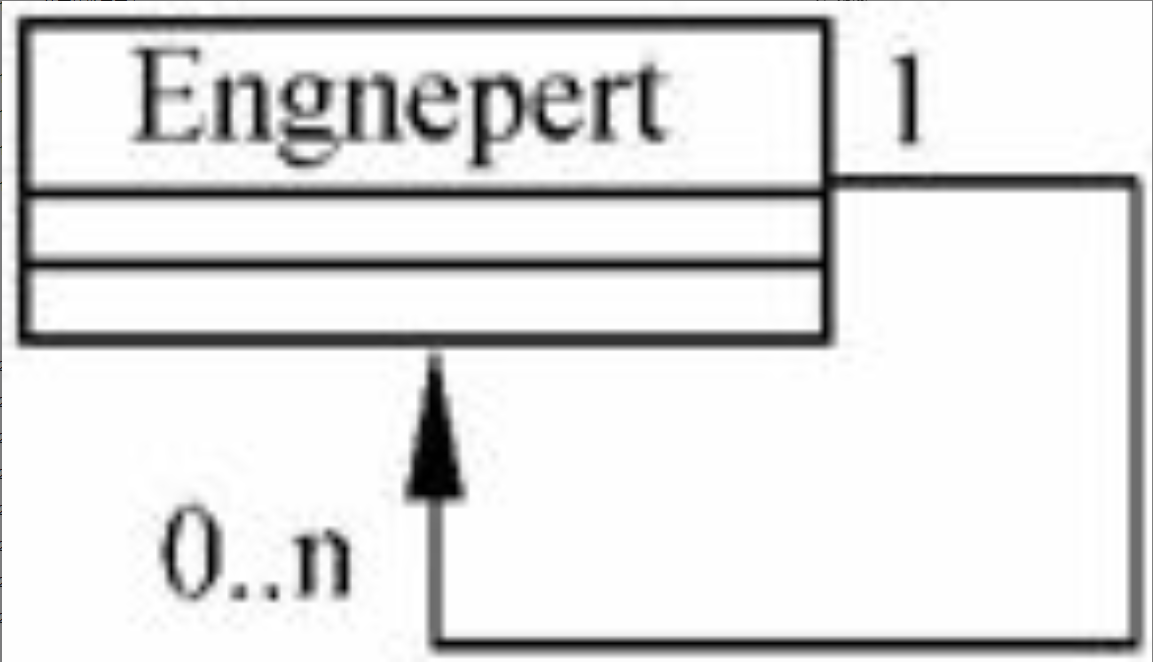
自返关联(reflexive association)又称递归关联(recursive association),是一个类与自身的关联,即同一个类的两个对象间的关系。自返关联虽然只有一个被关联的类,但有两个关联端,每个关联端的角色不同。自返关联的例子如图6-9所示。
图片详情
聚集和组合
聚集(aggregation)是一种特殊形式的关联。聚集表示类之间整体与部分的关系。在对系统进行分析和设计时,需求描述中的“包含”、“组成”、“分为……部分”等词常常意味着存在聚集关系(见图6-10)。
图片详情
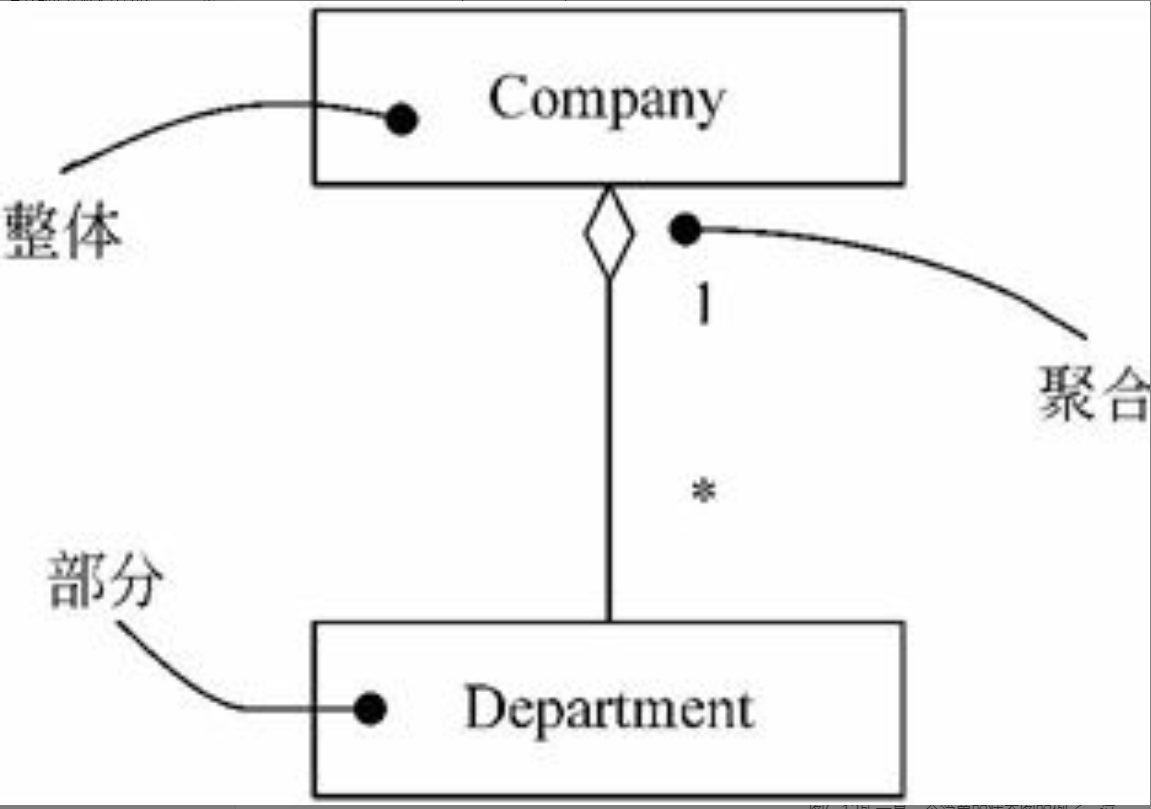
组合(composition)表示的也是类之间的整体与部分的关系,但组合关系中的整体与部分具有同样的生存期。也就是说,组合是一种特殊形式的聚集。
泛化关系
泛化(generalization)定义了一般和特殊元素之间关系,如果从面向对象程序设计语言的角度来说,类与类之间的泛化关系就是平常所说的类与类之间的继承关系。
UML中用一头为空心三角形的连线表示泛化关系。
依赖关系
假设有两个元素X、Y,如果修改元素X的定义可能会导致对另一个元素Y的定义的修改,则称元素Y依赖于元素X。
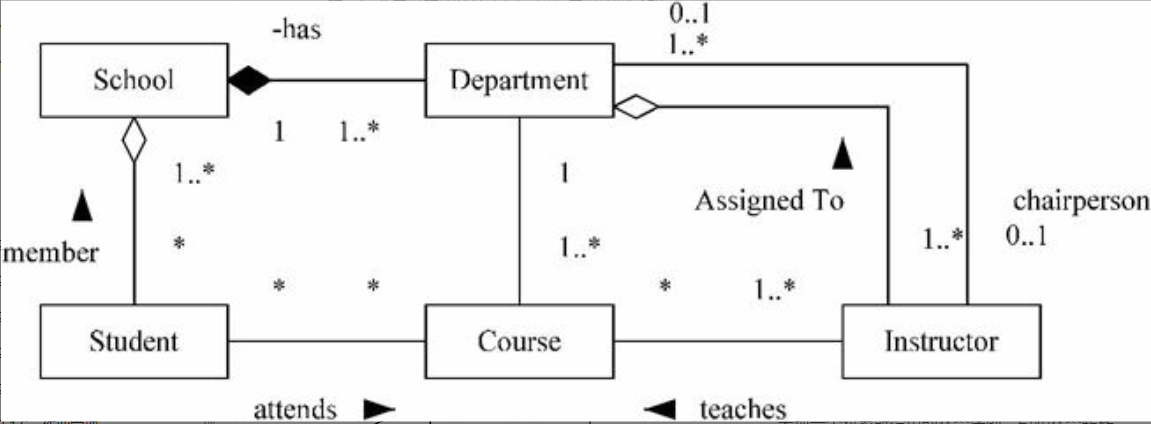
类图
6-11所示为学校内主要对象的类图。学校包含若干学生,是由多个系组成。每个系开设若干课程,学生参加不同课程学习(管联)关系;老师教一门或多门课程。在一个系中,有一个老师是领导,系包含若干老师。
类图以直观、抽象形式展示了不同对象之间关系。
图片详情
状态图和活动图
状态图
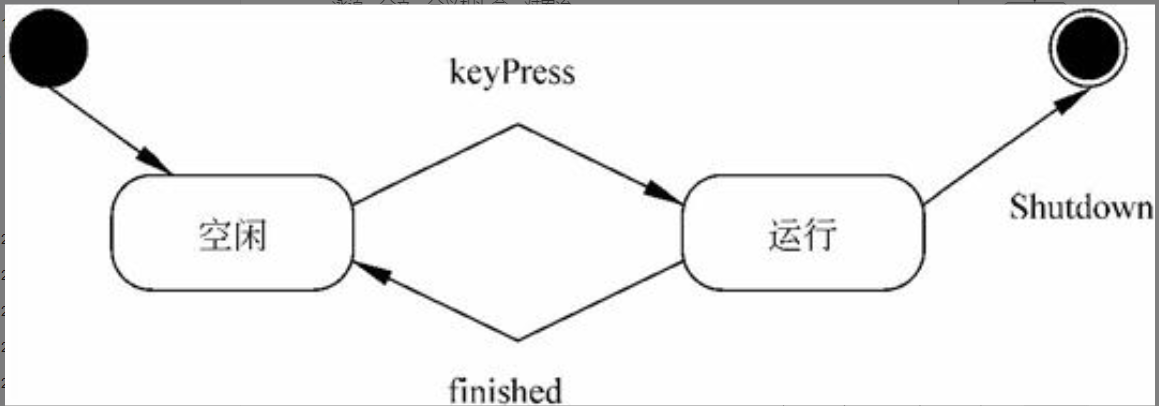
UML中的状态图(state chart diagram)主要用于描述一个对象在其 $\color{green}{\text{生存期间}}$ 的 $\color{green}{\text{动态行为}}$ ,表现一个对象所经历的状态序列,引起状态转移的 $\color{green}{\text{事件}}$ (event),以及因状态转移而伴随的 $\color{green}{\text{动作}}$ (action)。状态图是UML中对系统的动态行为建模的5个图之一,状态图在检查、调试和描述类的动态行为时非常有用。一般可以用状态机对一个对象的生命周期建模,状态图是用于显示状态机的,重点在于描述状态之间的控制流。
图6-12所示是一个简单的状态图的例子。这个状态图中描述的对象除了初态和终态外,还有Idle和Running两个状态,而keyPress、finished、shut Down等是事件。
图片详情
活动图
活动图是对系统的动态行为建模的5个图之一。活动图可以用于描述系统的工作流程和并发行为。活动图其实可看作状态图的特殊形式,活动图中一个活动结束后将 $\color{green}{\text{立即进入}}$ 下一个活动(在状态图中状态的转移可能需要事件的触发)。
下面讨论活动图中的几个基本概念:活动、泳道、分支、分叉和汇合、对象流。
1)活动
活动(activity)表示的是某流程中的任务的执行,它可以表示某算法过程中语句的执行。在活动图中需要注意区分动作状态(action state)和活动状态(activity state)这两个概念。动作状态是原子的,不能被分解,没有内部转移,没有内部活动,动作状态的工作所占用的时间是可忽略的。动作状态的目的是执行进入动作(entry action),然后转向另一个状态。活动状态是可分解的,不是原子的,其工作的完成需要一定的时间。可以把动作状态看作活动状态的特例。
2)泳道
泳道(swimlane)是活动图中的区域划分,根据每个活动的职责对所有活动进行划分,每个泳道代表一个 $\color{green}{\text{责任区}}$ 。泳道和类并不是一一对应的关系,泳道关心的是其所代表的职责,一个泳道可能由一个类实现,也可能由多个类实现。
3)分支
在活动图中,对于同一个触发事件,可以根据不同的警戒条件转向不同的活动,每个可能的转移是 $\color{green}{\text{一个分支}}$ (branch)。
4)分叉和汇合
分支表示的是从多种可能的活动转移中选择一个,如果要表示系统或对象中的并发行为,则可以使用分叉(fork)和汇合(join)这两种建模元素。分叉表示两个或多个控制流经过分叉后,这些控制流 $\color{green}{\text{并发}}$ 进行;汇合正好与分叉相反。
5)对象流
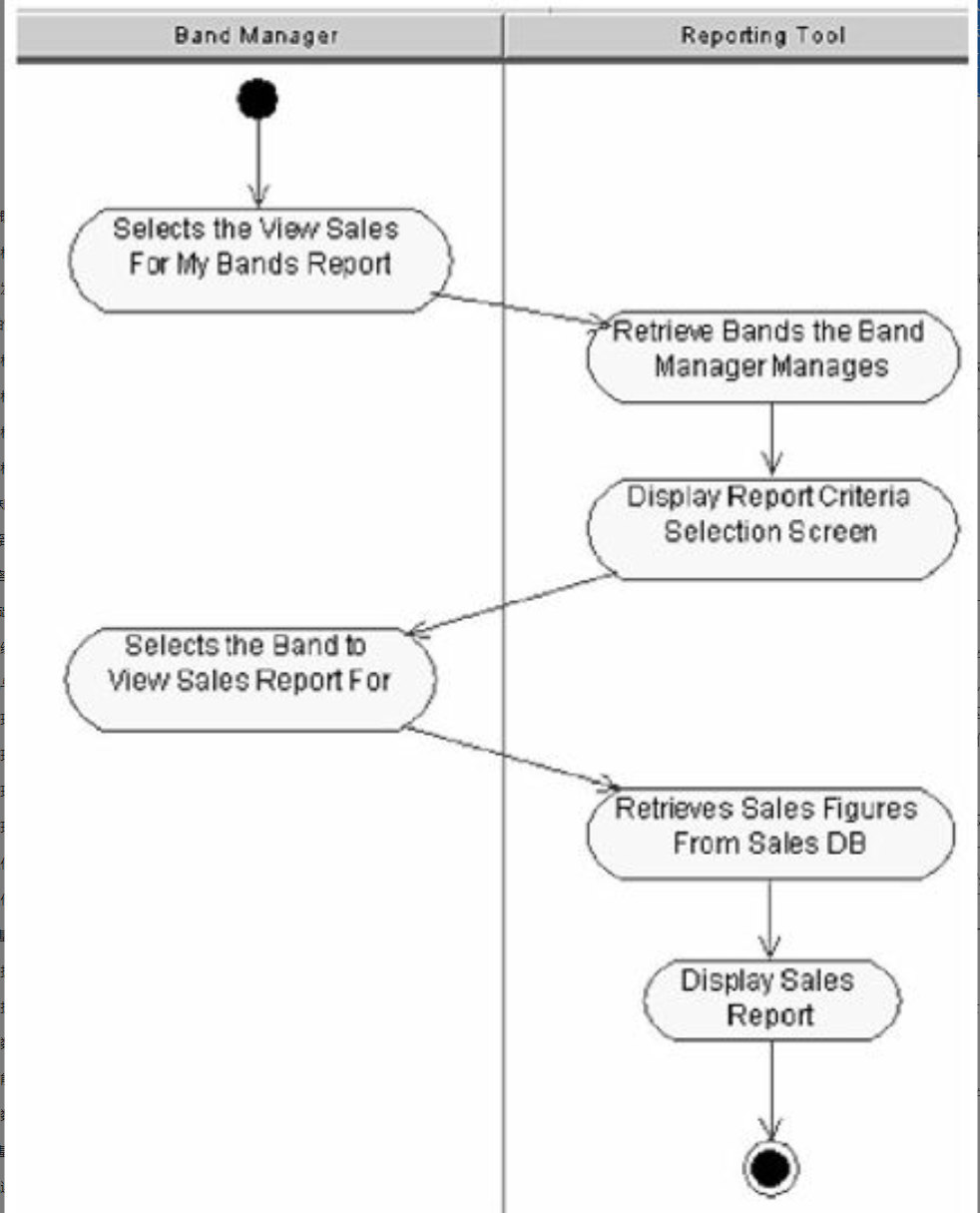
在活动图中可以出现对象。对象可以作为活动的输入或输出。活动图中的对象流表示活动和对象之间的关系,如一个活动创建对象(作为活动的输出)或使用对象(作为活动的输入)等。如图6-13所示。
活动图案例
构件图
构件(component)是系统中遵从一组接口且提供其实现的物理的、可替换的部分。构件图(componentdiagram)则显示一组构件以及它们之间的相互关系,包括编译、链接或执行时构件之间的依赖关系。图6-14所示是一个构件图的例子,表示.html文件、.exe文件、.dll文件这些构件之间的相互依赖关系。
图6-14 构件图
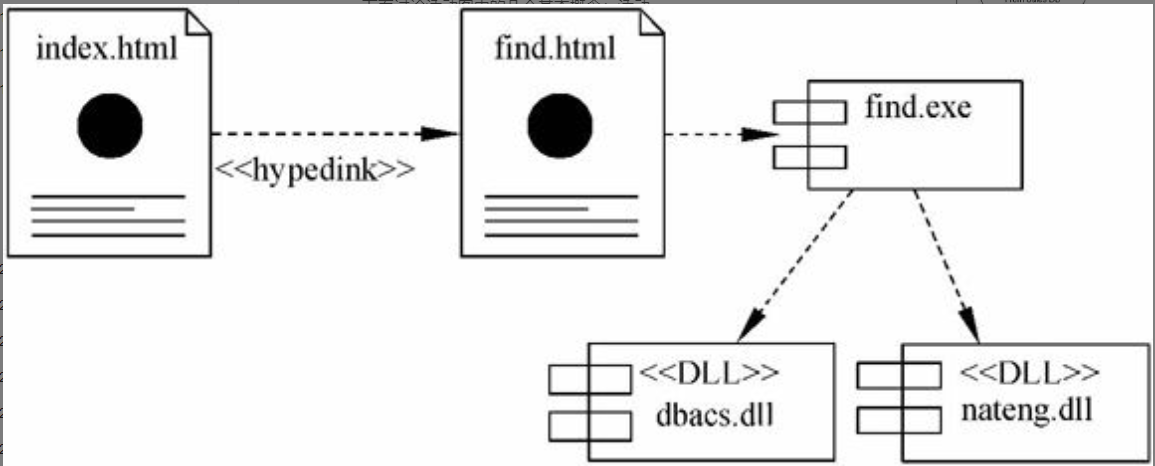
$\color{red}{\text{构件}}$ 就是一个 $\color{green}{\text{实际文件}}$ ,可以有以下几种类型:
1)部署构件(deploymentcomponent),如dll文件、exe文件、COM+对象、CORBA对象、EJB、动态Web页和数据库表等。
