目的
总结一些常用的库
常用术语
金融风控指标:WOE, IV, KS,LIFT值和PSI
数据仓库的分层概念
https://blog.csdn.net/pmdream/article/details/113601956
EDA
数据可视化
python可视化的包非常的多各有特点
与pandas无缝结合的seaborn
与matlab一致体验的matplotlib
中文支持绝好支持js扩展的pyecharts
模型
机器学习
scikit-learn:python传统机器学习库
pycaret:自动训练模型神器
新建一个环境终于装上了
深度学习
pytorch:科研领域最流行的深度学习框架
复杂网络
igraph:复杂网络研究框架
常用工具
包管理
笔记本
pyecharts
优点
- pyechart可以解决seaborn,matplotlib中词云中文需要配很久环境的问题(特别是linux下)
- tooltipopts的提示框可以显示更多的内容
- 优秀的交互性和动画
缺点
- 文档有点奇奇怪怪
- 网上的解决方案不多
使用总结
前期数据分析用,或者需要大量交互性数据查看的时候,特别是数据中存在中文的情况
pyecharts文档
常用图例
配合文档食用更佳
graph_with_catagroies
scatter
简单使用
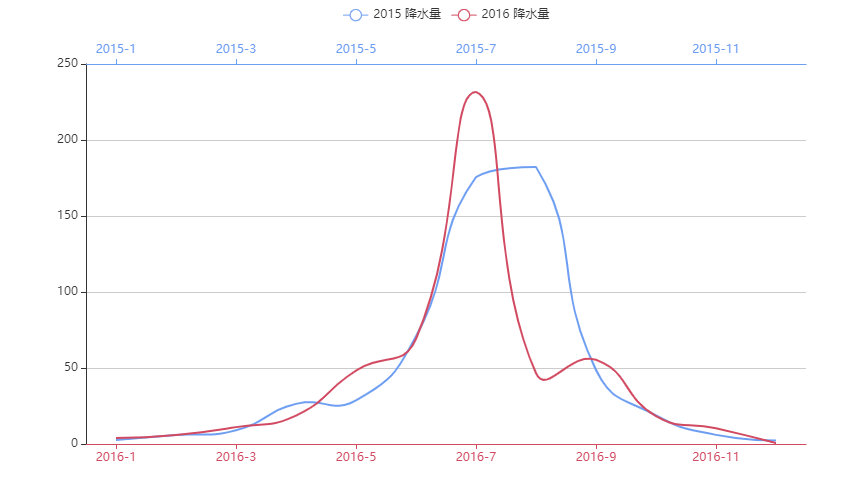
由于tooltip的优秀性,在处理大文本的时候,可以做到非常优秀的可视化,及其方便了EDA
详细代码
1 | from pyecharts.charts import Scatter |
line
高级应用
多x轴
- 效果

bar
wordCloud
简单使用
详细代码
1 | import jieba |
效果
geo
中国和世界支持的较好,有一部分国家的选项
原生支持的地图选项(maptype)在pyecharts.datasets.map_filenames.json文件中
seaborn
优点
- 与pandas数据无缝结合,方便高效
缺点
- 中文支持差
常用API
iris数据集
我们以常用的iris数据集做例子
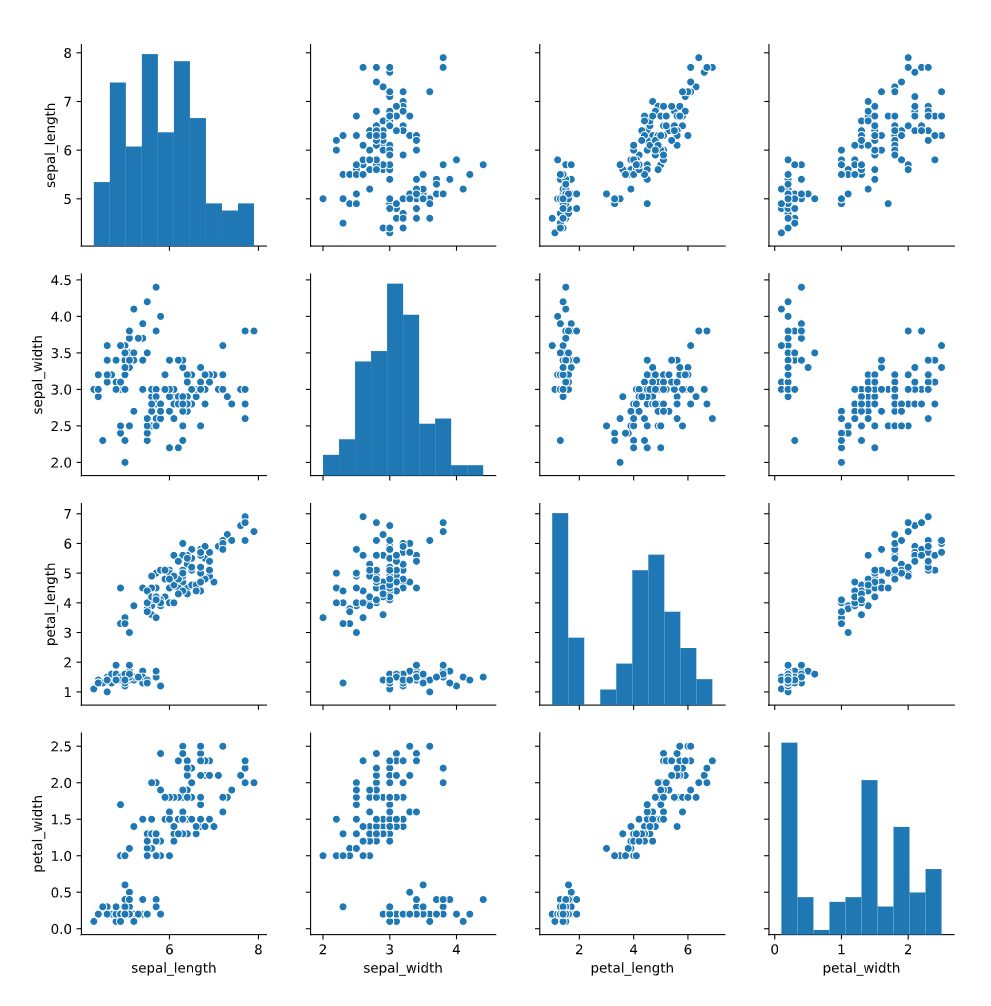
pairplot
很好的将数据的分布和相关性都画在了一个图上
1 | sns.pairplot(data=iris) |
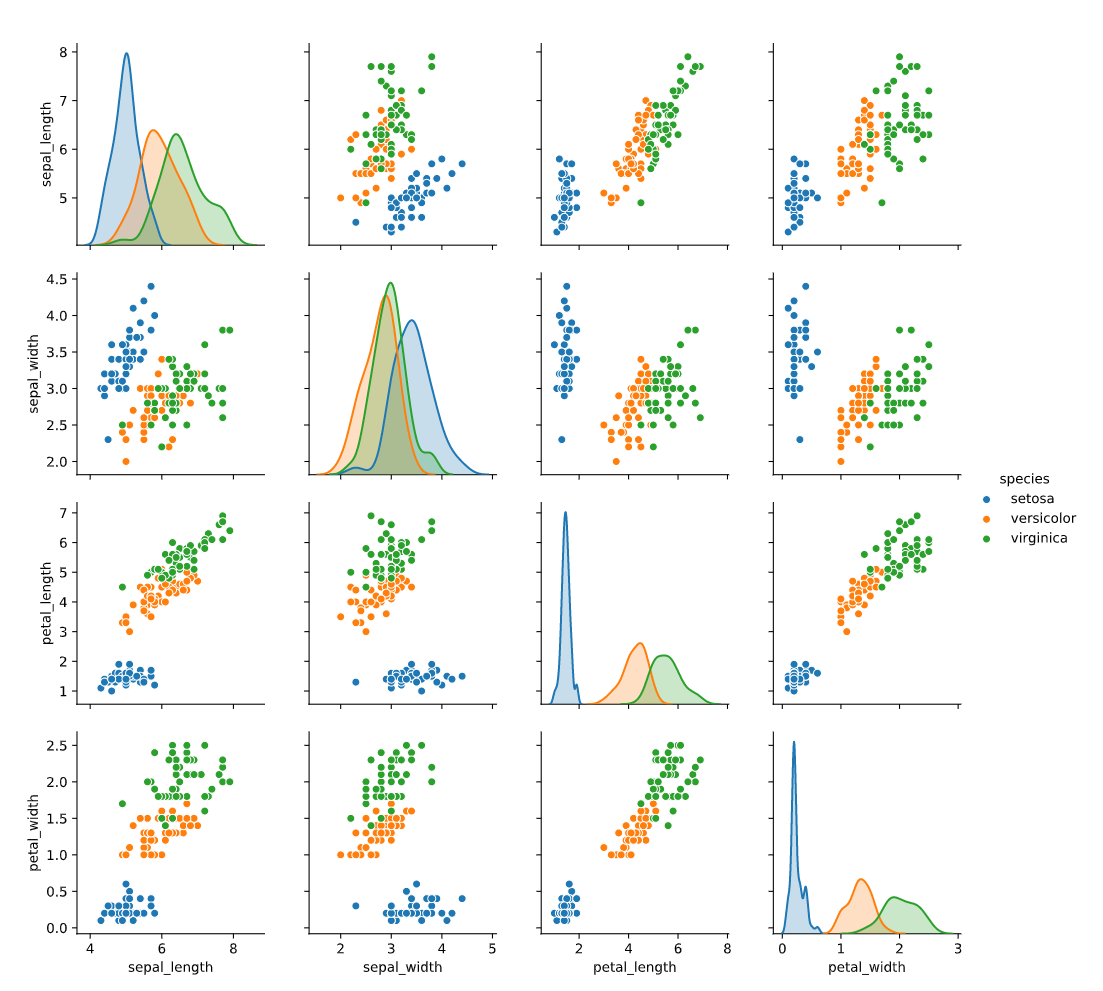
为了看清楚每个类别的区别,我们可以用hue来进行划分
1 | sns.pairplot(data=iris,hue="species") |
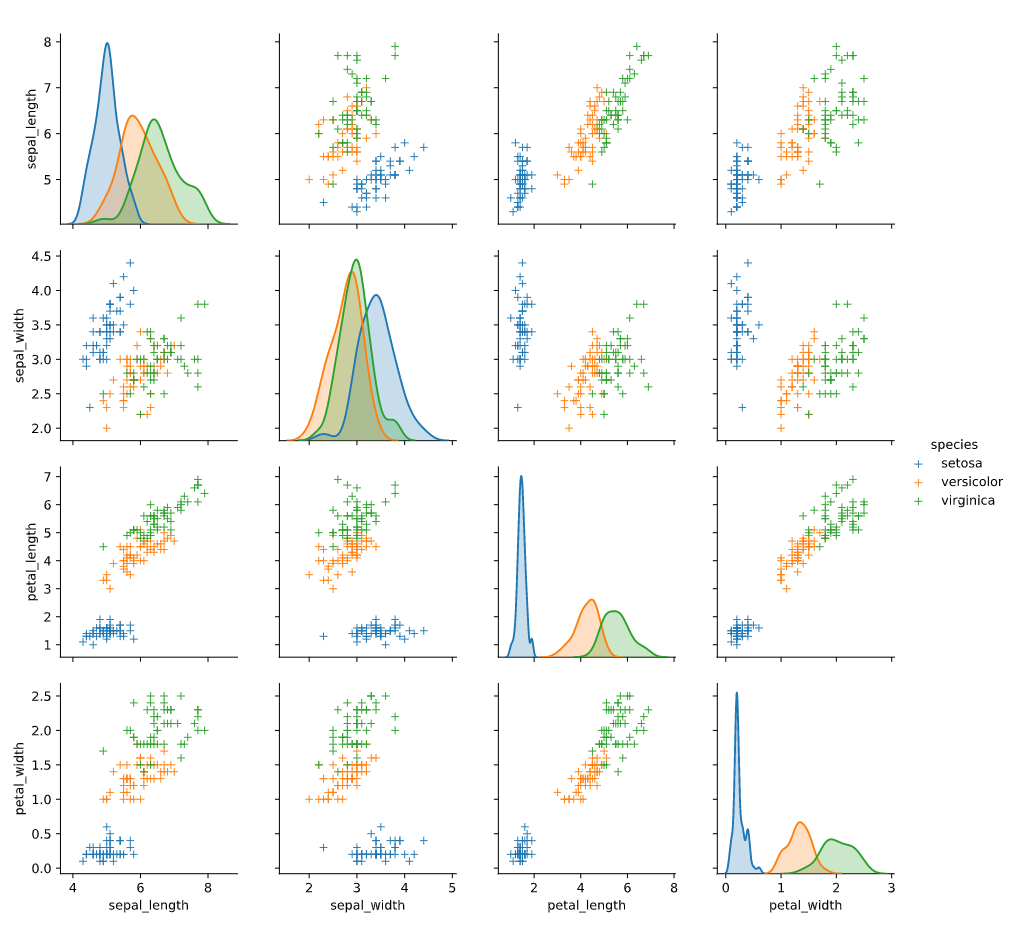
