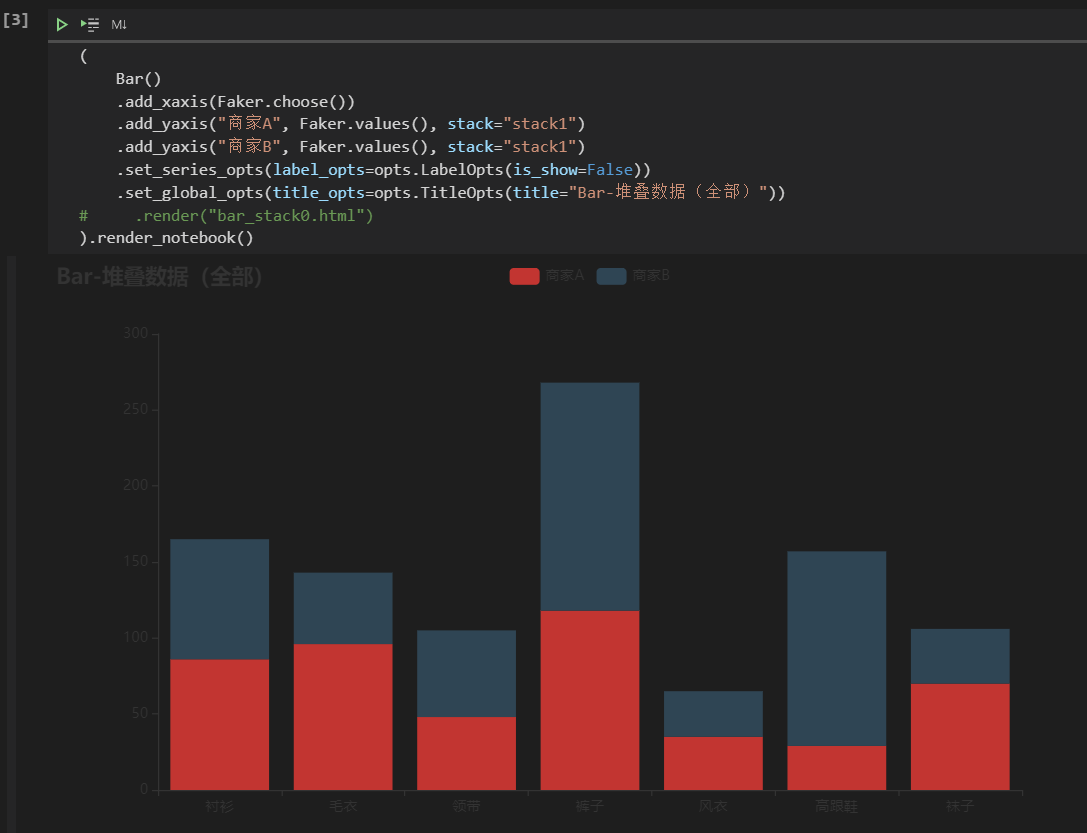
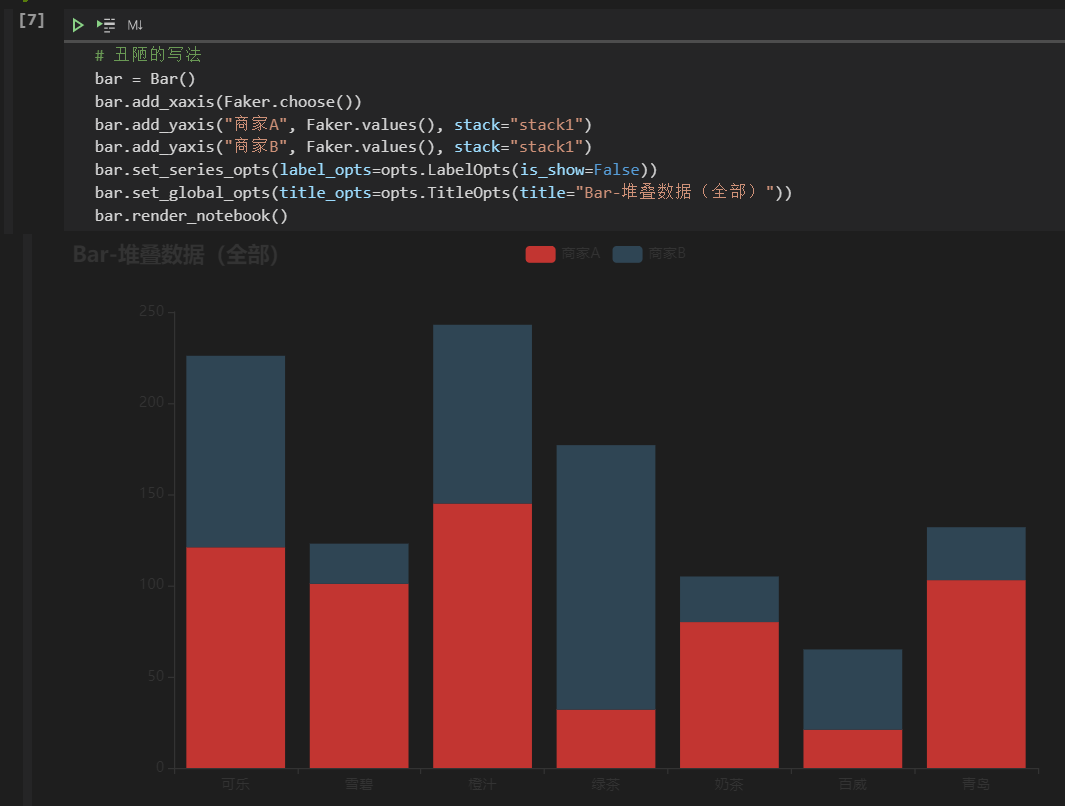
总结一些python基础技法和常用库 前言 本文的内容按照下面的思路组织
python作为一门现代语言,有着非常好的包管理工具与完美的生态
语言基础 了解python中如何组织变量的是非常重要的,是明确参数传递,变量作用域,lambda表达式的关键
多线程是python中非常重要的一环,尤其是在爬虫的时候
面对对象编程 面对对象是非常优秀的设计模式,python中涉及到面对对象的小细节
生态 为了防止重复造轮子,一门现代的语言基本上都有包管理工具,如java的maven,gradle,js的npm等
IDE 变量 变量与引用 标记赋值 标记赋值:参考文献
一个有趣的例子 为什么values=[0, [...], 2] 1 2 3 4 5 >>> values = [0, 1, 2] >>> values[1] = values >>> values [0, [...], 2]
参考文献
参考文献
参数传递 感觉cpp中这样写是对的,如何理解python中的这种现象,java中也是一样的
原因在于不存在二阶指针 !!!
无法修改地址所指的方法
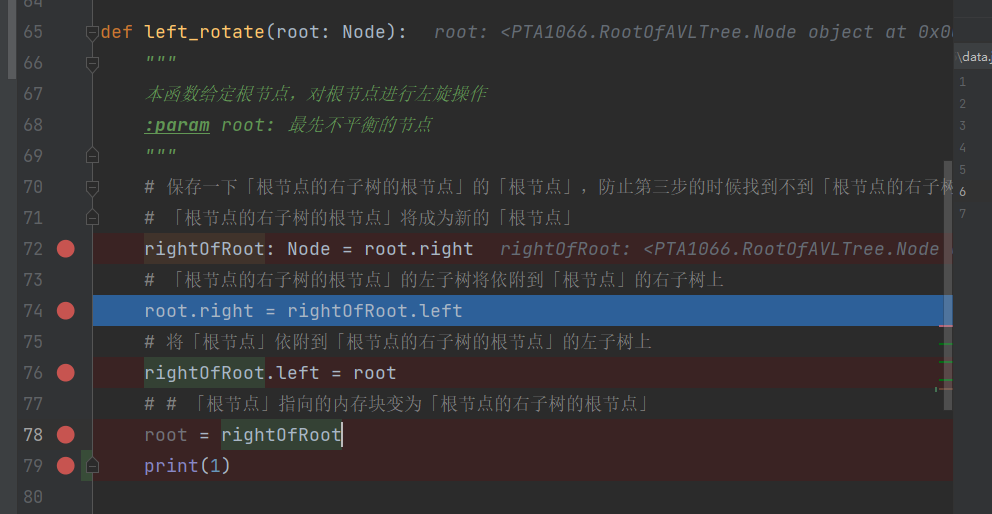
78行 创建了一个新的变量root
图片详情 值传递和参数传递 参考文献
可变类型与不可变类型
类和对象 父类的初始化 方法一: 调用未绑定的父类init 方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class A (object def __init__ (self ): self.a = 5 def function_a (self ): print('I am from A, my value is %d' % self.a) class B (A ): def __init__ (self ): A.__init__(self) self.b = 10 def function_b (self ): print('I am from B, my value is %d' % self.b) self.function_a() if __name__ == '__main__' : b = B() b.function_b()
方法二:调用super函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class A (object def __init__ (self ): self.a = 5 def function_a (self ): print('I am from A, my value is %d' % self.a) class B (A ): def __init__ (self ): super (B, self).__init__() self.b = 10 def function_b (self ): print('I am from B, my value is %d' % self.b) self.function_a() if __name__ == '__main__' : b = B() b.function_b()
super方法的参数 带不带参数理论上是一样的
参考文献 参考文献 super
设计模式 关键字与内置包 set.discard该方法不同于 remove() 方法,因为 remove() 方法在移除一个不存在的元素时会发生错误,而 discard() 方法不会。