(2)工作产品构件(work productcomponent),如源代码文件、数据文件等,这些构件可以用来产生部署构件。
(3)执行构件(execution component),也就是系统执行后得到的构件。
构件图可以对以下几个方面建模:
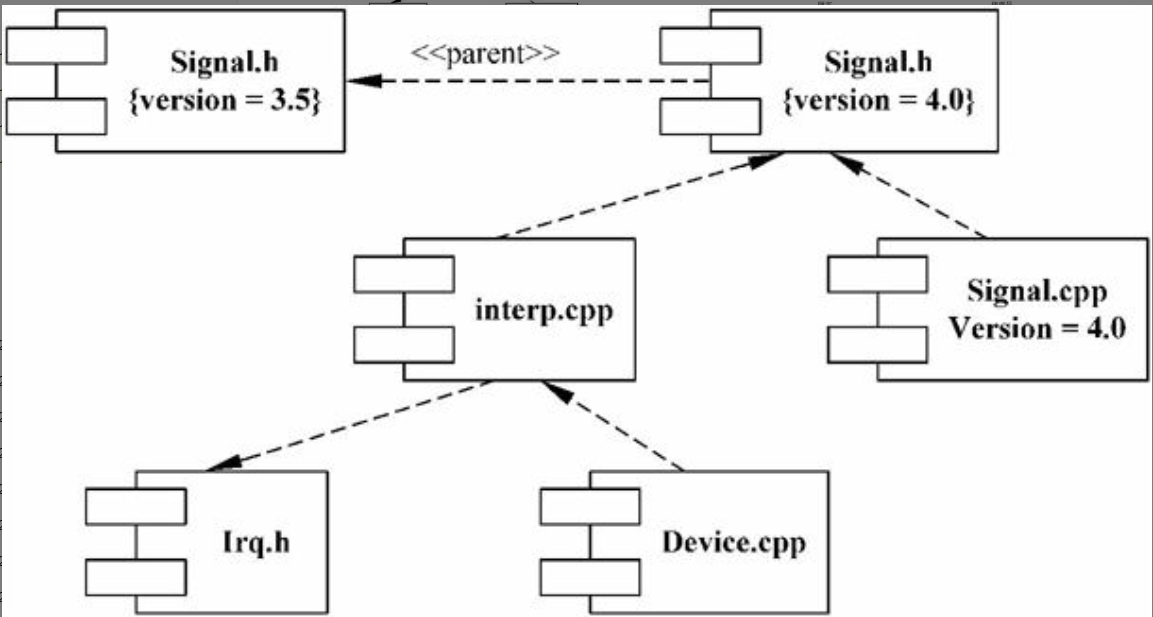
(1)对源代码文件之间的相互关系建模,如图6-15所示。
图6-15 构件图用于对源代码建模
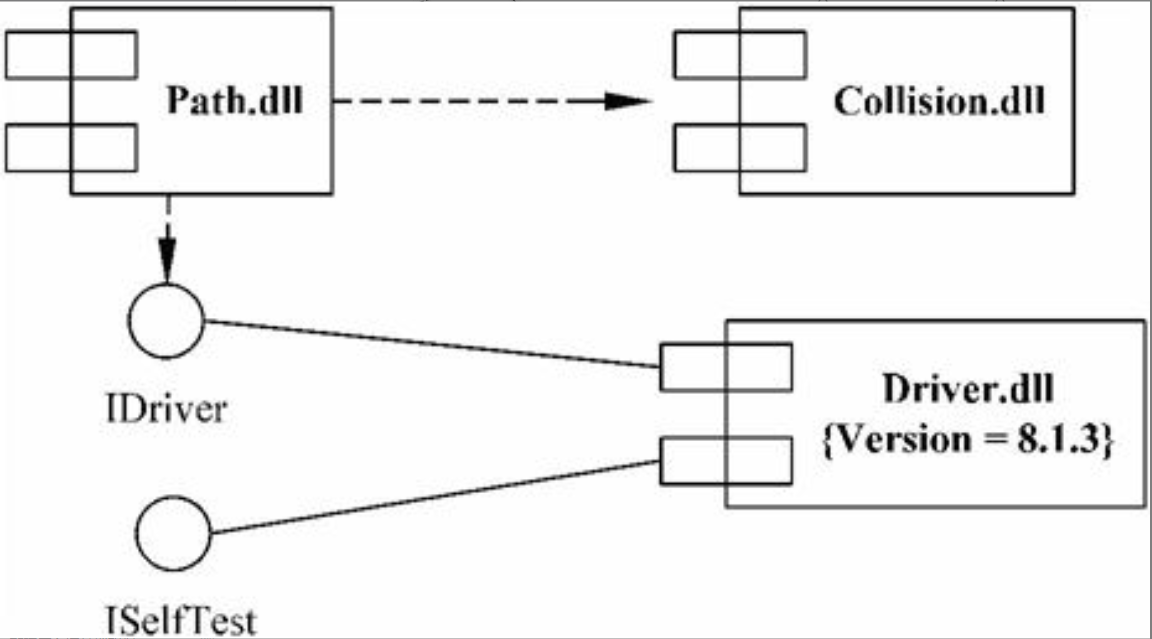
2)对可执行文件之间的相互关系建模。图6-16所示是某可运行系统的部分文件之间的相互关系。
在图6-16中,IDriver是接口,构件path.dll和接口IDriver之间是依赖关系,而构件dirver.dll和接口IDriver之间是实现关系。
图6-16 构件图用于对可运行系统建模
部署图
$\color{green}{\text{部署图}}$ 也称配置图、实施图,它可以用来显示系统中计算结点的拓扑结构和通信路径与结点上运行的软构件等。一个系统模型只有一个部署图,部署图常用于帮助理解 $\color{green}{\text{分布式系统}}$ 。
部署图由体系结构设计师、网络工程师、系统工程师等描述。图6-17所示是一个部署图的例子。
图片详情
基于UML的软件开发过程
开发过程概述
UML是独立于软件开发过程的,即UML能够在几乎任何一种软件开发过程中使用。迭代的渐进式软件开发过程包含4个阶段,即初启、细化、构建和部署。
初启
在初启阶段,软件项目的发起人确定项目的主要目标和范围,并进行初步的可行性分析和经济效益分析。
细化
细化阶段的开始标志着项目的正式确立。软件项目组在此阶段需要完成以下工作:
(1)初步的需求分析。采用UML的用例描述目标软件系统所有比较重要、比较有风险的用例,利用用例图表示参与者与用例以及用例与用例之间的关系。采用UML的类图表示目标软件系统所基于的应用领域中的概念与概念之间的关系。这些相互关联的概念构成领域模型。领域模型一方面可以帮助软件项目组理解业务背景,与业务专家进行有效沟通;另一方面,随着软件开发阶段的不断推进,领域模型将成为软件结构的主要基础。如果领域中含有明显的流程处理成分,可以考虑利用UML的活动图来刻画领域中的工作流,并标识业务流程中的并发、同步等特征。
(2)初步的高层设计。如果目标软件系统的规模比较庞大,那么经初步需求分析获得的用例和类将会非常多。此时,可以考虑根据用例、类在业务领域中的关系,或者根据业务领域中某种有意义的分类方法将整个软件系统划分为若干个包,利用UML的包图刻画这些包及其间的关系。这样,用例、用例图、类、类图将依据包的划分方法分属于不同的包,从而得到整个目标软件系统的高层结构。
(3)部分的详细设计。对于系统中某些重要的或者风险比较高的用例,可以采用交互图进一步探讨其内部实现过程。同样,对于系统中的关键类,也可以详细研究其属性和操作,并在UML类图中加以表现。因此,这里倡导的软件开发过程是根据软件元素(用例、类等)的重要性和风险程度确立优先细化原则,建议软件项目组优先考虑重要的、比较有风险的用例和类,不能将风险的识别和解决延迟到细化阶段之后。
(4)部分的原型构造。在许多情形下,针对某些复杂的用例构造可实际运行的原型是降低技术风险、让用户帮助软件项目组确认用户需求的最有效的方法。为了构造原型,需要针对用例生成详尽的交互图,对所有相关类给出明确的属性和操作定义。
综上所述,在细化阶段可能需要使用的UML语言机制包括描述用户需求的用例及用例图、表示领域概念模型的类图、表示业务流程处理的活动图、表示系统高层结构的包图和表示用例内部实现过程的交互图。
构建
在构造阶段,开发人员通过一系列的迭代完成对所有用例的软件实现工作,在每次迭代中实现一部分用例。以迭代方式实现所有用例的好处在于,用户可以及早参与对已实现用例的实际评价,并提出改进意见。这样可有效降低大型软件系统的开发风险。在实际开始构造软件系统之前,有必要预先制定迭代计划。计划的制定需遵循如下两项原则:
(1)用户认为业务价值较大的用例应优先安排。
(2)开发人员评估后认为开发风险较高的用例应优先安排。
在迭代计划中,要确定迭代次数、每次迭代所需时间以及每次迭代中应完成(或部分完成)的用例。
每次迭代过程由针对用例的分析、设计、编码、测试和集成5个子阶段构成。在集成之后,用户可以对用例的实现效果进行评价,并提出修改意见。这些修改意见可以在本次迭代过程中立即实现,也可以在下次迭代中再予以考虑。
构建过程中,需要使用UML的交互图来设计用例的实现方法。为了与设计得出的交互图协调一致,需要修改或精化在细化阶段绘制的作为领域模型的类图,增加一些为软件实现所必需的类、类的属性或方法。
在构建阶段的每次迭代过程中,可以对细化阶段绘出的包图进行修改或精化,以便包图切实反映目标软件系统最顶层的结构划分状况。
综上所述,在构建阶段可能需要使用的UML语言机制包括:
(1) $\color{green}{\text{用例及用例图}}$ 。它们是开发人员在构造阶段进行分析和设计的基础。
(2) $\color{green}{\text{类图}}$ 。在领域概念模型的基础上引进为软件实现所必需的类、属性和方法。
(3) $\color{green}{\text{交互图}}$ 。表示针对用例设计的软件实现方法。
(4) $\color{green}{\text{状态图}}$ 。表示类的对象的状态—事件—响应行为。
(5) $\color{green}{\text{活动图}}$ 。表示复杂的算法过程,尤其是过程中的并发和同步。
(6) $\color{green}{\text{包图}}$ 。表示目标软件系统的顶层结构。