我们也可以修改一下marker让其更有学术气息,marker的种类与matplotlib一致
1 | sns.pairplot(data=iris,hue="species",markers="+") |
relplot
关系图
lmplot
用来进行回归分析
matplotlib
优点
- 传统的画图库,网上有很多解决方案
- 与matlab的api相当一致,对传统matlab党友好
缺点
- 中文支持差
两种模式
- 面对对象
- 函数式
常用API
marker的种类
scatter
plot
pandas
简介
pandas用来处理表格型数据十分的方便
导入
1 | import pandas as pd |
常用API
对表格数据概览
describe:描述数据分布
会对表格中每一列数值型数据的分布做一个展示,例如数据条数,均值,标准差,最大最小值,1/2,1/4,3/4分位点的数据。经常用来查看数值型数据大致分布。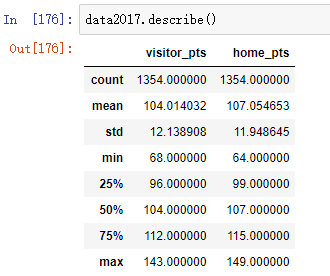
info:显示基本信息
列出所有列的类型是什么,有没有非空数据,以及数据条数,还有内存占用等。一般用来查看数据的类型,有没有非空的数据。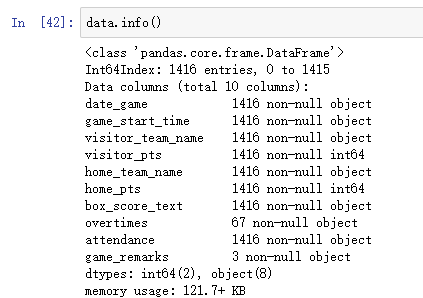
head: 预览前几个数据
看一下数据的前几条数据,经常用来直观的感受一下数据的样子。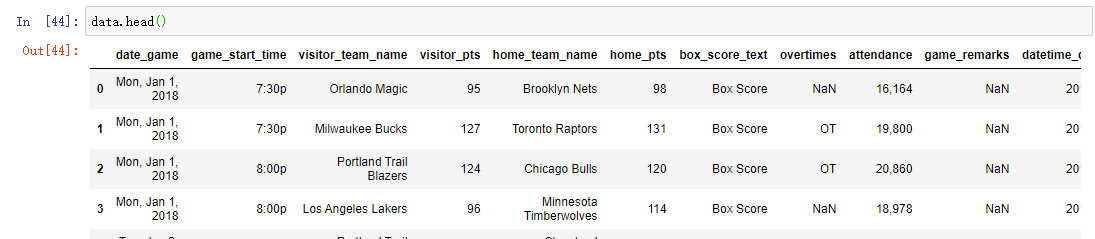
read_xxx: 读入表格
1 | # 读入resources文件夹下,用year变量拼接的excel文件 |
to_xxx: 写出表格
有的时候直接pd导出,会自己带上索引列(未处理过应该是递增的数字),如果不想输出的时候带有index的话,可以带上如下参数
1 | # 设置index = None |
支持导出的类型
- markdown
- latex
- csv
- excel
- clipboard
- …
创建表格:从array中
1 | numpy_data = np.array([[1, 2], [3, 4]]) |
创建表格通过dict
1 | pd.DataFrame(d.items(), columns=['Date', 'DateValue']) |
Create a Pandas DataFrame from List of Dicts
1 | # Initialise data to lists. |
合并表格
反选columns
1 | sns.pairplot(data=fullMusicPklData.loc[:, ~fullMusicPklData.columns.isin(['b'])], corner=True, hue="genre") |
删掉第一列
sample: 数据采样
