缘起
记录一些常规操作
shell快捷键
| 快捷键 | 用处 |
|---|---|
| ctrl+a | 光标移动至行首 |
| ctrl+e | 光标移动至行尾 |
| Esc b | 左移一个单词(back) |
| Esc f | 右移一个单词(forward) |
linux Commands
从服务器上下载和上传文件
安装:yum install lrzsz
下载:sz filename
上传文件到服务端:rz
查看核心数
新建用户
sudo adduser username
删除用户
sudo userdel username
将用户添加到sudo组
sudo adduser username sudo
显示端口占用
sudo netstat -tlpn
根据pid杀死进程
kill -9 pid
禁用22端口
TODO
df
df -h 和 df -kh的区别是什么
1 | (base) [root@izuf66ctwpabqmq17tt0r3z ~]# df -kh |
添加软链
ln -s [源文件或目录] [目标文件或目录]
zip文件
将 /home/html/ 这个目录下所有文件和文件夹打包为当前目录下的 html.zip:
1 | zip -q -r html.zip /home/html |
screen
添加一个新的screen
1 | screen -S session_name |
重新attach进之前的session
1 | screen -r |
关闭某个session
1 | screen -XS [session # you want to quit] quit |
加密文本
加密文本并输出到控制台:echo "这是需要加密的文本" | openssl des3 -a -pbkdf2 -iter 10000 -k password
解密文本并输出到控制台:echo "U2FsdGVkX1/e3OGKzCTAQLSP1p0QGQpT3AcWOXxOjyKtPxe7w3xRlX0w2hIGORP2" | openssl des3 -d -a -pbkdf2 -iter 10000 -k password
tar
解压 tar.xz: tar -xf
解压 *.tar.gz: tar -zxvf 压缩文件名.tar.gz
使用密码压缩:
代码详情
1 |
|
使用密码解压:
代码详情
1 |
|
- 参数的解释
在 tar 命令中,- 参数用来指定压缩或解压缩的数据应该从标准输入或标准输出流中读取或写入。当你使用 - 时,你实际上是在告诉 tar 命令从标准输入(stdin)读取数据,而不是从文件系统中的某个文件读取。
在你提供的命令 tar -czvf - temp 中,- 告诉 tar 从标准输入读取数据,而 temp 是要被压缩的文件或目录的名称。这个命令的意思是,将 temp 目录压缩,并将压缩数据发送到标准输出(stdout)。
如果你去掉 -,命令将变成 tar -czvf temp,这将导致 tar 命令尝试直接将压缩数据写入到名为 temp 的文件中,而不是通过管道传递给 openssl 进行加密。这样,你将不会得到一个加密的压缩文件,而是仅仅得到一个压缩文件。
因此,为了确保 tar 命令的输出可以通过管道传递给 openssl 进行加密,你需要保留 - 参数。正确的命令应该是:
1 | tar -czvf - temp | openssl des3 -salt -k password -out files.tar.gz |
这样,tar 命令会将 temp 目录压缩,并通过管道将压缩数据传递给 openssl 命令进行加密,最终加密的数据会被写入到 files.tar.gz 文件中。
查看文件夹大小
1 | du -sh |
echo
1 | 追加内容 |
rm
1 | 删除指定后缀的文件 |
grep
如果对应日志过于长,想要了解匹配内容的概览,可以使用正则截断grep -noE '你想匹配的内容.{100}' xxxx.log
-n显示行号-o只显示匹配到的内容-E支持正则表达式.匹配任意字符{100}匹配规则出现100次
如果特定的行过于长,可以管道到 less来翻页查看
grep '匹配到这一行的内容非常长' xxxx.log | less
b向上翻一页d向后翻半页h显示帮助界面Q退出less 命令u向前滚动半页y向前滚动一行G- 移动到最后一行g- 移动到第一行
grep文件带通配符,同时grep多个文件
grep -R '关键字' ./20230215-* | grep '关键字2'
grep -v剔除某个关键字
grep -v “需要被排除的关键字”
zgrep
如果日志被打包成 gz格式之后,如果想要查询对应的日志可以通过 zgrep xxx.gz
zcat
Zcat是一个命令行实用程序,用于查看压缩文件的内容。它将压缩文件扩展为标准输出,允许您查看内容。
代码详情
1 | $ zcat /var/log/syslog.2.gz | tail -1 |
cat
cat的全称
在 Linux 和其他类 Unix 操作系统中,cat 命令用于串联和显示文件内容。虽然 cat 的确切全称在命令手册中并未明确指定,但普遍认为 cat 是 “concatenate”(串联)的缩写。这个命令常用于查看文件内容、将文件内容合并输出到标准输出(屏幕)或其他文件等操作。
查看文件的换行符
代码详情
1 | cat -e newline.txt |
centos相关
屏蔽ip
总有脚本小子到处扫端口,把应用都扫坏了,所以有了这个需求
1 | firewall-cmd --list-rich-rules # 查看屏蔽的ip |
添加ip
1 | firewall-cmd --permanent --add-rich-rule="rule family=ipv4 source address=43.229.53.61 reject" |
重启防火墙生效
1 | firewall-cmd --reload |
一条长命令整合上面的操作
1 | firewall-cmd --permanent --add-rich-rule="rule family=ipv4 source address=162.142.125.54 reject" && firewall-cmd --reload && firewall-cmd --list-rich-rules |
ubuntu相关
很多机器学习的环境都是基于ubuntu的,所以把一台云服务器的系统换成了ubuntu
文件颜色的意义
- 蓝色:文件夹
- 绿色:表示可执行文件
- 红色:表示tar压缩文件
- 黄色:表示设备文件,在/dev下全是这类文件
- 浅蓝色:表示链接文件
- 白色文件:一般性文件,如文本文件,配置文件,源码文件
查看ubuntu版本

在ubuntu上安装v2ray
tx云的网络太拉跨了,装包和git clone什么的都要半天,没有proxy根本过不去日子
去repo的release下载并放到服务器解压
支线1:v2ray.service启动(systemctl start v2ray不起来)不起来
出现了两个bug
cp: cannot create regular file '/usr/lib/systemd/v2ray.service': Permission deniUnit v2ray.service could not be found.