例子 1 2 3 4 5 6 7 fruits = {"apple" , "banana" , "cherry" } fruits.discard("banana" ) print(fruits)
参考文献
assert sorted 字母表排序 int 实验 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 >>> int (1.2 )1 >>> int (1.6 )1 >>> int (1.25 )1 >>> int (1.05 )1 >>> int (3.05 )3 >>> int ("1.2" )Traceback (most recent call last): File "<stdin>" , line 1 , in <module> ValueError: invalid literal for int () with base 10 : '1.2' >>> type (1.2 )<class 'float '> >>> type ("1.2" <class 'str '> >>> int (1.2 1 >>> int ("1" 1 >>> float ("1.2" 1.2 >>> int ("0.00" Traceback (most recent call last ):File "<stdin>" , line 1 , in <module> ValueError: invalid literal for int () with base 10 : '0.00' >>>
int的总结 当用int对浮点数进行转型的时候,会截断(truncate)小数部分 如果对小数字符串进行int转型会报错 数据结构 序列(sequence) 查看一个对象是不是序列
1 isinstance ([], collections.Sequence)
list list是一个动态数组
cpython中的实现
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 typedef struct { PyObject_VAR_HEAD PyObject **ob_item; Py_ssize_t allocated; } PyListObject;
参考文献 (参考译文 )stackoverflow参考文献
insert的时候需要移动数组的指针,平均之间复杂度为O(n)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 static int ins1(PyListObject *self, Py_ssize_t where, PyObject *v) { Py_ssize_t i, n = Py_SIZE(self); PyObject **items; if (v == NULL ) { PyErr_BadInternalCall(); return -1 ; } if (n == PY_SSIZE_T_MAX) { PyErr_SetString(PyExc_OverflowError, "cannot add more objects to list" ); return -1 ; } if (list_resize(self, n+1 ) < 0 ) return -1 ; if (where < 0 ) { where += n; if (where < 0 ) where = 0 ; } if (where > n) where = n; items = self->ob_item; for (i = n; --i >= where; ) items[i+1 ] = items[i]; Py_INCREF(v); items[where] = v; return 0 ; }