有时候需要先用少量数据进行测试,这时候需要采样一部分数据,可以使用内置函数sample
函数原型

reset index after concat
1 | artistAllinOne.reset_index(drop=True) |
按照index排序
1 | df.sort_index(inplace=True) |
使用举例
1 | # 采样10个 |
unique: pandas 中的set操作
对于标称属性,有时候想得到所有种类,这时候就需要使用unique
1 | # 得到`工作`列的总类 |
to_dict
将pandas转为list,方便导入pyecharts画图
1 | df.to_dict('records') |
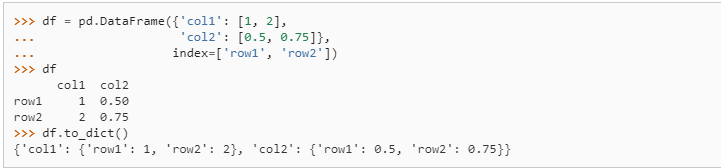

one column as key one column as value to python dict pandas
1 | df.set_index('id')['value'].to_dict() |
nan
选出存在nan的元素
按行遍历
1 | for index, row in df.iterrows(): |
columns重命名
1 | linkFrame.columns = ["name","symbolSize"] |
上面的代码会报错
1 | outdatas = influenceData.groupby(["influencer_main_genre","influencer_id"]).agg('count') |
求1/4,3/4,1/2分位点
1 | data.price.quantile([0.25,0.5,0.75]) |
columns和index翻转
1 | df.T |
多级index,drop掉一级
1 | df.reset_index(level=2, drop=True) |
merge by index
1 | pd.concat([df1, df2], axis=1) |
绝技: map,apply,groupby,agg
在数据仓库与数据挖掘的课中,我们学过数据的属性可以分为四类
基本四种属性分类
| 类别 | 含义 | 举例 |
|---|---|---|
| 标称属性 | 与名称有关,值是一些符号或事物的名称。每个值代表某种类别、编码或状态。 | Occupation={教师,医生,程序员,农民} |
| 二元属性 | 二元属性是一种标称属性,只有两个类别或状态的标称属性(0 and 1),又称布尔属性 | 性别 |
| 序数属性 | 其可能的值之间具有有意义的序或秩评定(ranking),但是相继值之间的差是未知的。 | Professional_rank:助教、讲师、副教授、教授 |
