王道
线性表
p24
链表的单双:指的是节点中有$\color{red}{\text{一个(单)}}$指针域,$\color{red}{\text{两个(双)}}$指针域,
线性表的定义和基本操作
线性表的定义
线性表是具有相同数据类型的$n (n \geq 0)$个数据元素的有限序列,其中
为表长,当$n=0$时线性表是一个空表。若用$L$命名线性表,则其一般表示为
$$
L=(a_1,a_2,\cdots,a_i,a_{i+1},\cdots,a_n)
$$
式中,$a_1$是唯一的“第一个”数据元素,又称$\color{green}{\text{表头元素}}$;$a_n$是唯一的“最后一个”数据元素,又称$\color{green}{\text{表尾元素}}$。除第一个元素外,每个元素有且仅有一个直接前驱。除最后一个元素外,每个元素有且仅有一个直接后继。以上就是线性表的$\color{green}{\text{逻辑特性}}$,这种线性有序的逻辑结构正是线性表名字的由来。
由此,我们得出线性表的特点如下。
- 表中元素的个数有限。
- 表中元素具有逻辑上的顺序性,表中元素有其先后次序。表中元素都是数据元素,每个元素都是单个元素。
- 表中元素的数据类型都相同,这意味着每个元素占有相同大小的存储空间。
- 表中元素具有抽象性,即仅讨论元素间的逻辑关系,而不考虑元素究竟表示什么内容。
注意:$\color{green}{\text{线性表}}$是一种$\color{green}{\text{逻辑结构}}$,表示元素之间一对一的相邻关系。$\color{green}{\text{顺序表}}$和$\color{green}{\text{链表}}$是指$\color{green}{\text{存储结构}}$,两者属于不同层面的概念,因此不要将其混淆。
线性表的基本操作
1 | InitList ( &L):初始化表。构造一个空的线性表。 |
线性表的顺序表示
顺序表的定义
线性表的顺序存储又称$\color{green}{\text{顺序表}}$。它是用一组地址连续的存储单元一次存储线性表中的数据元素,从而使得逻辑上相邻的两个元素在物理位置上也相邻。第1个元素存储在下你星标的起始位置,第$i$个元素的存储位置后面紧接着存储的是第$i+1$个元素,称$i$为元素$a_i$在线性表中的$\color{green}{\text{位序}}$,顺序表的特点是表中元素的$\color{yellow}{\text{逻辑顺序与其物理顺序相同}}$。
假设线性表$L$存储的起始位置为$\text{LOC(A)}$,$\text{sizeof(ElemType)}$是每个数据元素所占用存储空间的大小,则表L所对应的顺序存储如图2.1所示。
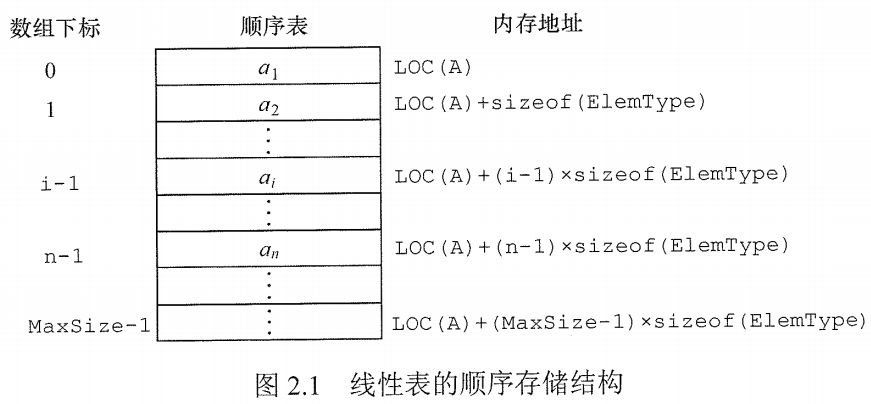
每个数据元素的存储位置都和线性表的起始位置相差一个和该数据元素的位序成正比的常数,因此,线性表中的任一数据元素都可以随机存取,所以线性表的顺序存储结构是一种$\color{red}{\text{随机存取}}$的存储结构。通常用高级程序设计语言中的$\color{green}{\text{数组}}$来描述线性表的顺序存储结构。
- 注:线性表中元素的位序是从1开始的,而数组中元素的下标是从0开始的
假定线性表的元素类型为ElemType,则线性表的顺序存储类型描述为
1 |
|