set 集合的交并补 参考文献
str 字符串的reverse
@property 参考文献
filter 选出满足条件的对象
1 filter (function, iterable)
例子 基本应用 从列表中选出满足特定条件的元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 exampleList = ["aaa.jpg" , "bbb" , "ccc" ] filter (lambda x: ".jpg" in x, exampleList)dir (filter )[i for i in filter (lambda x: ".jpg" in x, exampleList)]
综合应用举例 连续爬取图片的时候,下载图片合并成pdf之后,删除上一次爬虫生成的图片
1 2 3 4 5 6 7 8 9 10 11 import osif __name__ == '__main__' : for savePath in ["comments" , "papers" ]: for f in filter (lambda x: '.jpg' in x, os.listdir(os.path.join("resources" , "2020" , savePath))): file_path = os.path.join("resources" , "2020" , savePath, f) os.remove(file_path)
print %s的妙用\的)logging 常用日志设置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 rootLogger = logging.getLogger(__name__) LOGGINGLEVEL = logging.DEBUG rootLogger.setLevel(LOGGINGLEVEL) logFormatter = logging.Formatter(' [%(levelname)s] %(asctime)s - %(pathname)s[line:%(lineno)d]: %(message)s' ) if not os.path.exists(os.path.join(RESOURCESPATH,'log' )): os.makedirs(os.path.join(RESOURCESPATH,'log' )) fileHandler = logging.FileHandler(os.path.join(RESOURCESPATH,'log' , 'mqRun.log' ), encoding='utf-8' ) fileHandler.setFormatter(logFormatter) fileHandler.setLevel(LOGGINGLEVEL) rootLogger.addHandler(fileHandler) consoleHandler = logging.StreamHandler() consoleHandler.setFormatter(logFormatter) consoleHandler.setLevel(LOGGINGLEVEL) rootLogger.addHandler(consoleHandler)