| 数值属性 | 定量,即它是可度量的量,用整数或实数值表示。数值属性可以是区间标度的或比率标度的。 | 区间标度属性:属性用相等的单位尺度度量。值有序,可比较和定量评估值之间的差。如室外温度差,日期差等。没有真正的零点,即不能用比率讨论这些值。如摄氏温度和华氏温度都没有真正的零点,即0°C和0°F都不表示“没有温度”,可以计算温度差,但不可以计算倍数。 比率标度属性:具有固有零点的数值属性。即可以说一个值是另一个的倍数(比率)。开氏温度、度量重量、高度、速度和货币量(100美元比1美元富有100倍)的属性 |
pandas预处理绝技
pandas数据预处理特别是四类基础数据有着非常方便的函数map,apply,以及聚合处理函数groupby,agg
apply
map
agg
综合应用举例
新增count列
1 | influenceData['influence_follower_id_count'] = influenceData.groupby('influencer_id')['follower_id'].transform('count') |
生成箱型图表格
时间序列:datetime
时间序列是非常重要的数据属性,很多时候得到的数据的时间序列的类型实际上字符串类型,特别是自己通过爬虫获取到的数据,这时候首先需要将其转换为datetime数据,还有的时候需要进行时区转换,当使用的是mongdb数据库默认是格林尼治时间,需要转换为相应的当地时间才能操作
时间序列预处理
字符串转为datetime
1 | # 字符串格式为:'Sat, Dec 9, 2017' |
时区转换
当使用的是mongdb数据库默认是格林尼治时间,需要转换为相应的北京时间才是正确的时间数据
1 | import pytz |
时间序列的筛选
对于时间序列的操作pandas有着非常优秀的函数,如
1 | # datetime是时间序列数据列 |
有的时候我们需要选出某个区间内的数据,可以进行如下的操作
1 | import datetime |
sklearn
我们仍然使用iris数据集做例子
多分类
模型评价
中心化和标准化的区别
归一化
基本的归一化方法
非线性归一化
conda
强大的包和环境管理工具
查看当前环境
conda env list
新建环境
conda create --name yourenvname python=3.6
删除环境
conda remove -n thepycaret --all
jupyternotebook
尽管jupyterLab作为下一代jupyternotebook,已经具有调试功能,但我还是选择jupyter notebook(web) + pycharm(调试)。因jupyter notebook中的Nbextensions插件的toc模块真的让人爱不释手,当代码量(cell 的数量)多起来的时候方便管。