而在动态分配时,存储数组的空间是在程序执行过程中通过动态存储分配语句分配的,一旦数据空间占满,就另外开辟一块更大的存储空间,用以替换原来的存储空间,从而达到扩充存储数组空间的目的,而不需要为线性表一次性地划分所有空间。
1 |
|
C的初始动态分配语句为
L.data= (ElemType* ) malloc (sizeof (ElemType ) *Initsize) ;
C++的初始动态分配语句为
L.data=new ElemType [ Initsize];
顺序表最主要的特点是$\color{green}{\text{随机访问}}$,即通过首地址和元素序号可在时间O(1)内找到指定的元素。
顺序表的$\color{green}{\text{存储密度高}}$,每个结点只存储数据元素。
顺序表逻辑上相邻的元素物理上也相邻,所以插入和删除操作需要移动大量元素。
顺序表上基本操作的实现
插入操作
1 | bool ListInsert (SqList &L,int i,ElemType e){ |
最好情况:在表尾插入(即$i=n+ 1$),元素后移语句将不执行,时间复杂度为$O(1)$。
最坏情况:在表头插入(即$i= 1$),元素后移语句将执行$n$次,时间复杂度为$O(n)$。
平均情况:假设$p_i (p_i = \dfrac{1}{n+1}$是在第$i$个位置上插入一个结点的概率,则在长度为n的线性表中插入一个结点时,所需移动结点的平均次数为
$$
\displaystyle \sum_{i=1}^{n+1}p_i(n-i+1) = \displaystyle \sum_{i=1}^{n+1}\dfrac{1}{n+1}(n-i+1) = \dfrac{1}{n+1}\displaystyle \sum_{i=1}^{n+1}(n-i+1)=\dfrac{1}{n+1}\dfrac{n(n+1)}{2}=\dfrac{n}{2}
$$
因此,线性表插入算法的平均时间复杂度为O(n)。
删除操作
1 | bool ListDelete (SqList &L,int i,Elemtype &e){ |
最好情况:删除表尾元素(即$i=n$),无须移动元素,时间复杂度为$O(1)$。
最坏情况:删除表头元素(即$i=1$),需移动除表头元素外的所有元素,时间复杂度为$O(n)$。
平均情况:假设$p_i(p_i = \dfrac{1}{n})$是删除第$i$个位置上结点的概率,则在长度为$n$的线性表中删除一个结点时,所需移动结点的平均次数为
$$
\displaystyle \sum_i^n p_i(n-i) = \displaystyle \sum_i^n \dfrac{1}{n}(n-i)=\dfrac{1}{n} \displaystyle \sum_i^n (n-i)=\dfrac{1}{n}\dfrac{n(n-1)}{2}=\dfrac{n-1}{2}
$$
因此,线性表删除算法的平均时间复杂度为$O(n)$。
按值查找(顺序查找)
1 | int LocateElem (sqList L,ElemType e){ |
平均情况:假设$p_i(p_i = \dfrac{1}{n})$是查找的元素在第i(1<=i<=L.length)个位置上的概率,则在长度为n的线性表中查找值为e的元素所需比较的平均次数为
$$