(7) $\color{green}{\text{构件图}}$ 。
(8) $\color{green}{\text{部署图}}$ 。
部署
在部署阶段,开发人员将构造阶段获得的软件系统在用户实际工作环境(或接近实际的模拟环境)中试运行,根据用户的修改意见进行少量调整。
基于UML的需求分析
在初步的业务需求描述已经形成的前提下,基于UML的需求分析过程(见图6-18)大致可分为以下步骤。
- 利用用例及用例图表示需求。从业务需求描述出发获取执行者和场景;对场景进行汇总、分类、抽象,形成用例;确定执行者与用例、用例与用例图之间的关系,生成用例图。
图6-18 需求分析过程
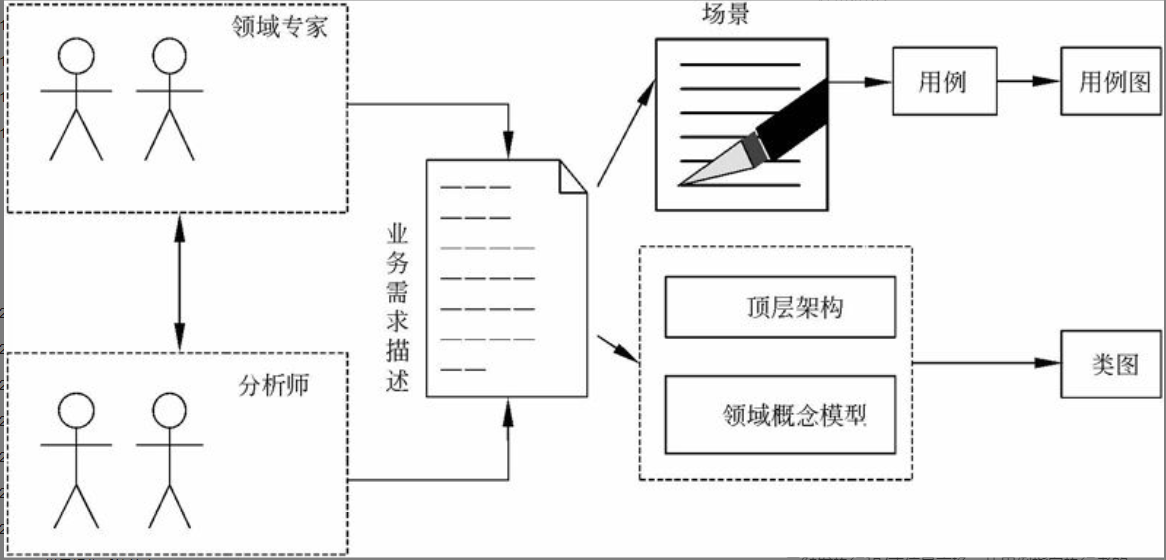
- 利用包图及类图表示目标软件系统的总体框架结构。根据领域知识、业务需求描述和既往经验设计目标软件系统的顶层架构;从业务需求描述中提取“关键概念”,形成领域概念模型;从概念模型和用例出发,研究系统中主要的类之间的关系,生成类图。
上述两个步骤并没有时序关系,它们可以并行展开。
生成用例
从外部用户的视角看,一个用例是执行者(actor)与目标软件系统之间的一次典型的交互作用。从软件系统内部的视角出发,一个用例代表系统执行的一系列动作,动作执行的结果能够被外部的执行者所察觉。执行者是指外部用户或外部实体在系统中扮演的角色。如果多个用户在使用目标软件系统时扮演同一角色,这些用户将由单一执行者表示。反之,如果一个用户扮演多种角色,则需要用多个执行者来表示同一用户。
对用例的完整描述包括用例名称、参与执行者、前置条件、一个主事件流、零到多个辅事件流和后置条件。主事件流表示正常情况下执行者与系统之间的信息交互及动作序列,辅事件流则表示特殊情况或异常情况下的信息交互及动作序列。显式地分隔主、辅事件流是为了使分析人员首先聚焦于正常的业务处理流程,同时也便于用例的读者理解业务需求。
用例主要来源于分析人员对场景的分类和抽象,即将相似的场景进行归并,使一个用例可以通过实例化和参数调节而涵盖多个场景。
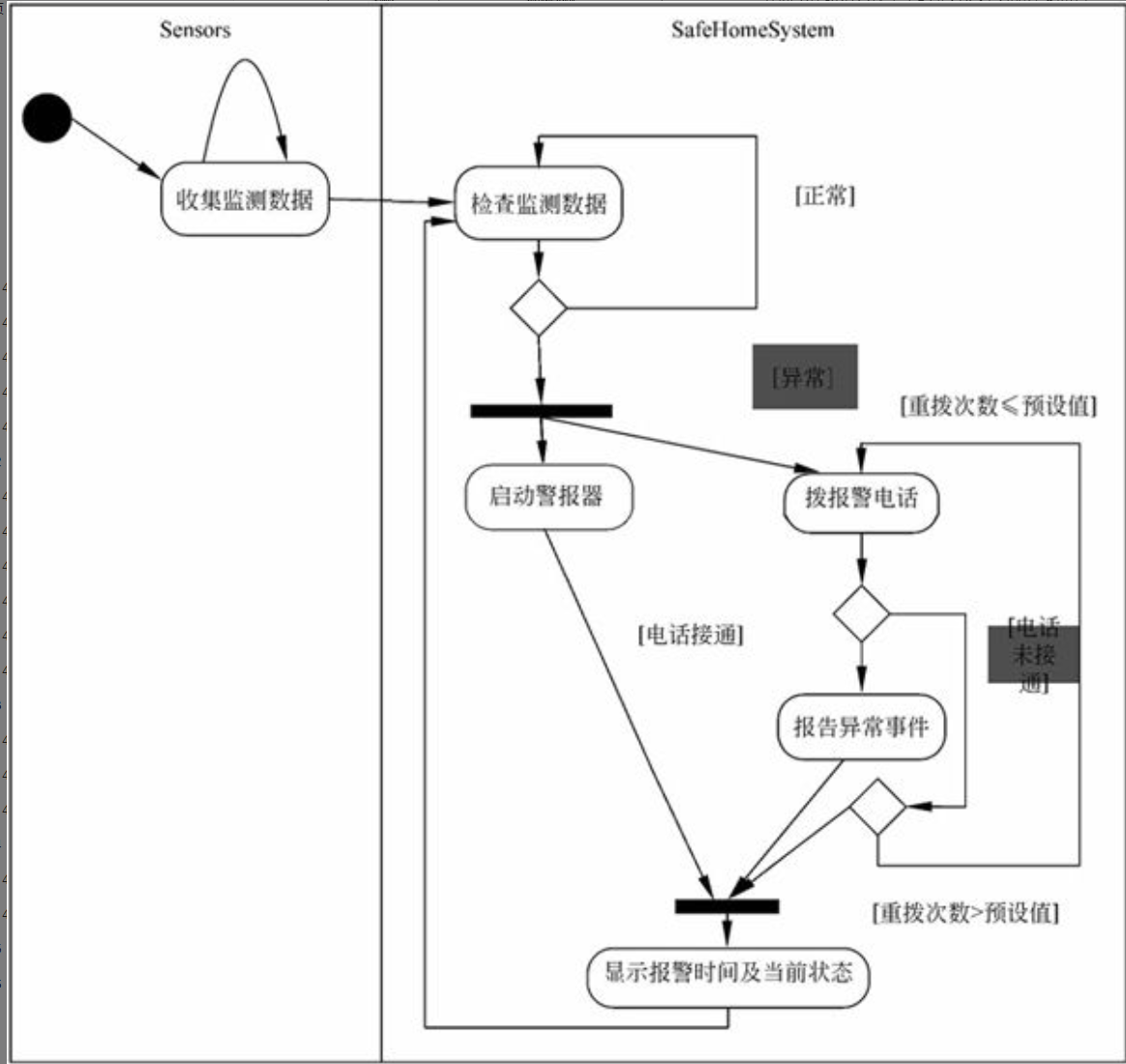
例如,在“家庭保安系统”中,执行者有“用户”、“传感器”、“警报器”、“报警电话”和“显示器”,用例有“系统配置”、“命令响应”和“传感器监测”。下面以“传感器监测”为例说明用例的一般描述格式。
用例名称:传感器监测。
参与执行者:各类传感器、警报器、报警电话和显示器。
前置条件:系统已开机。
主事件流:
①传感器向目标软件系统上报其监测数据,系统判别监测数据是否正常。
②如果不正常,系统启动警报器,拨报警电话号码。
③报警电话接通后,软件系统播出语音,报告异常事件发生的时间、地点和事件的性质。
④系统在控制面板的显示器上显示报警时间及当前状态(报警)。
辅事件流:
①如果报警电话无人接听,则按照重拨延迟反复拨号,直至电话接通,再转入主事件流的步骤③。
②如果重拨次数达到系统预设的最大次数,电话仍无人接听,则跳过主事件流的步骤③,转入步骤④。
后置条件:如果已发现异常的监测数据,系统处于“报警”状态;否则,系统处于正常的“监测”状态。
用活动图表示用例
针对前面所述的“传感器监测”用例,其活动图表示如图6-19所示。
活动图
生成用例图
执行者与用例之间的关系有两种:触发执行与信息交换。执行者与用例之间可能兼具这两种关系,例如,在“家庭保安系统”中,执行者“用户”在触发用例“命令响应”的同时,还要向用例传送命令信息。
在UML用例图中,从执行者指向用例的边表示触发执行和/或信息交换,从用例指向执行者的边则表示用例将其生成的信息传递给执行者。例如图6-19中的“传感器监测”用例仅包含正常的处理流程,而“报警电话未接通”用例除正常流程外还增加了“重复拨号”以及“重拨次数达到最大次数仍无人接听”这两种异常处理动作。
建立顶层架构
顶层架构的主要目的是为后续的分析和设计活动建立一种结构和分划,以便开发人员在不同的开发阶段,以及同一开发阶段的不同开发人员,能够聚焦于系统的不同部分。顶层架构是分析和设计的阶段成果的承载体。随着开发过程的推进,框架中的内容不断丰富、翔实,最终演进为完整的面向对象软件结构。
UML包图
包是UML对类进行分组的一种机制。可以从某种视角将具有比较密切的关联的一些类划分为一个包,分属于不同包的两个类之间的关联则比较松散。由此可见,对于大型软件系统而言,包的划分是实现“分而治之”的重要技术手段。
包之间存在两种依赖关系:依赖和构成。如果对类A的修改将导致类B的改变,则称B依赖于A。如果两个包中存在具有依赖关系的两个类,则认为这两个类分属的包之间存在依赖关系。
顶层架构设计
软件系统顶层架构的基本方法是,结合实际需求,从既往的架构设计经验模式中选取适当者,再进行微调或局部改造。目前有如下几种主要的架构模式:
(1)流程处理模式。流程处理系统以算法和数据结构为中心,其系统功能由一系列的处理步骤构成,相邻的处理步骤之间以数据流通管道相互连接。
(2)客户/服务器模式。客户端负责用户输入和处理结果的呈现,服务器端则负责后台的业务逻辑处理。
- 模型——视图——控制器(Model、View、Controller, MVC)模式。该模式将整个软件系统划分为模型、视图和控制器三个部分。模型负责维护并保存具有持久性的业务数据,实现业务处理功能,并将业务数据的变化情况及时通知视图;视图负责呈现模型中包含的业务数据,响应模型变化通知,更新呈现形式,并向控制器传递用户的界面动作;控制器负责将用户的界面动作映射为模型中的业务处理功能并实际调用之,然后根据模型返回的业务处理结果选择新的视图。MVC模式特别适合于分布式应用软件,尤其是Web应用系统。
- 分层模式。分层模式将整个软件系统分为若干层次,最顶层直接面向用户提供软件系统的操作界面,其余各层为紧邻其上的层次提供服务。分层模式可以有效地降低软件系统的耦合度,因此其应用十分普遍。