jupyterLab我就不做评测了(其实是因为没有用过),讲讲我的jupyter notebook(web) + pycharm(调试)开发模式的优缺点。
优点
- 强大调试环境,可以debug一个cell,享受整个pycharm python调试系统
- 丰富的jupyter notebook插件生态,如Nbextensions,Qgrid等
- ipython的iframe,直接浏览pdf,html文档
缺点
笔者的pycharm版本为2020.1
- pycharm如果一开始打开jupyer notebook,并之后一直使用pycharm进行编辑的话是没有问题的,但是一旦用网页打开,或者用git同步之后cell之间的顺序就会混乱掉。(尚未解决,猜测删掉pycharm的jupyter notebook的cache可能就没问题了)
- pycharm的jupyter不支持pyecharts的图例的预览,估计是因为pycharm是用java写的,基于chrome内核开发的vscode就可以预览,但与浏览器比还是差强人意。
插件
Qgrid
像excel一样显示表格
代码详情
1 | import qgrid |
常用技巧
在不同的jupyter notebook之间共享变量
在2个jupyter笔记本之间,可以使用%store命令。
在第一个jupyter笔记本中:
1 | data = 'string or data-table to pass' |
在第二个jupyter笔记本中:
1 | %store -r data |
Cell中 Code 和 Markdown的切换
- 在一个cell中(在command模式下)
- 按下 y, 进入Code
- 按下m, 进入Markdown
常用快捷键总结
三种模式
在使用快捷键前,需要了解jupyter notebook 中 cell的三种模式,命令模式,markdown模式,code模式。
- TODO
快捷键总结
- TODO
| 快捷键 | 作用 |
|---|---|
| dd | 删除cell |
| Shift + M | 合并选中的cell |
远程服务
- 创建配置文件:
jupyter notebook --generate-config - cd到配置文件所在目录,一般为
C:\Users\userName\.jupyter\jupyter_notebook_config.py - 设置启动ip:
echo c.NotebookApp.ip = '0.0.0.0' >> jupyter_notebook_config.py - 设置端口:
echo c.NotebookApp.port = 8888 >> jupyter_notebook_config.py - 设置不启动浏览器:
echo c.NotebookApp.open_browser = False >> jupyter_notebook_config.py - 设置可以外部访问:
echo c.NotebookApp.allow_remote_access = True >> jupyter_notebook_config.py
设置密码代码详情
1 | D:\Users\aaaa\.jupyter>jupyter notebook password |
- 设置密码:
echo c.NotebookApp.password = u'12345645645665' >> jupyter_notebook_config.py start /min jupyter notebooknohup jupyter notebook
内网穿透导致无法打开笔记本
代码详情
1 | Traceback (most recent call last): |
关闭系统代理
是的,你可以在 Windows 的命令提示符 (CMD) 或 PowerShell 中使用命令来更改系统代理设置。以下是如何使用命令行关闭系统代理的步骤:
在 CMD 或 PowerShell 中输入以下命令:
1 | reg add "HKCU\Software\Microsoft\Windows\CurrentVersion\Internet Settings" /v ProxyEnable /t REG_DWORD /d 0 /f |
这条命令会关闭系统代理。如果你想再次开启系统代理,你可以使用以下命令:
1 | reg add "HKCU\Software\Microsoft\Windows\CurrentVersion\Internet Settings" /v ProxyEnable /t REG_DWORD /d 1 /f |
这些命令会修改注册表中的值,这样就可以更改系统代理设置。但是请注意,修改注册表可能会影响系统的其他部分,所以在执行这些操作时要小心。
此外,这些命令并不会影响 Clash 本身的设置,只会更改系统是否使用代理。如果 Clash 仍在运行,它可能会再次更改这些设置。如果你想完全停止使用 Clash,你可能需要先关闭 Clash。
如何将jupyter注册成windows的服务
要将Jupyter Notebook注册为Windows服务,你可以使用nssm (非官方的“非凡服务管理器”)。nssm是一个允许你管理和创建Windows服务的工具。以下是一些步骤,你可以根据这些步骤操作:
下载并安装
nssm。你可以从这里下载。打开命令提示符(CMD)并导航到
nssm.exe的目录。使用以下命令创建一个新的服务,将“YourServiceName”替换为你想要的服务名称,将“YourPathToJupyter-notebook.exe”替换为你的