\displaystyle \sum_i^n p_i \times i = \displaystyle \sum_i^n \dfrac{1}{n} \times i =\dfrac{1}{n}\dfrac{n(n+1)}{2}=\dfrac{n+1}{2}
$$
因此,线性表按值查找算法的平均时间复杂度为$O(n)$。
线性表的链式表示
单链表的定义
线性表的链式存储又称单链表,它是指通过一组任意的存储单元来存储线性表中的数据元素。为了建立数据元素之间的线性关系,对每个链表结点,除存放元素自身的信息外,还需要存放一个指向其后继的指针。其中 data为$\color{green}{\text{数据域}}$,存放数据元素。next为$\color{green}{\text{指针域}}$,存放其后继节点的的地址。
1 | typedef struct LNode { |
利用单链表可以解决顺序表需要大量连续存储单元的缺点,但单链表附加指针域,也存在浪费存储空间的缺点。由于单链表的元素离散地分布在存储空间中,所以单链表是非随机存取的存储结构,即不能直接找到表中某个特定的结点。查找某个特定的结点时,需要从表头开始遍历,依次查找。
通常用头指针来标识一个单链表,如单链表L,头指针为NULL时表示一个空表。此外,为了操作上的方便,在单链表第一个结点之前附加一个结点,称为$\color{green}{\text{头结点}}$。头结点的数据域可以不设任何信息,也可以记录表长等信息。头结点的指针域指向线性表的第一个元素结点,如图2.4所示。

头结点和头指针的区分:不管带不带头结点,头指针都始终指向链表的第一个结点,而头结点是带头结点的链表中的第一个结点,结点内通常不存储信息。
引入头结点后,可以带来两个优点:
- 由于第一个数据结点的位置被存放在头结点的指针域中,因此在链表的第一个位置上的操作和在表的其他位置上的操作一致,无须进行特殊处理。(增删改查)
- 无论链表是否为空,其头指针都指向头结点的非空指针(空表中头结点的指针域为空),因此空表和非空表的处理也就得到了统一。($\blacktriangleright$(自己的理解) Q:会对空列表和非空列表那些操作有影响)
单链表上基本操作的实现
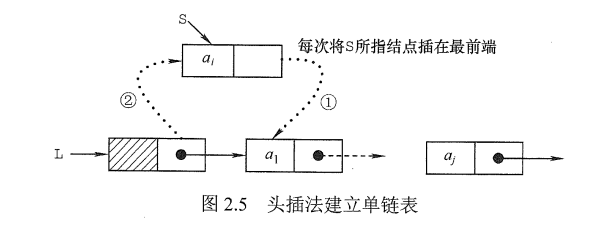
采用头插法建立单链表
该方法从一个空表开始,生成新结点,并将读取到的数据存放到新结点的数据域中,然后将新结点插入到当前链表的表头,即头结点之后。
1 | LinkList List HeadInsert (LinkList &){//逆向建立单链表 |
$\color{red}{\text{若没有设立头结点}}$:因为在头部插入新结点,每次插入新结点后,需要将它的地址赋值给头指针L。
总的时间复杂度是$O(n)$
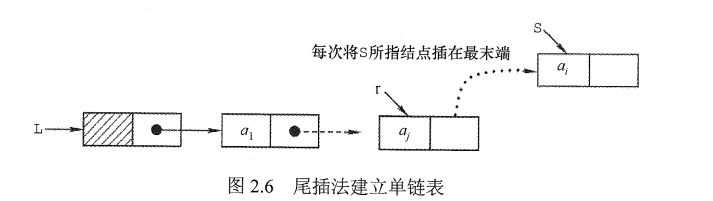
采用尾插法建立单链表
头插法建立单链表的算法虽然简单,但生成的链表中结点的次序和输入数据的顺序不一致。若希望两者次序一致,则可采用尾插法。该方法将新结点插入到当前链表的表尾,为此必须增加一个尾指针r,使其始终指向当前链表的尾结点,如图2.6所示。
1 | LinkList List_TailInsert (LinkList &L){//正向建立单链表 |
总的时间复杂度是$O(n)$
按序号查找节点值
1 | LNode *GetElem (LinkList L, int i){ |
Q:若i等于0,则返回的就是第一个节点才对?