事实上,大型软件的顶层架构往往需要复合使用多种架构样式。例如,整个目标软件系统采用分层结构,在系统的不同层次内再分别使用适宜的其他种类的架构模式。
在确立顶层架构的过程中需综合考虑以下因素:
- 架构中包的数量。原则上,如果母个包中包含的软件元素(例如类)的数量过多,应考虑将其进一步细分;如果过少,则说明架构过早地陷入了细节,架构划分返工的可能性较大,同时也不合理地限制了后续分析和设计活动的自由空间。
- 架构中包之间的耦合度。包之间的依赖关系和连接关系应尽量简单、稀疏。
- 软件系统的稳定性。要尽量抽取不稳定的软件元素之中相对稳定的部分,将不稳引起的软件元素分类聚集于少数几个包中,以提高软件系统的可维护性。
- 软件系统的必然性。可以将可选功能和必须实现的功能分置于架构中不同的包或子包之中。
- 作为软件系统运行环境的物理网络拓扑。根据软件元素在分布环境中的部署情况。区分顶层架构中的包,可以使包之间的消息传递与物理节点之间的通信相吻合,使后续的分析和设计活动受益于顶层架构中明确定义的通信关系。
- 软件元素的安全、保密级别。根据安全访问的权限划分顶层架构中的包或者子包。
- 开发团队的技术专长。根据开发人员在问题领域和软件技术领域不同的专长划分顶层架构中的包,使每个包都能分配给最适合的开发人员进行后续的分析、设计、编码和测试等,从而有利于并行开发。
建立概念模型
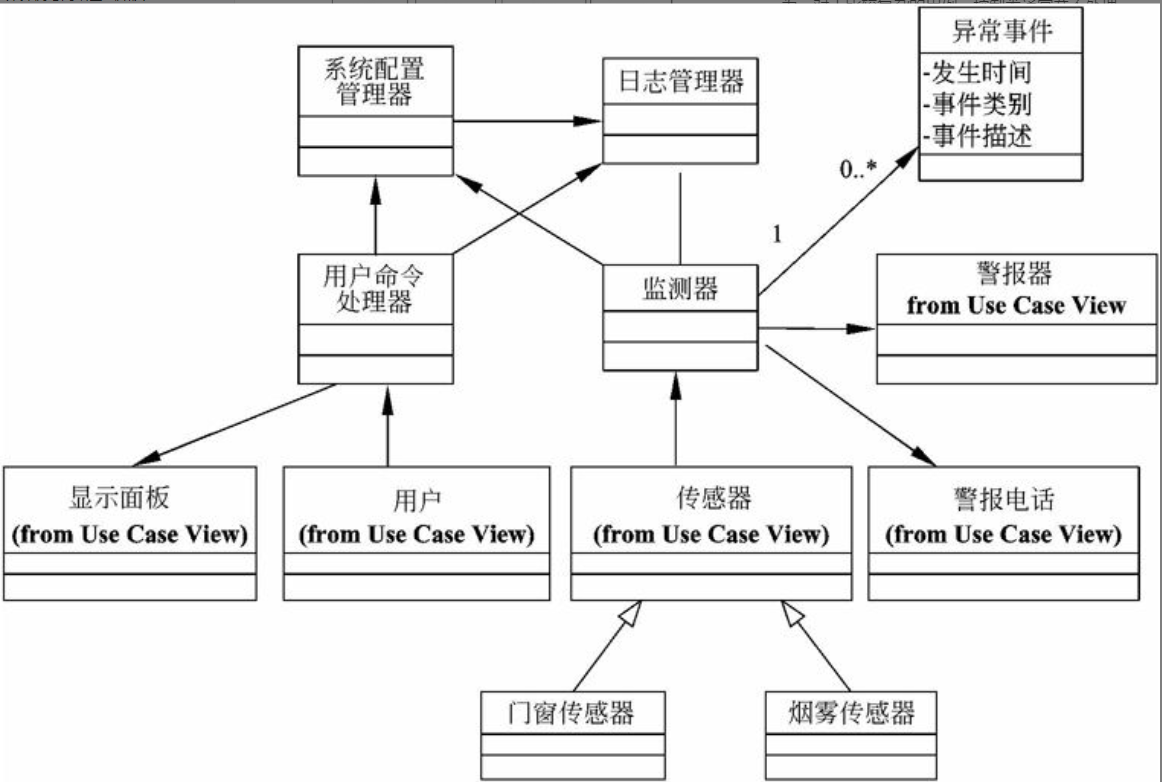
例如,“家庭保安系统”的领域概念模型如图6-20所示。
图6-20 “家庭保安系统”的领域概念模型
面向对象的设计方法
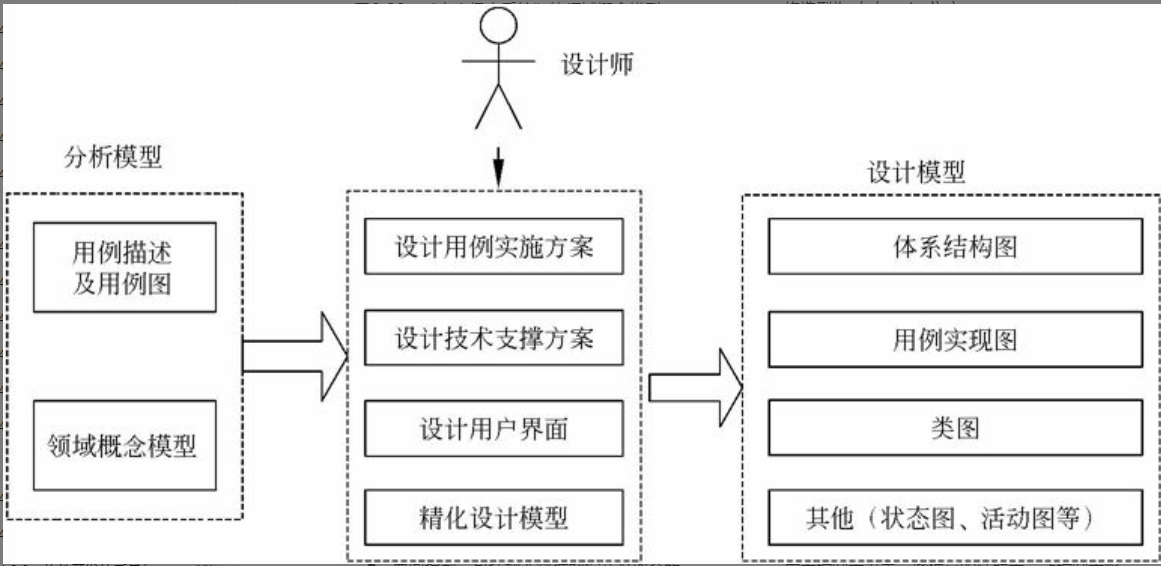
面向对象的软件设计过程如图6-21所示。
图6-21 面向对象的软件设计过程
设计用例实现方案
UML的交互图(顺序图、协作图)适于用例实现方案的表示。该设计方法包含如下三个步骤:
提取边界类、实体类和控制类
边界类用于描述目标软件系统与外部环境之间的交互,并负责实现如下功能:
- 界面控制。包括输入数据的格式及内容转换、输出结果的呈现以及软件运行过程中界面的变化写切换等。
- 外部接口。实现目标软件系统与外部系统或外部设备之间的信息交流和互操作。主要关注跨越目标软件系统边界的通信协议。
- 环境隔离。将目标软件系统与操作系统、数据库管理系统、应用服务器中间件等境软件进行交互的功能与特性封装于边界类之中,使目标软件系统的其余部分尽可能地独立于环境软件。
在UML类图中,边界类往往附加UML构造型〈〈boundary〉〉作为特别标识。
实体类表示目标软件系统中具有持久意义的信息项及其操作。实体类的操作具有“内向收敛”特征,它们仅向目标软件系统的其余部分提供读/写信息项内容的必要的操作接口,并不涉及业务逻辑处理。实体类的UML构造型为〈〈entity〉〉。
控制类作为完成用例任务的责任承担者,协调、控制其他类共同完成用例规定的功能或行为。对于比较复杂的用例,控制类通常并不处理具体的任务细节,但是它应知道如何分解任务,如何将子任务分派给适当的辅助类,以及如何在辅助类之间进行消息传递和协调。控制类的UML构造型为〈〈control〉〉。
通常情况下,执行者与用例之间的一种通信连接对应一个边界类。但是,如果两个以上的用例与同一执行者交互,并且这些交互具有共同的行为、完成相同或类似的任务,就可以考虑用同一边界类实现用例与执行者之间的交互。这就意味着边界类的作用范围可以超越单个用例。
构造交互图
UML交互图,以交互图作为用例的精确实现方案。
如前所述,用例描述中已包含事件流说明。事件流中的事件应直接对应于交互图中的消息,而事件间的先后关系体现为交互图中的时序,对消息的响应则构成消息接收者的职责。这种职责在后续的设计活动中将被确立为类的方法。
对于比较复杂的用例而言,仅仅依靠控制类、边界类和实体类并不能很好地解决问题,因为我们不能使单个控制类过于庞大和复杂,让它既承担控制、协调的任务,又承担复杂的计算任务。因此,在设计复杂用例的实施方案时,应考虑为控制类设置一些独立的辅助类,让控制类将一些任务委托给辅助类完成。例如,在图6-20所示的“家庭保安系统”类图中,“系统配置管理器”和“日志管理器”就是这种意义上的辅助类。
在UML顺序图中,用例的主动执行者应位于最左侧,紧邻其右的类是作为用户界面的边界类,再往右是控制类。控制类的右侧应放置辅助类和实体类,它们的右侧是作为外部接口和环境隔离层的边界类,最右侧是位于目标软件系统边界之外的被动执行者。如此布局之后,在顺序图中不应该出现穿越控制类生命线的消息,即主动执行者向边界类发出命令,边界类将命令进行适当转换后传送至控制类,控制类通过消息请求辅助类、实体类的帮助,协调、控制它们共同完成来自主动执行者的命令。在此过程中,控制类或辅助类可以向右侧的边界类发送消息,将信息或外部处理请求由边界类传向外部系统(被动执行者)。按照上述布局规则绘制的典型的顺序图如图6-22所示。
图6-22 典型布局规则下顺序图
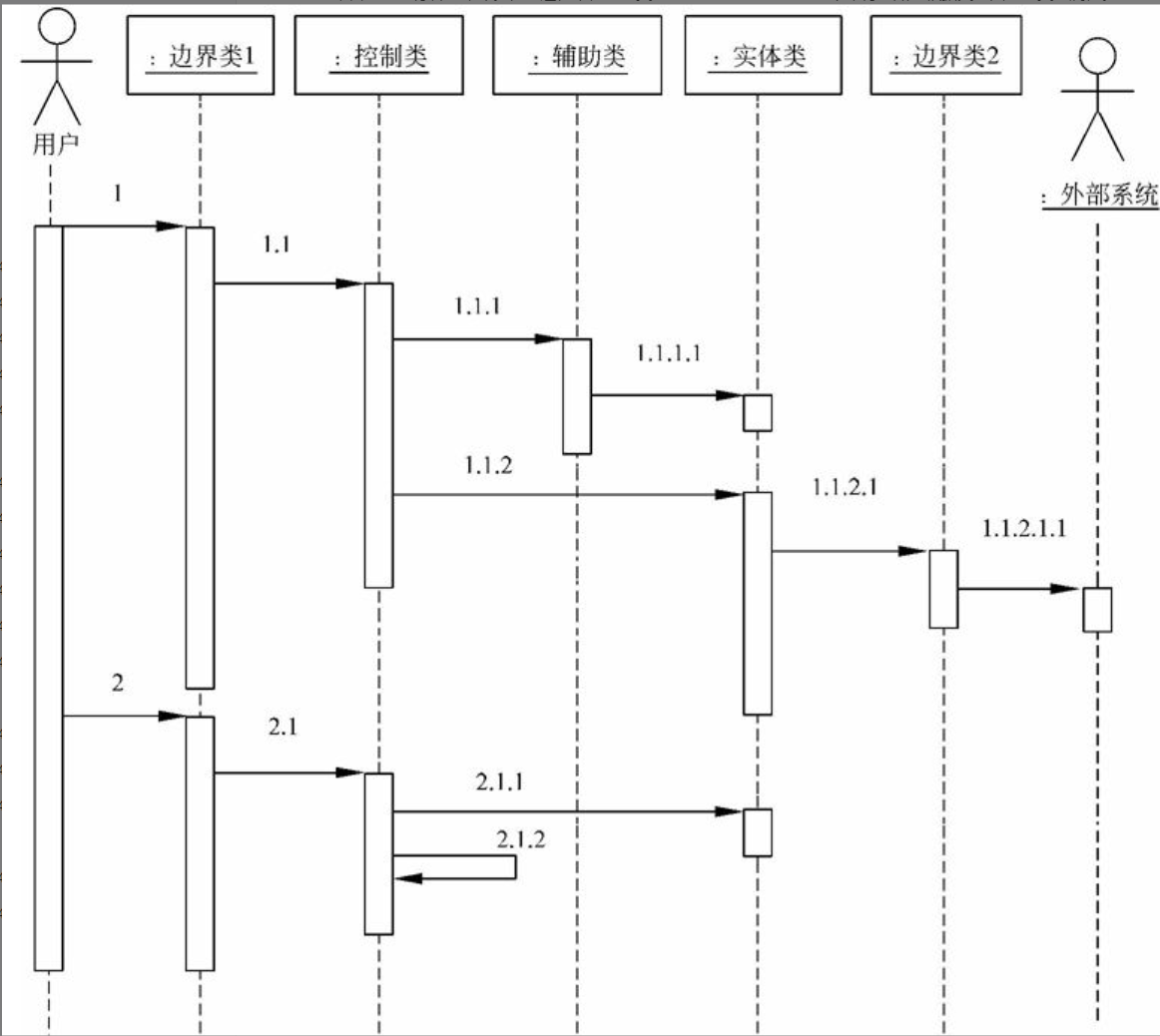
在用例描述中,许多用例除主事件流外,往往还包含备选事件流,以说明在某些特殊或异常情况下的事件和响应动作序列。为易于理解,在设计模型中应该用分离的UML交互图分别表示事件流和每个备选事件流。
(3)根据交互图精化类图。
在UML交互图中,对每个类的对象都规定了它必须响应的消息以及类的对象之间的消息传递通道。前者对应于类的操作,后者则对应于类之间的连接关系。因此,可以利用交互图精化分析模型中的类图,将交互图中出现的新类添加到原有类图中,并且对相关的类进行精化,定义其属性和操作。