jupyter-notebook.exe的完整路径,将”YourNotebookDirectory”替换为你的笔记本目录:1
nssm install YourServiceName "YourPathToJupyter-notebook.exe" "--notebook-dir=YourNotebookDirectory --no-browser"
例如:
1
nssm install JupyterService "C:\Users\Username\Anaconda3\Scripts\jupyter-notebook.exe" "--notebook-dir=C:\Users\Username\Documents\JupyterNotebooks --no-browser"
nssm install JupyterService3 “D:\Users\LND\anaconda3\Scripts\jupyter.exe” “–notebook-dir=C:\Users\Username\Documents\JupyterNotebooks –no-browser”
你可以使用以下命令启动你的服务:
1
nssm start YourServiceName
如果你想停止你的服务,你可以使用以下命令:
1
nssm stop YourServiceName
请注意,这个过程需要管理员权限。如果你在执行这些命令时遇到问题,尝试以管理员身份运行命令提示符。
另外,这个服务默认是手动启动的,如果你想让它在启动时自动运行,你需要更改服务的启动类型。你可以在服务管理器中做到这一点,或者在创建服务时使用nssm set YourServiceName Start SERVICE_AUTO_START命令。
希望这个解答对你有所帮助!如果你有其他问题,欢迎提问。
jupyter显示所有的环境
conda activate adda
python -m ipykernel install --name adda
igraph
官方文档
常用API
计算节点的中心度
1 | g.betweenness |
生成有向图
默认是无向图,如果想生成有向图,需要制定directed = True
1 | g = igraph.Graph([(0,1), (0,2), (2,3), (3,4), (4,2), (2,5), (5,0), (6,3), (5,6)],directed = True) |
计算图中的节点总数
1 | g.vcount() |
复杂网络聚类模型
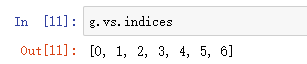
得到所有的index
1 | g.vs.indices |
更优雅的生成图
TODO:把美赛的代码拿过来
1 | import igraph |