datetime,time pickle-序列化与反序列化 导入 1 2 with open (os.path.join(DATAPATH,"full_music_data.pkl" ),"rb" ) as f: fullMusicData = pickle.load(f)
导出 TODO
非常好用的自动化测试框架
json json字段和python中字段的对应关系
参考文献
dict dict多属性排序 1 2 3 4 5 >>> a = {1 :[1 ,2 ,3 ],2 :[1 ,1 ,3 ],3 :[1 ,2 ,3 ],4 :[1 ,2 ,1 ]}>>> dict (sorted (a.items(), key=lambda x: (x[1 ][0 ], x[1 ][1 ], x[1 ][2 ]))){2 : [1 , 1 , 3 ], 4 : [1 , 2 , 1 ], 1 : [1 , 2 , 3 ], 3 : [1 , 2 , 3 ]}
dict
list
并且得到最小的id 1 2 from operator import itemgettermin (enumerate (a), key=itemgetter(1 ))[0 ]
参考文献
得到key的index 1 2 3 4 keys=i.keys() keys.index(key)
参考文献
多线程 线程锁 lock和rlock的区别 lock可以在一个线程上锁,在另一个线程解锁
rlock只能在上锁的线程解锁,并且可重入参考文献
sleep 只会阻塞该线程
参考文献 参考文献
re 正则表达式测试网址
开启.匹配换行符 添加参数re.DOTALL
1 pattern = re.compile (r".*?---(.*)---" ,re.DOTALL)
关于re.DOTALL和re.M混合使用导致前者失效 $\mho$(TODO)
替换的时候使用匹配到的字符串 bug 当要匹配的内容中存在\U的内容时,会出现问题
比如
1 "C:\Users\%username%\AppData\Roaming\Code\User"
会报错
1 re.error: bad escape \U at position 374 (line 27, column 7)
解决方法 TODO
问号的用处 非贪婪匹配 前瞻后顾 前瞻: exp1(?=exp2) 查找exp2前面的exp1
后顾: (?<=exp2)exp1 查找exp2后面的exp1
负前瞻: exp1(?!exp2) 查找后面不是exp2的exp1
负后顾: (?<!exp2)exp1 查找前面不是exp2的exp1
举个负后顾的例子 在做笔记的时候,把所有的「奈奎斯特」都少打了「奈」变成了「奎斯特」,这时候需要将所有的「奎斯特」替换成「奈奎斯特」该怎么做呢?
如在vscode中
图片详情 修改批改符号 将\checkmark改为\color{green}{\checkmark}
(?<!\\color\{green\}\{)\\checkmark
\color{green}{\checkmark}
不捕获分组 参考文献
举个例子 图片详情 图片详情 找到第一个不为某个值的位置在字符串中 参考文献
search 和 match的区别 pattern = re.compile(r"^[-]?[1]?\d{1,3}(.\d{0,2})?$")
$\color{red}{\text{Q}}$: 像上面那样写还有区别吗
参考文献
限定符 使用前面匹配到的结果 $1 -> \1
参考文献
包管理 pip 查看pip版本