原则上,每个类都应该有一个操作来响应交互图中指向其对象的那条消息。但是,这并不意味着消息与操作一定会一一对应,因为类的一个操作可能具有响应多条消息的能力。同理,两个类之间的一条连接关系也可以为多条消息提供传递通道。为了简化设计模型,也为了提高重用程度,设计人员应该尽量使用已有的操作来响应新消息,并尽量使用已存在的连接路径作为消息传递的通道。如果两个类之间存在明确、自然的聚合或组合关系,则可以在类图中直接用相应的UML图元符号表示类间的聚合或组成关系,这两个关系均可提供消息传递通道。
接下来讨论如何根据交互图确立类的属性。类的操作完成消息响应责任的能力来源于两方面的知识,一是类本身具有的信息,即类的属性;二是类能够找到的其他类,通过其他类协助其完成消息响应。在综合考虑这两个因素之后,类的操作应该明确哪些子任务可通过消息传递路径委托给其他类完成,哪些子任务必须由自身完成。根据后一种子任务的需要,结合领域和业务知识即可推导出类应具有的属性。
设计技术支撑方案
在许多软件项目中,应用功能往往都需要一组技术支撑机制为其提供服务。例如,对分布式应用软件(包括电子商务应用、企业ERP系统等)而言,需要数据持久存储服务、安全控制服务、分布式事务管理服务、并发与同步控制服务和可靠消息服务等。这些技术支撑设施并非业务需求的直接组成部分,但形态各异的业务处理功能全都依赖于它们提供的公共技术服务。让每个业务功能的设计者直接面对裸机、基本操作系统或基本网络环境来完成软件实现方案是不可思议的。
技术支撑方案应该为多个用例的软件实现提供技术服务,所以,它应该成为整个目标软件系统中全局性的公共技术平台。当用户需求发生变化时,技术支撑方案应具有良好的稳定性。这就要求软件设计者选用开放性和可扩充性较好的技术支撑方案。如果目标软件系统的顶层架构采用分层方式,那么技术支撑方案应该位于层次结构中的较低层次。
技术支撑方案的设计一方面取决于目标软件系统对公共技术服务的需求,另一方面取决于设计人员对软件技术手段的把握和选取。
设计用户界面
用户界面设计的策略与步骤如下:
(1)熟悉用户并对用户分类。设计人员应深入用户环境,考虑用户需要完成的任务、完成这些任务需要什么工具支持以及这些工具对用户是否适用。事实上,不同类型的用户要求也不同,一般可按技术熟练程度、工作性质和访问权限对用户进行分类,以便尽量照顾到所有用户的合理要求,并优先满足某些特权用户。
2)按用户类别分析用户的工作流程与习惯。在用户分类的基础上,从每类中选取一个用户代表,建立包括下列内容的调查表,并通过对调查结果的分析判断用户对操作界面的需求和喜好。
- 姓名。
- 期望软件用途。
- 特征(如年龄、文化程度、限制等)。
- 主要要求与喜好。
- 技术熟练程度。
- 任务客观场景描述。
(3)设计命令系统并进行优化。在设计一个新命令系统时,应尽量遵循用户界面的一般原则和规范,必要时可参考一些优秀的商品软件。根据用户分析结果确定初步的命令系统,然后再优化。命令系统既可为若干菜单、菜单栏,也可为一组按钮。优化命令系统时首先应考虑命令的顺序,一般常用命令居先,命令的顺序与用户工作习惯保持一致;其次,根据外部服务之间的聚合关系组织相应的命令,总体功能对应父命令,部分功能对应子命令;然后,充分考虑人类记忆的局限性(即所谓“7 12”原则或“3×3”原则),命令系统最好组织为一棵两层的多叉树;最后,应尽可能减少用户完成一个操作所需的动作(如单击鼠标、拖曳鼠标和敲击键盘等),并为熟练用户提供操作的快捷方式。
(4)设计用户界面的各种细节。此步骤包括设计一致的用户界面风格、耗时操作的状态反馈、undo机制、帮助用户记忆的操作序列和自封闭的集成环境等。
(5)增加用户界面专用的类与对象。用户界面专用类的设计与所选用的图形用户界面(GUI)工具或者支持环境有关。一般而言,需要为窗口、菜单、对话框等界面元素定义相应的类,这些类往往继承自GUI工具或者支持环境提供的类库中的父类。最后,还需要针对每个与用户命令处理相关的界面类,定义控制设计模型中的其他类的方法。
利用快速原型演示,改进界面设计。为人机交互部分构造原型,是界面设计的基本技术之一。为用户演示界面原型,让他们直观感受目标软件系统的使用方法,并评判系统是否功能齐全、方便好用。
精化设计模型
对模型进行改进的活动可以分为$\color{green}{\text{精化}}$和$\color{green}{\text{合并}}$两种,一般先从精化开始。首先,由于初始架构模型已经包括了总原则和层结构两部分的内容。现在要做的工作是根据需求和架构原则来划分不同的粗粒度组件。粗粒度组件来源于分析活动中的业务实体。把具有很强相关性业务实体组合起来,形成一个集合。集合内部存在错综复杂的关系,同时集合向外部提供服务接口。这样的集合就称为粗粒度组件。粗粒度组件对外的接口和内部的实现是相区分的。粗粒度组件的形式有很多,Java平台上的Jar文件、Windows平台上的dll文件,甚至古老的。或a文件都可以是粗粒度组件的表现形式。设计优秀的粗粒度组件应该只是完成一项功能,这一点是它与子系统的主要区分。一个系统中可能包括会计子系统、库存管理子系统。但是提供会计粗粒度组件或是库存管理粗粒度组件是没有什么意义的。因为这样的粗粒度组件的范围过于广泛,难以发挥重用的价值。粗粒度组件是可以(可能也是必须)跨越层次的。粗粒度组件拥有持久化的行为,拥有业务逻辑,需要表示层的支持。这样看起来,它所属的轴向和层次的轴向是相互垂直的。粗粒度组件来源于需求。需求阶段产生的需求说明书或是用例模型将是粗粒度组件开发的基础。在拥有了需求工件之后,我们需要对需求进行功能性的划分,将需求分为几个功能组,这样我们基本上就可以得到相应的粗粒度组件了。如果系统比较庞大,可以对功能组再做细分。这取决于粗粒度组件的范围。过小的范围,将会造成粗粒度组件不容易使用,用户需要理解不同的粗粒度组件之间的复杂关系,最后的结果也将包含大量的组件和复杂的逻辑。过大的范围,则会造成粗粒度组件难以重用,导致粗粒度组件称为一个子系统。