时间复杂度$O(n)$
按值查找表结点
1 | LNode *LocateElem(LinkList L, ElemType e){ |
时间复杂度$O(n)$
时间复杂度$O(n)$
插入结点操作
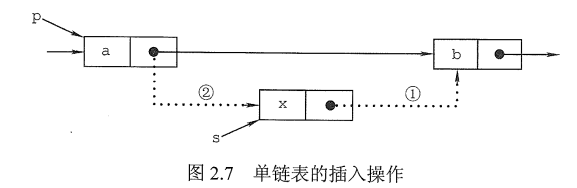
1 | p=GetElem(L,i-1); //查找插入位置的前驱结点 |
查找的时间复杂度$O(n)$,插入的时间复杂度为$O(1)$
拓展:对某一结点进行前插操作
如果已知待查节点的指针,可以实现$O(1)$操作:修改指针域,交换数据域
1 | //将*s结点插入到*p之前的主要代码片段 |
删除结点操作
1 | p=GetElem (L,i-1) ;//查找删除位置的前驱结点 |
时间复杂度$O(n)$
拓展:删除节点*p
如果已知待删节点的指针,可以实现$O(1)$操作:修改指针域,交换数据域
1 | q=p->next;//令q指向*p的后继结点 |
求表长操作
从第一个节点开始,直到访问到空姐点为止。算法的时间复杂度为$O(n)$
- 求表长的时候单链表需要单独处理
双链表
单链表结点中只有一个指向其后继的指针,使得单链表只能从头结点依次顺序地向后遍历。要访问某个结点的前驱结点(插入、删除操作时),只能从头开始遍历,访问后继结点的时间复杂度为$O(1)$,访问前驱结点的时间复杂度为$O(n)$。
为了克服单链表的上述缺点,引入了双链表,双链表结点中有两个指针prior和next,分别指向其前驱结点和后继结点,如图2.9所示。
1 | typedef structDNode {//定义双链表结点类型 |
双链表在单链表的结点中增加了一个指向其前驱的prior 指针,因此双链表中的按值查找和按位查找的操作与单链表的相同。但双链表在插入和删除操作的实现上,与单链表有着较大的不同。
这是因为“链”变化时也需要对prior 指针做出修改,其关键是保证在修改的过程中不断链。此外,双链表可以很方便地找到其前驱结点,因此,插入、删除操作的时间复杂度仅为$O(1)$。
双链表的插入操作
在双链表中p所指的结点之后插入结点*s,其指针的变化过程如图2.10所示。
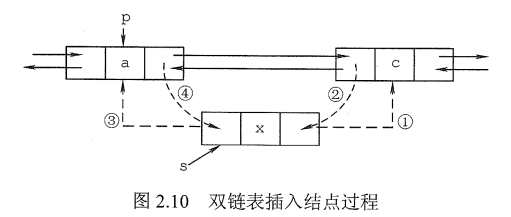
1 | s->next=p->next;//将结点*s插入到结点*p之后 |
Q:在前方插入节点
双链表的删除操作
删除双链表中结点*p的后继结点*q,
1 | p->next=q->next; |
Q:删除前驱节点
循环链表
循环单链表
循环单链表和单链表的区别在于,表中最后一个结点的指针不是NULL,而改为指向头结点,从而整个链表形成一个环,如图2.12所示。
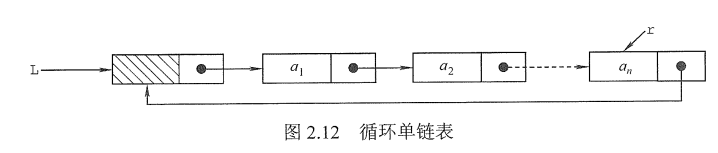
在循环单链表中,表尾结点*r的next 域指向L,故表中没有指针域为NULL的结点,因此,循环单链表的$\color{red}{\text{判空条件}}$不是头结点的指针是否为空,而是它是否等于头指针。