annaconda pymongo mongodb是非常常用的非关系型数据库之一,python中常用pymongo对mongdb数据库进行操作
数据库连接 数据库库连接的url和官方的mongodb compass可视化软件一致
1 dbs = pymongo.MongoClient("mongodb://user:pass@ip/database" )
创建db和集合 docker容器数据的备份 参考文献
参考文献
flask flask的源码解读 参考文献
flask中的蓝图 参考文献
pycharm 快捷键 run unitest 而不是 run main 参考文献
断点异常 debug的时候明明没有断点的地方确断点了,或者断点没有阻塞运行:重启pycharm
Details 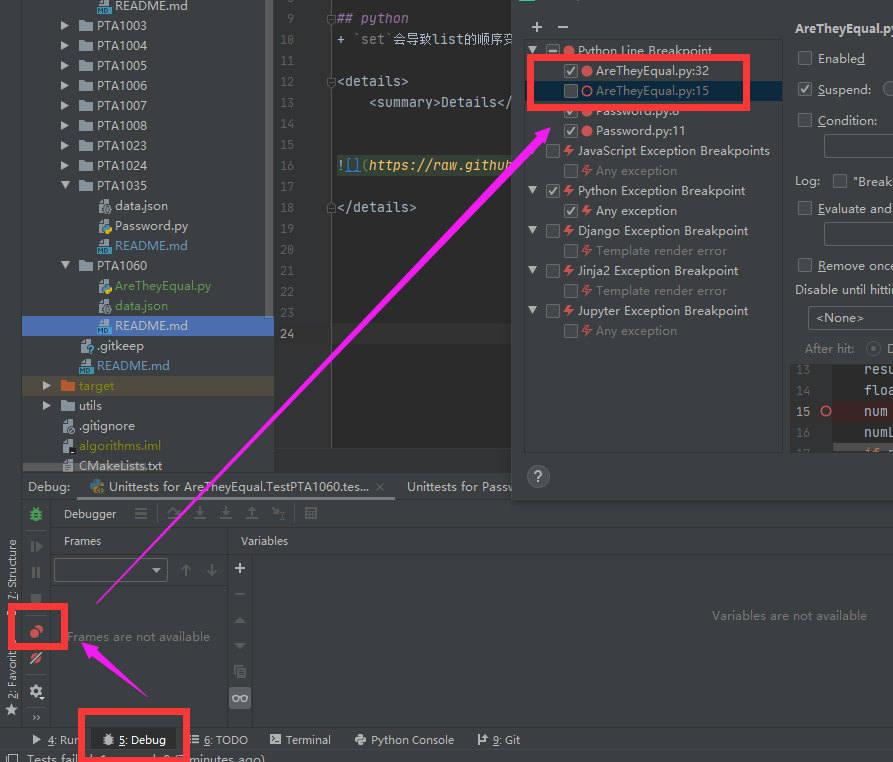关闭和开启兼容性检查 Details 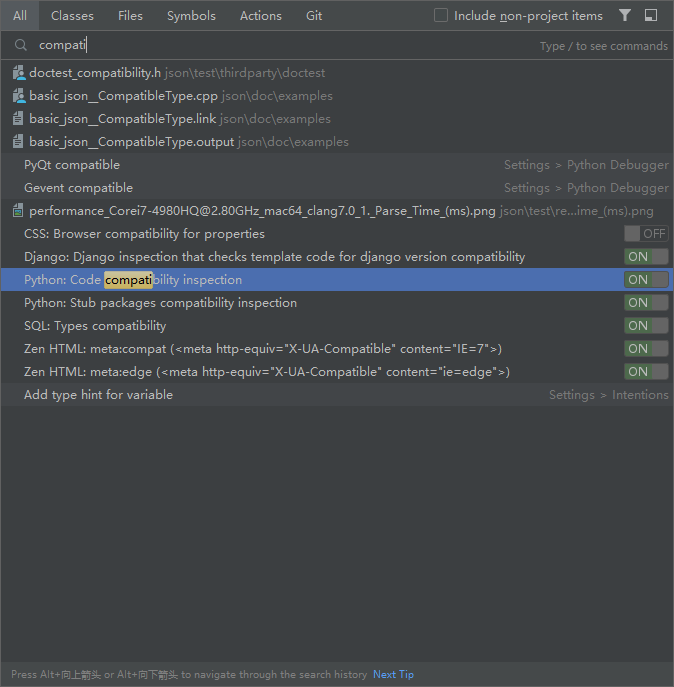性能分析工具profile 参考文献
memory_profile
memory_profile
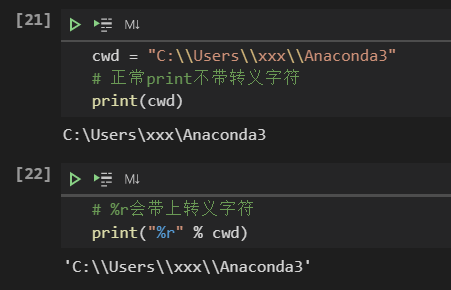
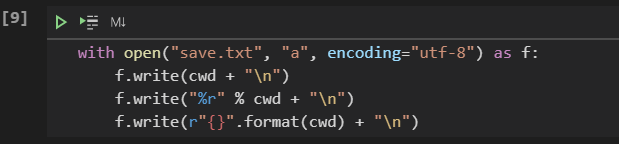
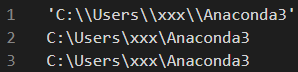
Q & A 得到当前路径 os.getcwd()
参考文献
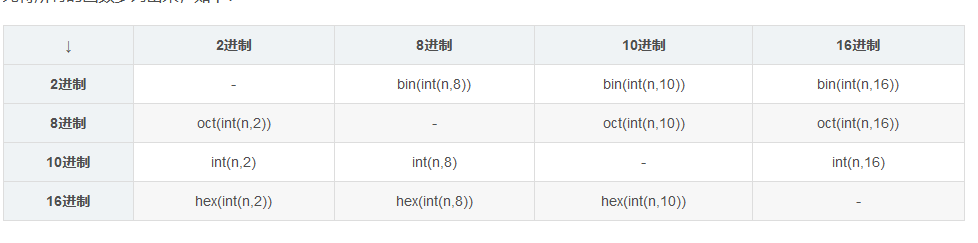
进制转换 进制转换 [参考文献](https://blog.csdn.net/weixin_43353539/article/details/89444838) ## 只格式化部分字符串 [参考文献](https://stackoverflow.com/questions/11283961/partial-string-formatting) ## Traceback ## 一次读多个string
代码详情 1 '\n' .join(iter (input , sentinel))
参考文献
好像不行 图片详情 自定义Exception 参考文献
内部typing 参考文献
append 和 +的区别 参考文献
重定向输入输出 重定向输入 将输入重定向为字符串
1 2 3 4 5 6 7 8 from io import StringIOimport sysf = StringIO('1111\n22' ) sys.stdin = f string = input () print(string)
参考文献
重定向输出 1 2 3 4 5 6 7 from io import StringIOimport sysf = StringIO() sys.stdout = f print("1111" ) f.getvalue()
zen of python 为什么要加密
参考文献
一行有趣的lambda代码 nb_children = lambda node: sum(nb_children(child) for child in children(node)) + 1
用lambda函数进行递归,求一颗树中节点的个数
参考文献
一份合理的工程结构
这种工程结构在pythcharm中是能够在同级目录下导入模块
但下面这个不行
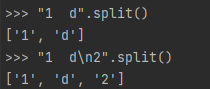
字符串的split函数 如果不带参数的话,默认会把非空字符当作sep
统一改变list的数据类型 map(int, list)可以将字符串统一改成int类型