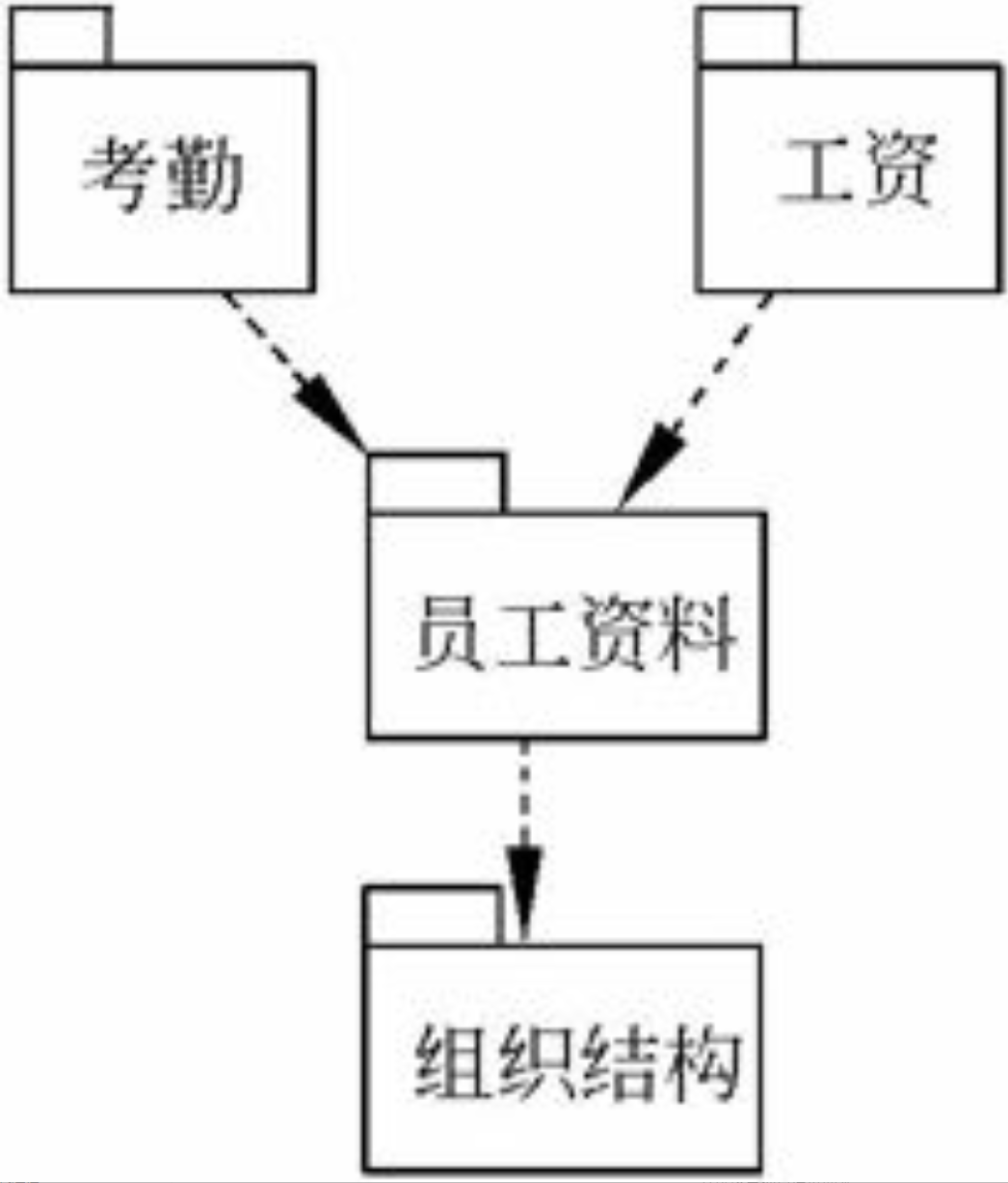
假设需要开发一个人力资源管理系统。经过整理,它的需求大致分为如下几个部分。
- 组织结构的设计和管理:包括员工职务管理和员工所属部门的管理。
- 员工资料的管理:包括员工的基本资料和简单的考评资料。
- 日常事务的管理:包括了对员工的考勤管理和工资发放管理。
对于前两项的功能组,建立粗粒度组件是比较合适的。但是对于第三项功能组,由于范围过大,将之分为考勤管理和工资管理。现在我们得到了4个粗粒度组件。分别是组织结构组件、员工资料组件、员工考勤组件和员工工资组件。
在得到了粗粒度组件之后,下面的工作分为两个部分:第一个部分是定义不同的粗粒度组件之间的关系。第二个部分是在粗粒度组件的基础上定义业务实体或是定义细粒度组件。
不同的粗粒度组件之间的关系其实就是前文提到的粗粒度组件的外部接口。如果可能,在粗粒度组件之间定义单向的关联(如上图所示)可以有效的减少组件之间的耦合。如果必须要定义双向的关联,请确保关联双方组件之间的一致性。在图6-23中,我们可以清晰的看出,组织结构处于最底层,员工资料依赖于组织结构,包括从组织结构中获得员工的所属部门,以及员工职务等信息。而对于考勤、工资组件来说,需要从员工资料中获取必要的信息,也包括了部门和职务两方面的信息。这里有两种关联定义的方法,一种是让考勤组件从组织结构组件中获得部门和职务信息,从员工资料中获得另外的信息,另一种是如图6-23一样,考勤组件只从员工资料组件中获得信息,而员工资料组件再使用委托,从组织结构中获得部门和职务的信息。第二种做法的好处是向考勤、工资组件屏蔽了组织结构组件的存在,并保持了信息获取的一致性。这里演示的只是组件之间的简单关系,现实中的关系不可能如此的简单,但是处理的基本思路是一样的,就是尽可能简化组件之间的关系,从而减少它们之间的耦合度。
图片详情
在得到了粗粒度组件模型之后,我们需要对其进行进一步的分析,以得到细粒度的组件。细粒度的组件具有更好的重用性,并使得架构设计的精化工作更进一步。按Jacobson推荐的面向对象软件工程(Object Oriented Software Enginerring, OOSE)的做法,我们需要从软件的目标领域中识别出关键性的实体,或者说是领域中的名词。例如上例中的员工、部门、工资等。然后决定它们应该归属于哪些粗粒度组件。先识别细粒度组件还是先识别粗粒度组件并没有固定的顺序。
最初得到的组件模型可能并不完善,需要对其进行修改。可能某个组件中的类太多了,过于复杂,就需要对其进一步精化、分为更细的组件,也许某个组件中的类太少了,需要和其他的组件进行合并。也许你会发现某两个组件之间存在重复的要素,可以从中抽取出共性的部分,形成新的组件。组件分析的过程并没有一种标准的做法,你只能够根据具体的案例来进行分析。
最后的模型将会明确的包含几个经过精化之后的粗粒度组件。粗粒度组件之间的关系也会进行一次重新定义。
系统架构文档化
模型概述
软件架构用来处理软件高层次结构的设计和实施。它以精心选择的形式将若干结构元素进行装配,从而满足系统主要功能和性能需求,并满足其他非功能性需求,如可靠性、可伸缩性、可移植性和可用性。Perry和Wolfe使用一个精确的公式来表达,该公式由Boehm做了进一步修改。
$\color{green}{\text{软件架构}}$={元素,形式,关系/约束}
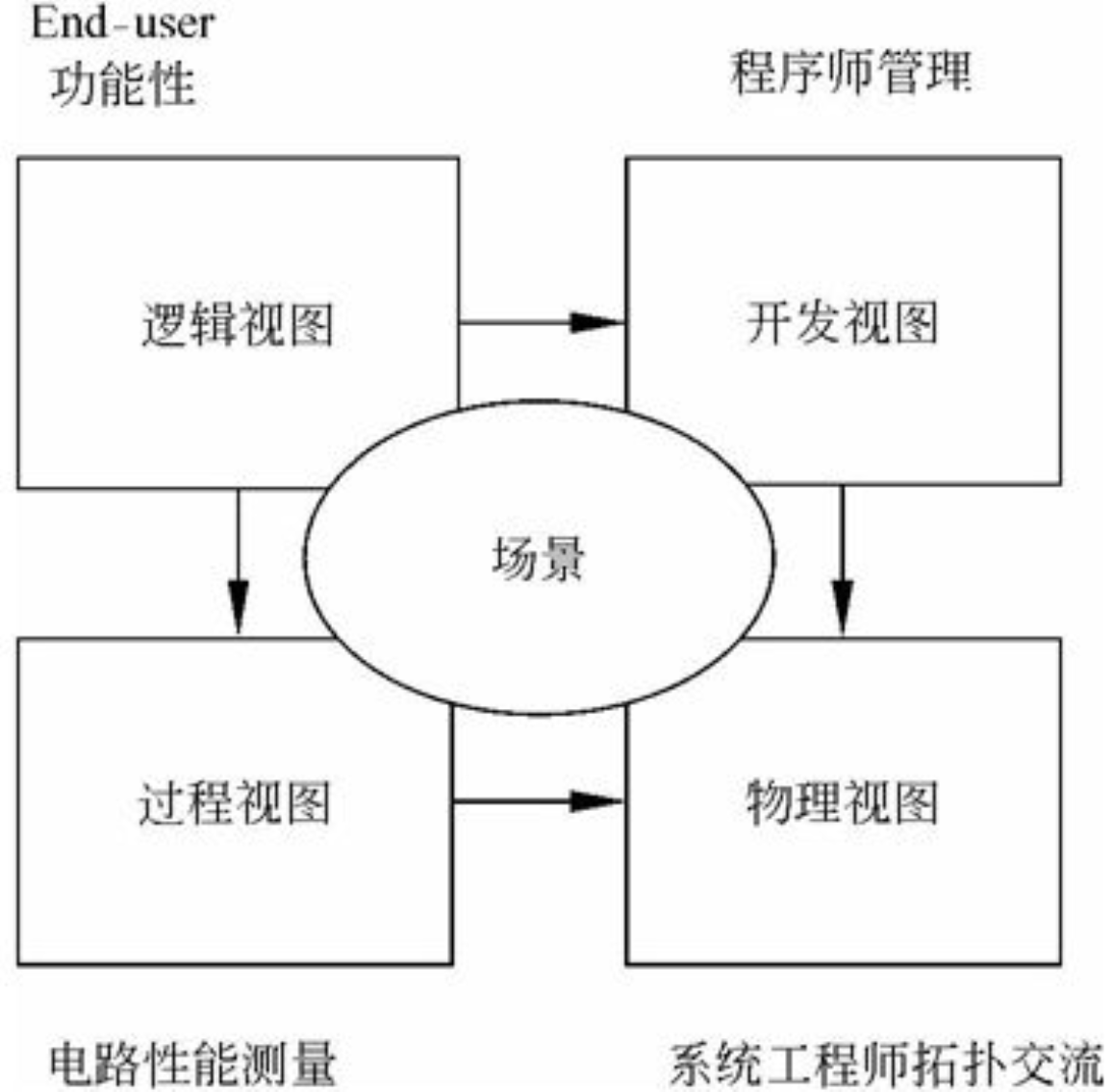
软件架构涉及到抽象、分解和组合、风格和美学。我们用由多个视图或视角组成的模型来描述它。为了最终处理大型的、富有挑战性的架构,该模型包含5个主要的视图如图6-24所示。
- 逻辑视图(logical view),设计的对象模型(使用面向对象的设计方法时)。
- 过程视图(process view),捕捉设计的并发和同步特征。
- 物理视图(physical view),描述了软件到硬件的映射,反映了分布式特性。
- 开发视图(development view),描述了在开发环境中软件的静态组织结构。
架构的描述,即所做的各种决定,可以围绕着这4个视图来组织,然后由一些用例(use cases)或场景(scenarios)来说明,从而形成了第5个视图。正如将看到的,实际上软件架构部分从这些场景演进而来。
图6-24 Rational“4+1”视图模型
我们在每个视图上均独立地应用Perry & Wolf的公式,即定义一个所使用的元素集合(组件、容器、连接符),捕获工作形式和模式,并且捕获关系及约束,将架构与某些需求连接起来。每种视图使用自身所特有的表示法——蓝图(blueprint)来描述,并且架构师可以对每种视图选用特定的架构风格(architectural style),从而允许系统中多种风格并存。
“4+1”视图模型具有相当的“普遍性”,因此可以使用其他的标注方法和工具,也可以采用其他的设计方法,特别是对于逻辑和过程的分解。
逻辑结构
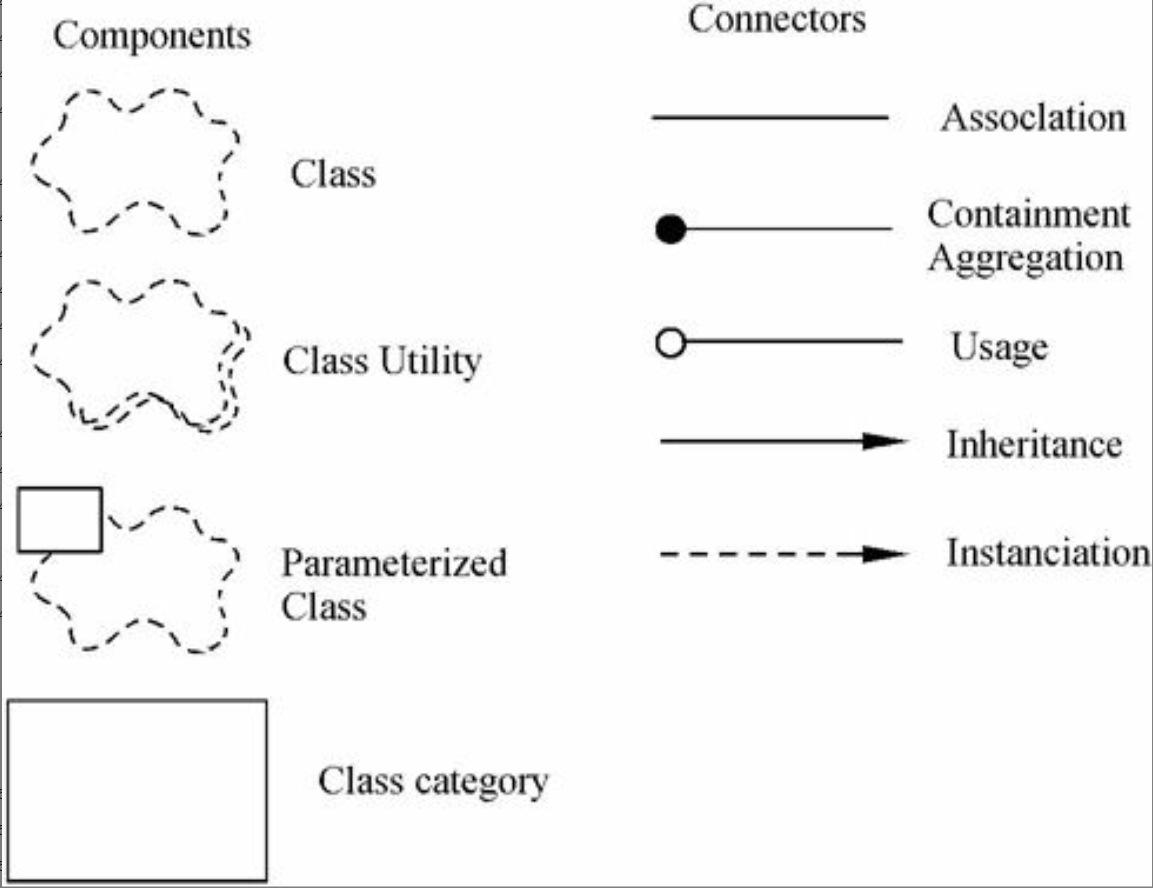
逻辑架构主要支持功能性需求,即在为用户提供服务方面系统所应该提供的功能。系统分解为一系列的关键抽象,(大多数)来自于问题域,表现为对象或对象类的形式。它们采用抽象、封装和继承的原理。分解并不仅仅是为了功能分析,而且用来识别遍布系统各个部分的通用机制和设计元素。我们使用Rational/Booch方法来表示逻辑架构,借助于类图和类模板的手段。类图用来显示一个类的集合和它们的逻辑关系:关联、使用、组合、继承等。相似的类可以划分成类集合,基本的逻辑蓝图表示法如图6-25所示。类模板关注于单个类,它们强调主要的类操作,并且识别关键的对象特征。如果需要定义对象的内部行为,则使用状态转换图或状态图来完成。公共机制或服务可以在类功能(class utilities)中定义。对于数据驱动程度高的应用程序,可以使用其他形式的逻辑视图,例如E-R图,来代替面向对象的方法。