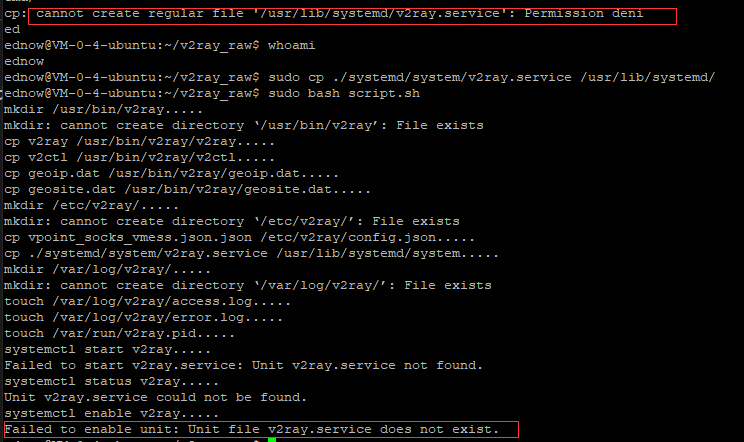
解决cannot create regular file
cp命令前加sudo
解决Unit v2ray.service could not be found.
将v2ray.service复制到 /etc/systemd/system/文件夹下
支线2:v2ray启动不起来
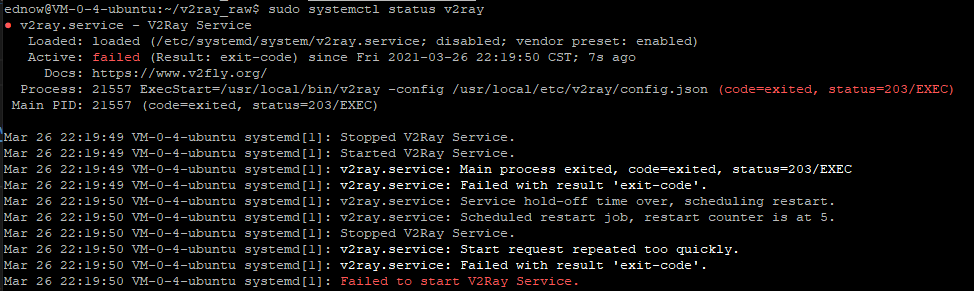
TODO
service文件里面写的v2ray和json地址和我之前写的bash小脚本的位置不太一样
ubuntu添加service
clash for linux
群晖
配置使用密匙登录
ssh-keygen -t rsa
设置开机自启
sed、grep和awk之间的区别
What are the differences among grep, awk & sed?
What is the difference between sed and awk?
sed:Readability of scripts can be difficult. Mathematical operations are extraordinarily awkward at best.I would tend to use sed where there are patterns in the text.
awk:I would use awk when the text looks more like rows and columns or, as awk refers to them “records” and “fields”.
For me the rule to separate them is: Use sed to automate tasks you would do otherwise in a text editor manually. That’s why it is called stream editor. (You can use the same commands to edit text in vim). Use awk if you want to analyze text, meaning counting fields, calculate totals, extract and reorganize structures etc.
curl的使用
使用代理
curl -x "http://user:pwd@127.0.0.1:1234"
linux设置代理
文件
/etc/profile、/etc/bashrc、/.bash_profile、/.bashrc 文件的作用
/etc/profile:此文件为系统的每个用户设置环境信息,当用户第一次登录时,该文件被执行. 并从/etc/profile.d目录的配置文件中搜集shell的设置./etc/bashrc:为每一个运行bash shell的用户执行此文件.当bash shell被打开时,该文件被读取.~/.bash_profile:每个用户都可使用该文件输入专用于自己使用的shell信息,当用户登录时,该 文件仅仅执行一次!默认情况下,他设置一些环境变量,执行用户的.bashrc文件.~/.bashrc: 该文件包含专用于你的bash shell的bash信息,当登录时以及每次打开新的shell时,该文件被读取. 当bash是以non-login形式执行时,读取此文件。若是以login形式执行,则不会读取此文件。~/.profile: 若bash是以login方式执行时,读取/.bash_profile,若它不存在,则读取/.bash_login,若前两者不存在,读取~/.profile。
容器内如何使用宿主机的anaconda环境
见 docker#容器内如何使用宿主机的anaconda环境
设置java环境
代码详情
1 | set java environment |
代理
apt-get设置代理
-o Acquire::http::proxy="http://127.0.0.1:8000/"
MISC
linux etc目录etc是什么单词的缩写
在Linux和类似的Unix操作系统中,/etc 目录通常包含系统的配置文件和脚本。etc 并不是一个严格的缩写,而是来源于拉丁语中的 “et cetera”,意为 “等等” 或 “其他”。这一命名的历史可以追溯到早期的Unix系统,它暗示了这个目录中包含了各种各样的系统配置文件。