sort默认是升序 交替穿插两个等长的list 法1 解释:参考文献
法2 1 2 3 4 5 6 7 8 9 10 11 12 13 >>> list1 = ['f' , 'o' , 'o' ]>>> list2 = ['hello' , 'world' ]>>> result = [None ]*(len (list1)+len (list2))>>> result[::2 ] = list1>>> result[1 ::2 ] = list2>>> result['f' , 'hello' , 'o' , 'world' , 'o' ]
参考文献
reduce和sum的区别 参考文献
字符串的split函数 如果不带参数的话,默认会把非空字符当作sep
统一改变list的数据类型 map(int, list)可以将字符串统一改成int类型
sort默认是升序 交替穿插两个等长的list 法1 解释:参考文献
法2 1 2 3 4 5 6 7 8 9 10 11 12 13 >>> list1 = ['f' , 'o' , 'o' ]>>> list2 = ['hello' , 'world' ]>>> result = [None ]*(len (list1)+len (list2))>>> result[::2 ] = list1>>> result[1 ::2 ] = list2>>> result['f' , 'hello' , 'o' , 'world' , 'o' ]
参考文献
reduce和sum的区别 参考文献
misc python包去重
Details 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 string = """#include <iostream> #include <cstdio> #include <string> #include <vector> #include <deque> #include <list> #include <map> #include <iostream> #include <cstdio> #include <string> #include <vector> #include <deque> #include <list> #include <map> #include <iostream> #include <cstdio> #include <string> #include <vector> #include <deque> #include <list> #include <iostream> #include <cstdio> #include <cstring> #include <string> #include <vector> #include <deque> #include <list> #include <algorithm> #include <string.h> #include <stack> #include <stdio.h> #include <iostream> #include <cstdio> #include <string> #include <vector> #include <deque> #include <cstring> #include <list>""" package = string.split("\n" ) print("\n" .join(list (set (package))))
通过内存地址访问变量 参考文献
参考文献
sys.stderr 比 sys.stdin输出的优先级更高?