逻辑视图的表示法来自Booch标记法。当仅考虑具有架构意义的条目时,这种表示法相当简单。特别是在这种设计级别上,大量的修饰作用不大。我们使用Rational Rose来支持逻辑架构的设计。
图6-25 逻辑蓝图的表示法
逻辑视图的风格
逻辑视图的风格采用面向对象的风格,其主要的设计准则是试图在整个系统中保持单一的、一致的对象模型,避免就每个场合或过程产生草率的类和机制的技术说明。
逻辑结构蓝图的样例
图6-26显示了Télic PABX架构中主要的类。
Télic PABX架构中主要的类
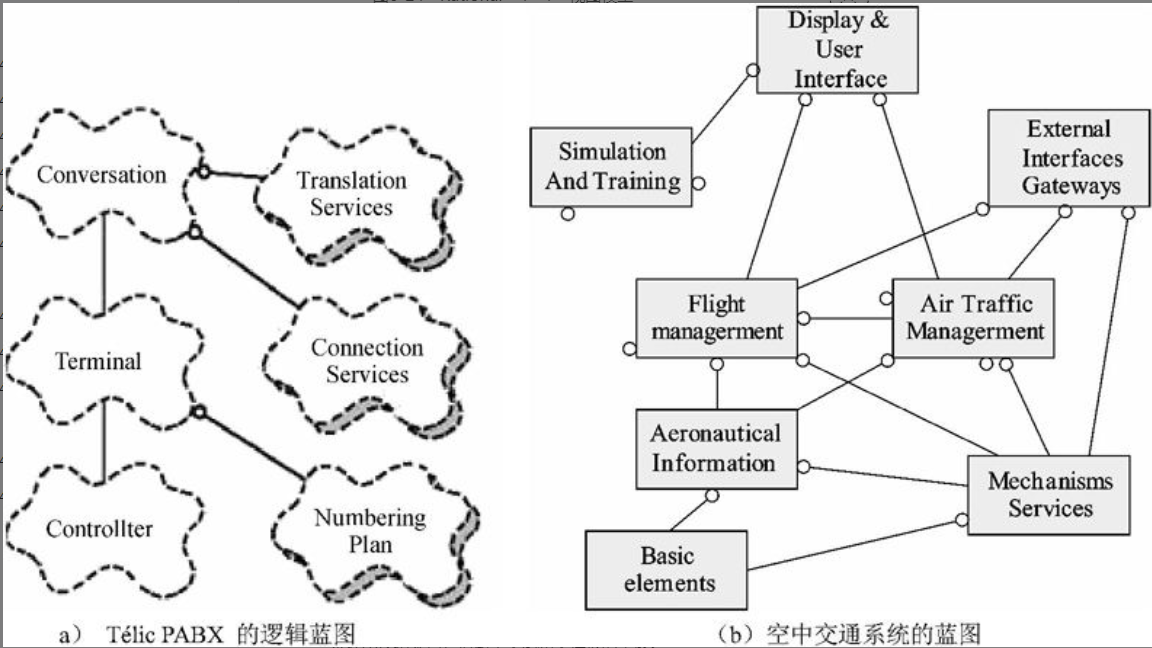
对于一个包含了大量的具有架构重要意义的类的、更大的系统来说,图6-26(b)描述了空中交通管理系统的顶层类图,包含8个类的种类(例如,类的分组)。
进程架构
进程架构考虑一些非功能性的需求,如性能和可用性。它解决并发性、分布性、系统完整性、容错性的问题,以及逻辑视图的主要抽象如何与进程结构相配合在一起——即在哪个控制线程上,对象的操作被实际执行。
进程架构可以在几种层次的抽象上进行描述,每个层次针对不同的问题。在最高的层次上,进程架构可以视为一组独立执行的通信程序(叫作“processes”)的逻辑网络,它们分布在整个一组硬件资源上,这些资源通过LAN或者WAN连接起来。多个逻辑网络可能同时并存,共享相同的物理资源。例如,独立的逻辑网络可能用于支持离线系统与在线系统的分离,或者支持软件的模拟版本和测试版本的共存。
进程是构成可执行单元任务的分组。进程代表了可以进行策略控制过程架构的层次(即开始、恢复、重新配置及关闭)。另外,进程可以就处理负载的分布式增强或可用性的提高而不断地被重复。
接着,我们可以区别主要任务、次要任务。主要任务是可以唯一处理的架构元素;次要任务是由于实施原因而引入的局部附加任务(如周期性活动、缓冲、暂停等)。它们可以作为Ada Task或轻量线程来实施。主要任务的通讯途径是良好定义的交互任务通信机制:基于消息的同步或异步通信服务、远程过程调用、事件广播等。次要任务则以会见或共享内存来通信。在同一过程或处理节点上,主要任务不应对它们的分配做出任何假定。
消息流、过程负载可以基于过程蓝图来进行评估,同样可以使用哑负载来实现“中空”的进程架构,并测量在目标系统上的性能。正如Filarey etal在他的Eurocontrol实验中描述的那样。
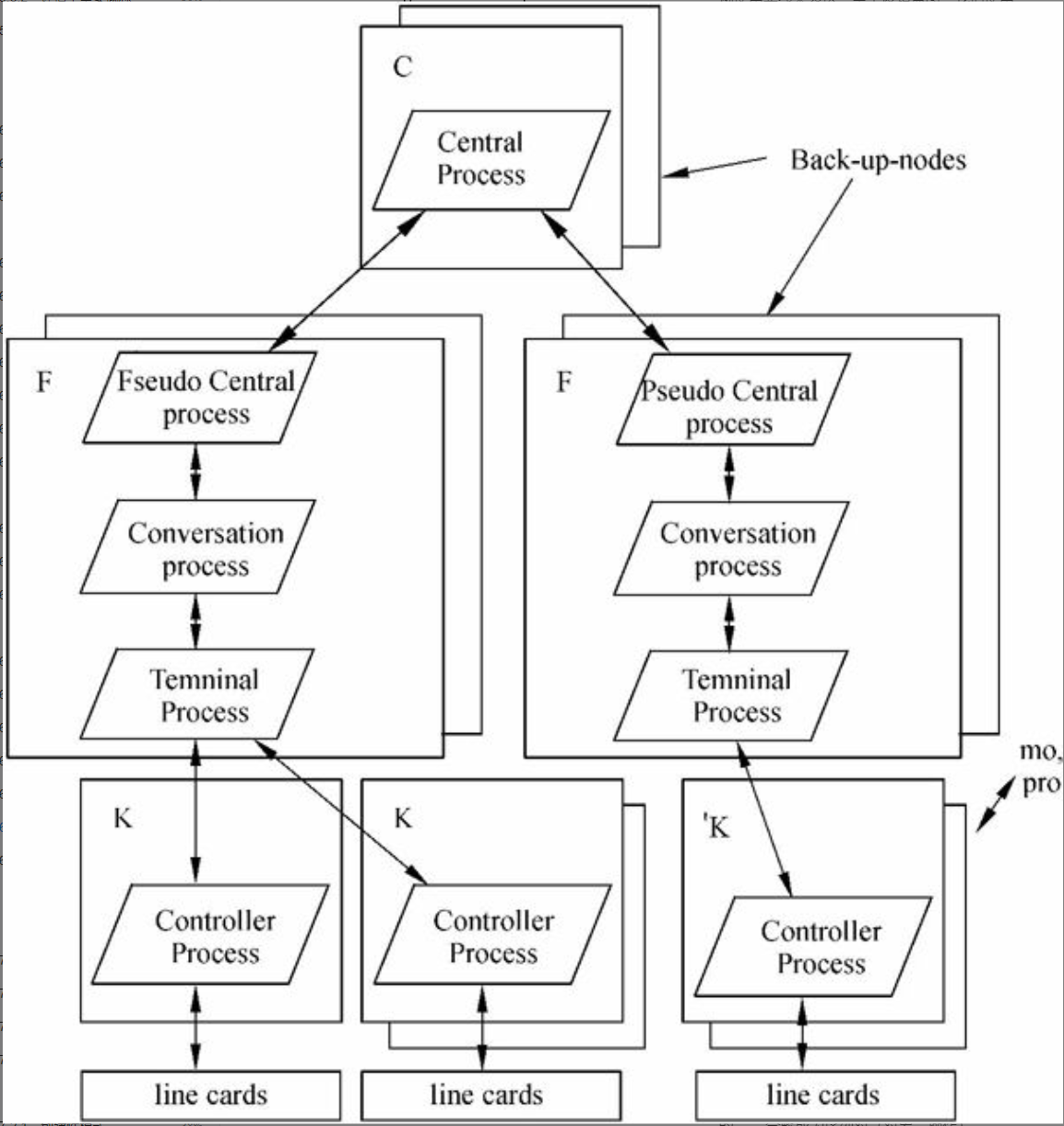
图6-27 进程蓝图表示法
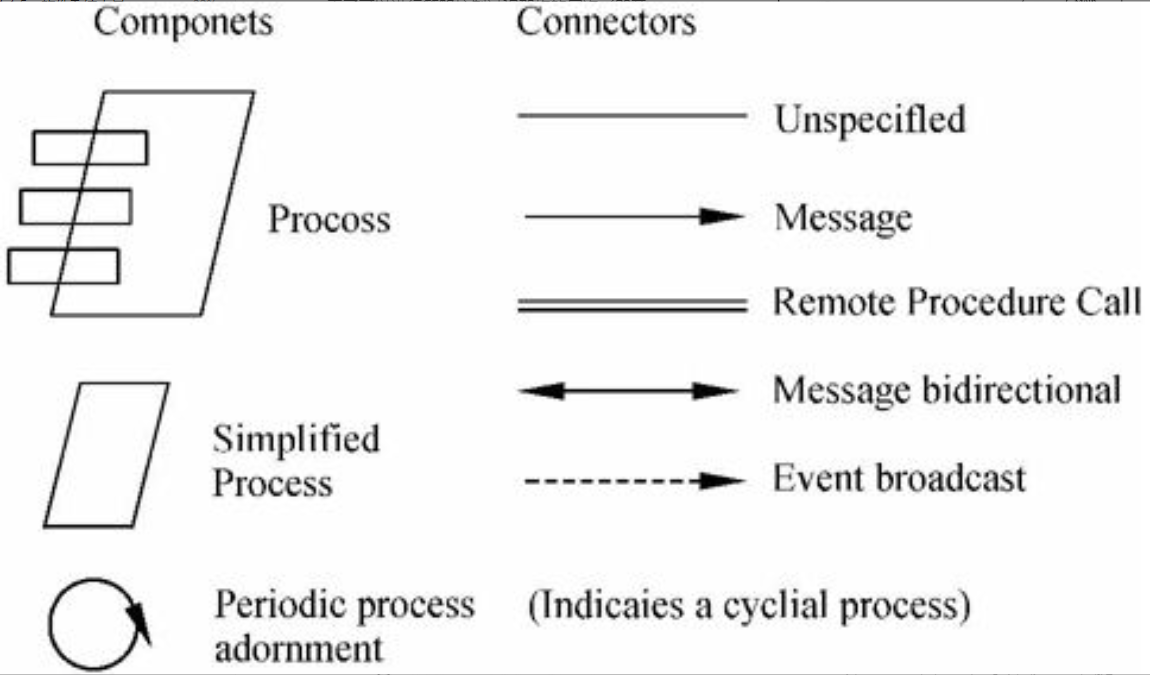
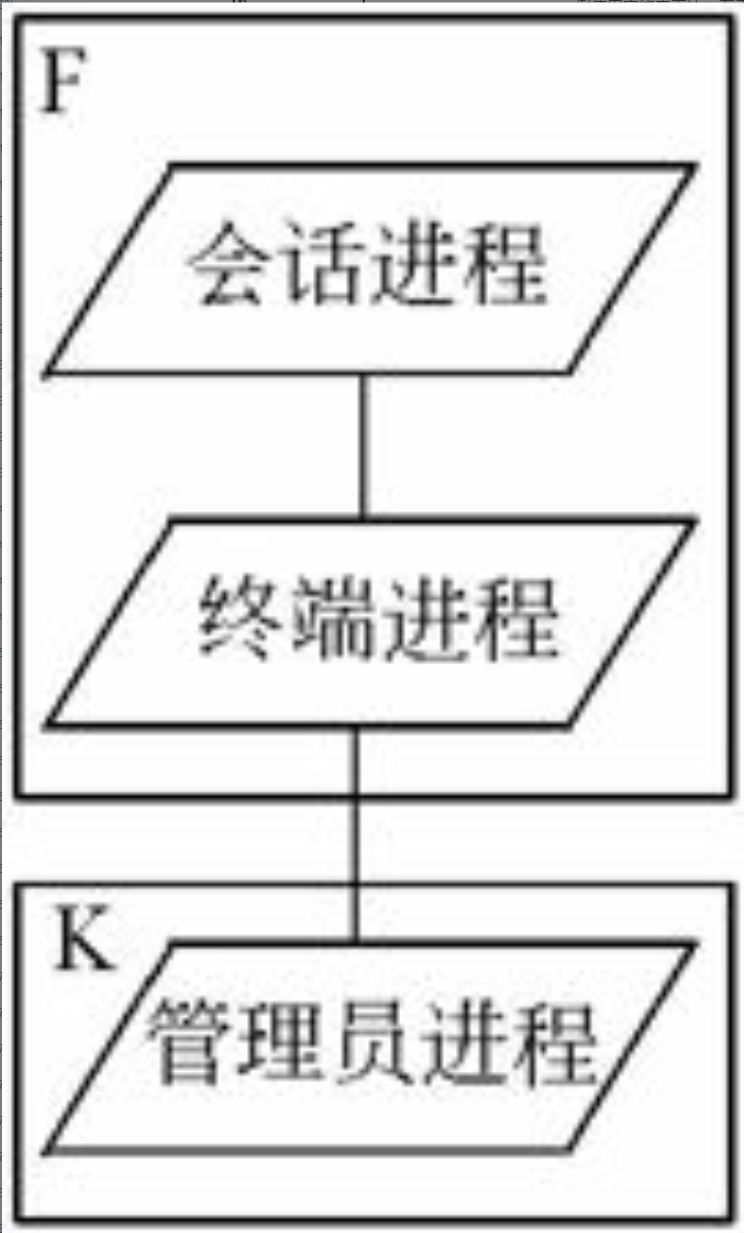
所有的终端由单个的Termal process处理,其中Termal process由输入队列中的消息进行驱动。Controller对象在组成控制过程三个任务之中的一项任务上执行:Low cycle rate task扫描所有的非活动终端(200 ms),将High cycle rate task(10 ms)扫描清单中的终端激活,其中High cycle rate task检测任何重要的状态变化,将它们传递给Main controller task,由它来对状态的变更进行解释,并通过向对应的终端发送消息来通信。这里Controller过程中的通信通过共享内存来实现。
开发架构
开发架构关注软件开发环境下实际模块的组织。软件打包成小的程序块(程序库或子系统),它们可以由一位或几位开发人员来开发。子系统可以组织成分层结构,每个层为上一层提供良好定义的接口。
系统的开发架构用模块和子系统图来表达,显示了“输出”和“输入”关系。完整的开发架构只有当所有软件元素被识别后才能加以描述。但是,可以列出控制开发架构的规则:分块、分组和可见性。
大部分情况下,开发架构考虑的内部需求与以下几项因素有关:开发难度、软件管理、重用性和通用性及由工具集、编程语言所带来的限制。开发架构视图是各种活动的基础,如:需求分配、团队工作的分配(或团队机构)、成本评估和计划、项目进度的监控、软件重用性、移植性和安全性。它是建立产品线的基础。
来自Rational的Apex开发环境支持开发架构的定义和实现和前文描述的分层策略,以及设计规则的实施。Rational Rose可以在模块和子系统层次上绘制开发蓝图,并支持开发源代码(Ada、C++)进程的正向和反向工程。
关于开发视图的风格,推荐使用分层(layered)的风格,定义4~6个子系统层。每层均具有良好定义的职责。设计规则是某层子系统依赖同一层或低一层的子系统,从而最大程度地减少了具有复杂模块依赖关系的网络的开发量,得到层次式的简单策略。
图6-29 Hughes空中交通系统(HATS)的5个层
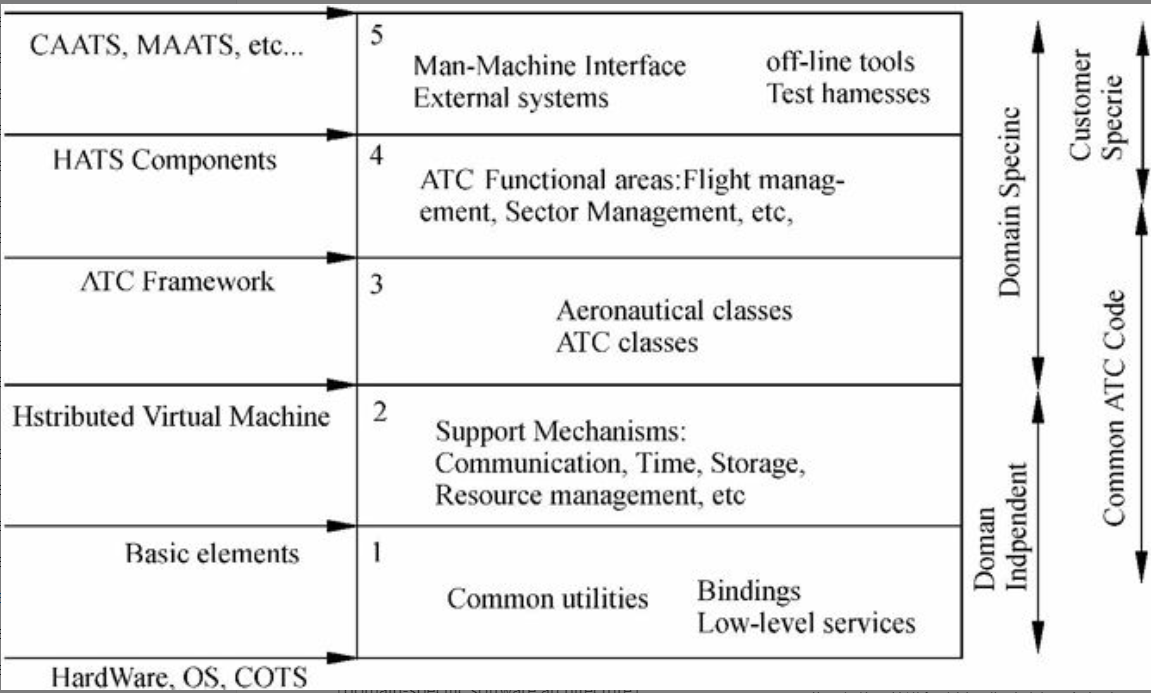
图6-29代表了加拿大的Hughes Aircraft开发的空中交通控制系统(air traffic control system)产品线的5个分层开发组织结构。
第一层和第二层组成了独立于域的覆盖整个产品线的分布式基础设施,并保护其免受不同硬件平台、操作系统或市售产品(如数据库管理系统)的影响。第三层为该基础设施增加了ATC (Adaptive Transform Coding,自适应变换编码方法)框架,形成一个特定领域的软件架构(domain-specific software architecture)。使用该框架,可以在第四层上构建一个功能选择板。层次5则非常依赖于客户和产品,包含了大多数用户接口和外部系统接口。72个子系统分布于5个层次上,每层包含了10~50个模块,并可以在其他蓝图上表示。