循环单链表的插入、删除算法与单链表的几乎一样,所不同的是若操作是在表尾进行,则执行的操作不同,以让单链表继续保持循环的性质。当然,正是因为循环单链表是一个“环”,因此在任何一个位置上的插入和删除操作都是等价的,无须判断是否是表尾。
在单链表中只能从表头结点开始往后顺序遍历整个链表,而循环单链表可以从表中的任意一个结点开始遍历整个链表。有时对单链表常做的操作是在表头和表尾进行的,此时对循环单链表不设头指针而仅$\color{red}{\text{设尾指针}}$,从而使得操作效率更高。其原因是,若设的是头指针,对表尾进行操作需要$O(n)$的时间复杂度,而若设的是尾指针r,r->next即为头指针,对表头与表尾进行操作都只需要$O(1)$的时间复杂度。
循环双链表
由循环单链表的定义不难推出循环双链表。不同的是在循环双链表中,头结点的 prior指针还要指向表尾结点,如图2.13所示。
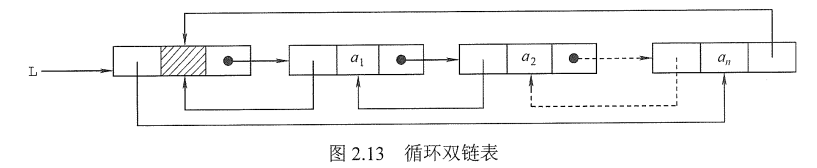
在循环双链表L中,某结点*p为尾结点时,p->next==L;当循环双链表为空表时,其头结点的prior域和next域都等于L。
静态链表
静态链表借助数组来描述线性表的链式存储结构,结点也有数据域data和指针域next,与前面所讲的链表中的指针不同的是,这里的指针是结点的相对地址(数组下标),又称游标。和顺序表一样,静态链表也要预先分配一块连续的内存空间。静态链表和单链表的对应关系如图2.14所示。
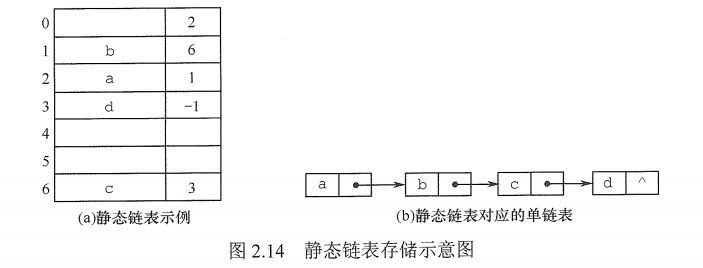
静态链表结构类型的描述如下:
1 |
|
静态链表以next==-1作为其结束的标志。静态链表的插入、删除操作与动态链表的相同,只需要修改指针,而不需要移动元素。总体来说,静态链表没有单链表使用起来方便,但在一些不支持指针的高级语言(如Basic)中,这是一种非常巧妙的设计方法。
顺序表和链表的比较
| 比较点 | 顺序表 | 链表 |
|---|---|---|
| 存取(读写)方式 | 顺序表可以顺序存取,也可以随机存取 | 链表只能从表头顺序存取元素 |
| 逻辑结构与物理结构 | 采用顺序存储时,逻辑上相邻的元素,对应的物理存储位置也相邻。 | 而采用链式存储时,逻辑上相邻的元素,物理存储位置不一定相邻,对应的逻辑关系是通过指针链接来表示的。 |
| 按值查找 | 无序:$O(n)$ 有序:折半查找$O(log_2(n))$ | $O(n)$ |
| 按序查找 | $O(1)$ | $O(n)$ |
| 插入删除 | $O(n)$(平均需移动半个表长的元素) | $O(1)$ |
| 空间分配 | 固定分配 | 节点只需申请时分配 |
| 基于存储考虑存储结构的选择 | 难以估计长度或存储规模时,不宜采用顺序表 | 链表不用事先估计存储规模,但链表的存储密度较低,显然链式存储结构的存储密度是小于1的。 |
| 基于运算考虑存储结构的选择 | 按序号访问,顺序表优于链表 | 插入删除,链表由于顺序表 |
| 基于环境考虑存储结构的选择 | 容易实现,基本高级语言都有实现 | 频繁动态的插入删除 |