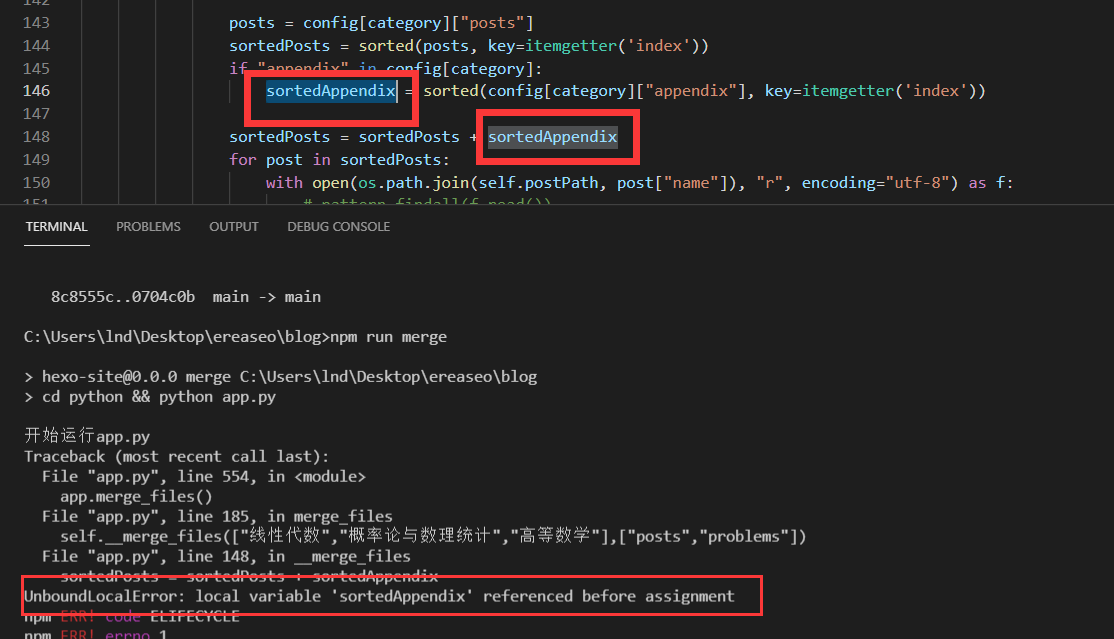
奇异的bug UnboundLocalError: local variable 'sortedAppendix' referenced before assignment
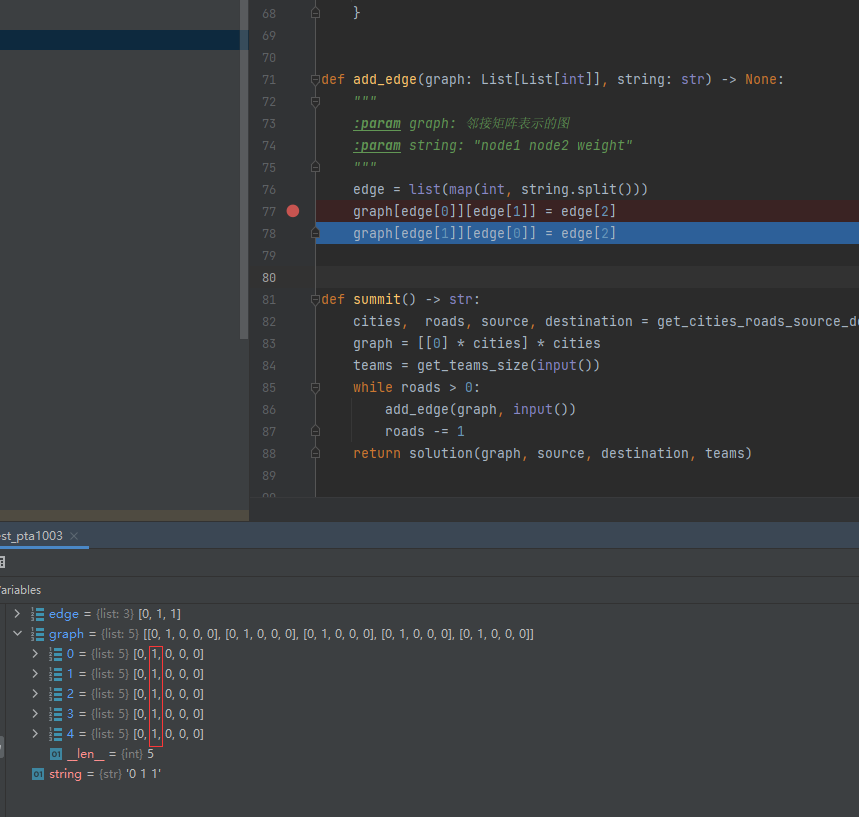
只改了一个元素,一列都变了? bug代码
[[0] * cities] * cities 会创建索引相同的五个list
参考文献
raw string 参考文献
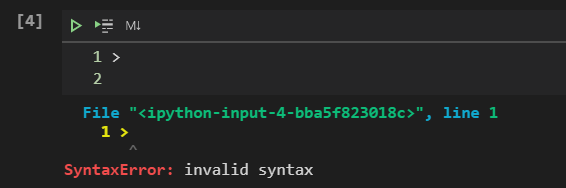
小括号的妙用 简单应用 如果直接运行
会报错
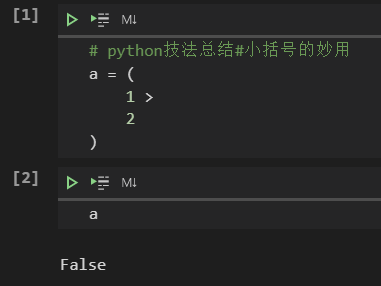
但如果这样子写
python解释器就能正确解释
综合应用举例 使用pyecharts画图的时候,灵活运用小括号,可以是代码简洁,增强阅读性
1 2 3 list (combinations([1 ,2 ,3 ],2 ))
stringIO 参考文献
通过字符串获取方法 getattr(object, name[, default])
参考文献
通过字符串导包 参考文献
exec表达式 参考文献
python 每n个字符串为一组 参考文献
在list中找出第一个不为0的下表 参考文献
python中的等于赋值 参考文献
打印错误日志 参考文献1 参考文献2
打包自己的库并安装 官方文档
list是线程安全的 参考文献
线程池 参考文献
python读取截切板中的图片为二进制 Python可以通过第三方库来读取剪贴板中的内容,但是需要注意的是,不同的操作系统可能需要使用不同的库。对于图片,我们可以使用Pillow库来处理图片,然后将其转换为二进制。
如果你在Windows系统中,可以使用clipboard和Pillow库来读取剪贴板中的图片并转换为二进制。首先,你需要安装这些库,可以使用pip来安装:
1 pip install clipboard Pillow
然后,你可以使用以下代码来读取剪贴板中的图片并转换为二进制:
1 2 3 4 5 6 7 8 9 10 11 import ioimport clipboardfrom PIL import Imageimage = clipboard.paste_as_image() binary_image = io.BytesIO() image.save(binary_image, format ='PNG' ) binary_image = binary_image.getvalue()