物理架构
物理架构主要关注系统非功能性的需求,如可用性、可靠性(容错性),性能(吞吐量)和可伸缩性。软件在计算机网络或处理节点上运行,被识别的各种元素(网络、过程、任务和对象),需要被映射至不同的节点;我们希望使用不同的物理配置:一些用于开发和测试,另外一些则用于不同地点和不同客户的部署。因此软件至节点的映射需要高度的灵活性及对源代码产生最小的影响。
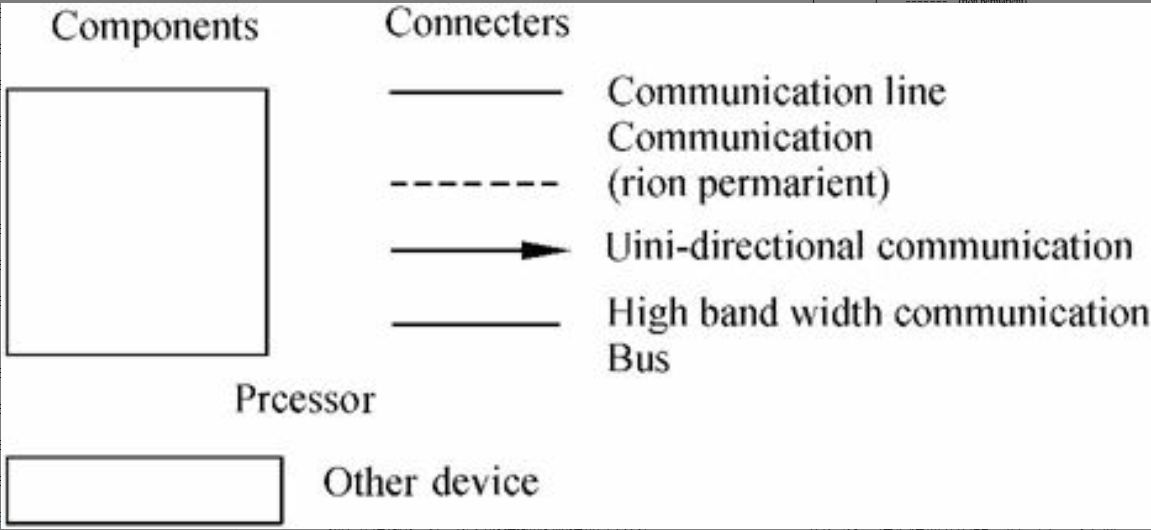
物理蓝图的表示法,如图6-30所示。
大型系统中的物理蓝图会变得非常混乱,所以它们可以采用多种形式,有或者没有来自进程视图的映射均可。
图6-30 物理蓝图的表示法
TRW(Thompson Ramo Wooldridge Lnc)公司的UNAS(Universal Network Architecture Services)提供了数据驱动方法将过程架构映射至物理架构,该方法允许大量的映射的变更而无需修改源代码。
图6-31 PABX的物理蓝图
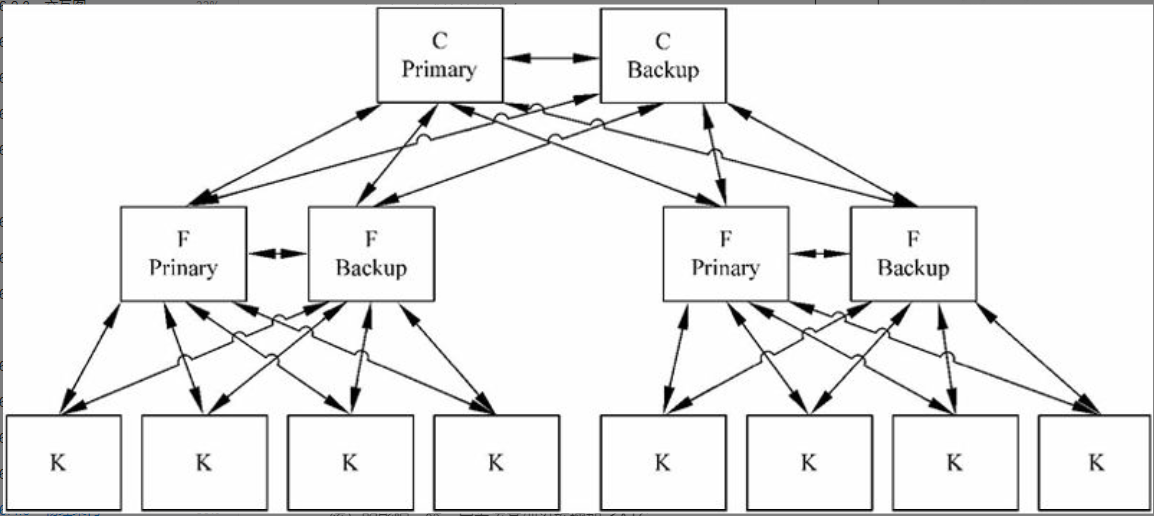
图6-31 作为物理蓝图的示例,显示了大型PABX(Private Automatic Branch Exchange)可能的硬件配置,而图6-32和图6-33显示了两种不同物理架构上的进程映射,分别对应一个小型和一个大型PABX。C、F和K是三种不同容量的计算机,支持三种不同的运行要求。
图6-32带有过程分配的小型PABX物理架构
场景
4种视图的元素通过数量比较少的一组重要场景(更常见的是用例)进行无缝协同工作,我们为场景描述相应的脚本(对象之间和过程之间的交互序列)。在某种意义上场景是最重要的需求抽象,它们的设计使用对象场景图和对象交互图来表示。
图6-33 带有过程分配的大型PABX物理架构
该视图是其他视图的冗余(因此“+1”),但它起到了两个作用:
- 作为一项驱动因素来发现架构设计过程中的架构元素。
- 作为架构设计结束后的一项验证和说明功能,既以视图的角度来说明又作为架构原型测试的出发点。
场景表示法与组件逻辑视图非常相似(请对照图6-22),但它使用过程视图的连接符来表示对象之间的交互(请对照图6-25),注意对象实例使用实线来表达。至于逻辑蓝图,我们使用Rational Rose来捕获并管理对象场景。
图6-34是关于场景的例子,显示了小型PABX的场景片段。相应的脚本如下。
图6-34 本地呼叫的初期场景——阶段选择
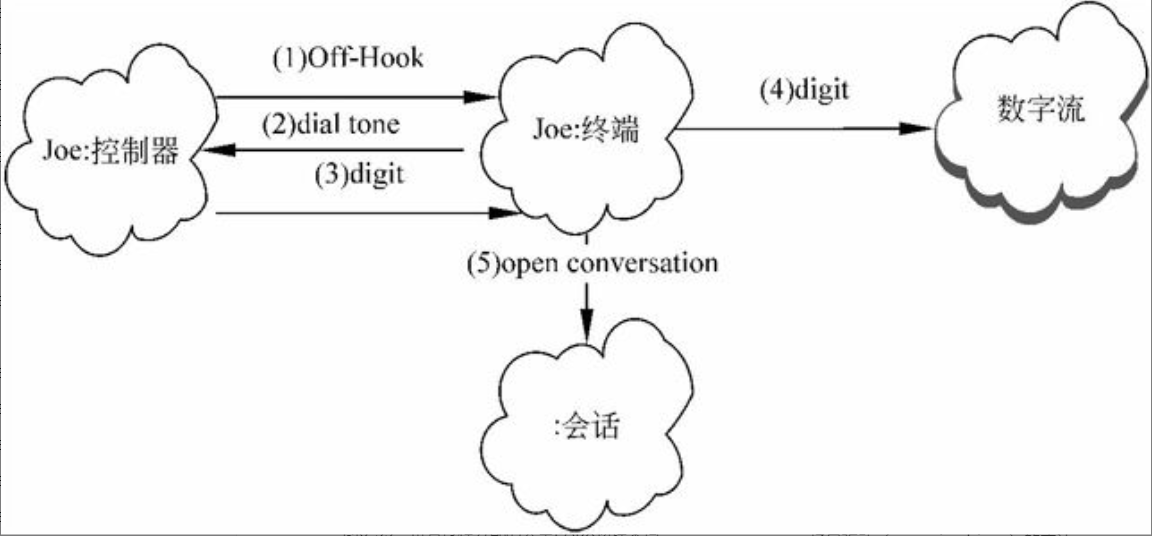
(1)Joe的电话控制器检测和校验摘机状态的变换,并发送消息唤醒相应的终端对象。
(2)终端分配一些资源,并要求控制器发出拨号音。
(3)控制器接受拨号并传递给终端。
(4)终端使用拨号方案来分析数字流。
(5)有效的数字序列被键入,终端开始会话。
迭代过程
在进行文档化时,提倡一种更具有迭代性质的方法——架构先被原形化、测试、估量、分析,然后在一系列的迭代过程中被细化。该方法除了减少与架构相关的风险之外,对于项目而言还有其他优点:团队合作、培训,加深对架构的理解,深入程序和工具等(此处提及的是演进的原形,逐渐发展成为系统,而不是一次性的试验性的原形)。这种迭代方法还能够使需求被细化、成熟化并能够被更好地理解。
场景驱动(scenario-driven)的方法
系统大多数关键的功能以场景(或use cases)的形式被捕获。关键意味着:最重要的功能,系统存在的理由,或使用频率最高的功能,或体现了必须减轻的一些重要的技术风险。
开始阶段
(1)基于风险和重要性为某次迭代选择一些场景。场景可能被归纳为对若干用户需求的抽象。
(2)形成“稻草人式的架构”。然后对场景进行“描述”,以识别主要的抽象(类、机制、过程、子系统),如Rubin与Goldberg6所指出的——分解成为序列对(对象、操作)。
(3)所发现的架构元素被分布到4个蓝图中,即逻辑蓝图、进程蓝图、开发蓝图和物理蓝图。
(4)然后实施、测试、度量该架构,这项分析可能检测到一些缺点或潜在的增强要求。
(5)捕获经验教训。
循环阶段
(1)下一个迭代过程开始进行。
(2)重新评估风险。
(3)扩展考虑的场景选择板。
(4)选择能减轻风险或提高结构覆盖的额外的少量场景。
(5)然后试着在原先的架构中描述这些场景。
(6)发现额外的架构元素,或有时还需要找出适应这些场景所需的重要架构变更。
(7)更新4个主要视图:逻辑视图、进程视图、开发视图和物理视图。
(8)根据变更修订现有的场景。
(9)升级实现工具(架构原型)来支持新的、扩展了的场景集合。
(10)测试。如果可能的话,在实际的目标环境和负载下进行测试。
(11)然后评审这5个视图来检测简洁性、可重用性和通用性的潜在问题。
(12)更新设计准则和基本原理。
(13)捕获经验教训。
(14)终止循环。
为了实际的系统,初始的架构原型需要进行演进。较好的情况是在经过两次或三次迭代之后,结构变得稳定:主要的抽象都已被找到。子系统和过程都已经完成,以及所有的接口都已经实现。接下来则是软件设计的范畴,这个阶段可能也会用到相似的方法和过程。
这些迭代过程的持续时间参差不齐,原因在于:所实施项目的规模,参与项目人员的数量、他们对本领域和方法的熟悉程度,以及该系统和开发组织的熟悉程度等。因而较小的项目迭代过程可能持续2~3周,而大型的项目可能为6~9个月。
网课
图
图片详情
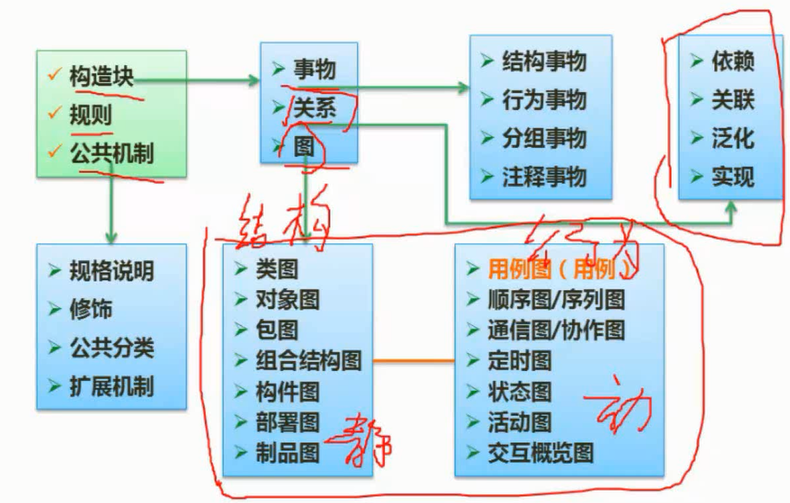
用例图是静态还是动态
部署图: 部署到哪个硬件上