如果你在Mac或Linux系统中,可以使用xclip和Pillow库来读取剪贴板中的图片并转换为二进制。首先,你需要安装这些库,可以使用pip和apt来安装:
1 2 pip install Pillow sudo apt-get install xclip
然后,你可以使用以下代码来读取剪贴板中的图片并转换为二进制:
1 2 3 4 5 6 7 8 9 10 11 12 13 import ioimport subprocessfrom PIL import Imagecommand = "xclip -selection clipboard -t image/png -o" image = subprocess.check_output(command.split(), shell=False ) image = Image.open (io.BytesIO(image)) binary_image = io.BytesIO() image.save(binary_image, format ='PNG' ) binary_image = binary_image.getvalue()
注意:这些代码可能不会在所有环境中都能正常工作,因为它们依赖于特定的操作系统功能和第三方库。如果你遇到问题,可能需要根据你的具体环境进行调整。
ORM 框架:SQLAlchemy 选择最大值,并且附带其他条件 代码详情 1 2 3 4 5 from sqlalchemy import desc qry = session.query(Data).filter( Data.user_id == user_id).order_by( desc(Data.counter).limit(1)
参考文献
python文件 pyi Python 的存根文件,用于代码检查时的类型提示。
常用的 IDE 都会有类型检查提示功能,比如在 PyCharm 中,当我们给一个函数传入一个错误的类型时会给出对应的提示,这其实不是 IDE 的特殊开发的功能,它只是集成了PEP484的规定,利用了已经预先生成好的 pyi文件。
参考文献 详解Python相关文件常见的后缀名
详解Python文件: .py、.ipynb、.pyi、.pyc、.pyd